





一、Permission denied
1、Win系统下用Eclipse中运行远程hadoop MapReduce程序出现报错
org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security.AccessControlException: Permission denied: user=xxx, access=WRITE, inode="xxx":xxx:supergroup:rwxr-xr-x
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)解决方法为:
方法一:放开 hadoop 目录的权限 , 命令如下 :$ hadoop fs -chmod -R 777 /
当然,也可以只针对某个目录操作:

如对命令不熟悉,可以直接用如下命令查看:
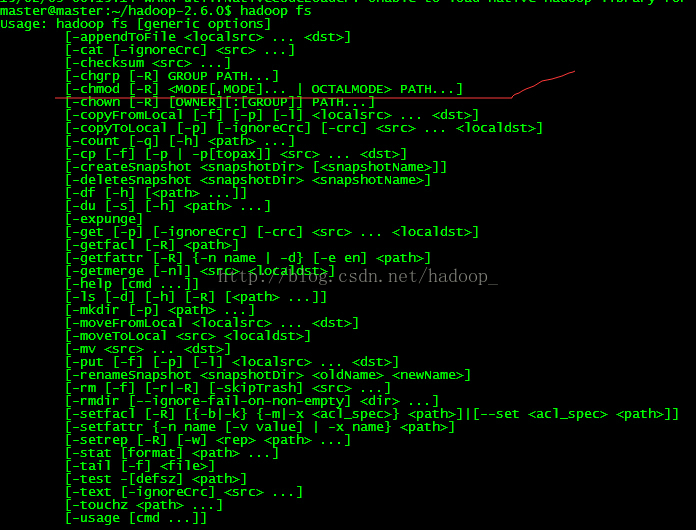
方法二:直接在hdfs的配置文件中,将dfs.permissions修改为False
二、空指针错误:
在我的上篇hadoop2.2.0安装教程中有人遇到空指针错误:“Exception in thread "main" java.lang.NullPointerException”
该错误的修正,需做如下操作:
1、下载hadoop.dll、winutils.exe文件放到eclipse所连接的hadoop的bin目录下(win系统里边);
2、win系统里边的C盘下的system32目录放一份;
3、环境变量的PATH里边加一下1中的bin目录。
三、有人日志打不出来,报警告信息:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.内容为:
# Configure logging for testing: optionally with log file
#log4j.rootLogger=debug,appender
log4j.rootLogger=info,appender
#log4j.rootLogger=error,appender
#\u8F93\u51FA\u5230\u63A7\u5236\u53F0
log4j.appender.appender=org.apache.log4j.ConsoleAppender
#\u6837\u5F0F\u4E3ATTCCLayout
log4j.appender.appender.layout=org.apache.log4j.TTCCLayout
四、自己在eclipse打的jar包放到linux中运行时报错:
Exception in thread "main" java.lang.ClassNotFoundException:后边跟着自定义参数(如目录等)
解决方法:
1、可以重新在eclipse中打包,打包时记得选择main class。
2、另外,可以在打包时选择“Runnable JAR file”,打成java运行jar包。(该种方法会把程序中相关的包都打进去,会比较大,不过可以保证能运行)














 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









