







dictionaryName[key] = value
1. 使用大括号创建字典
student = { “203-2012-002”:“Peter”,“203-2016-024”:“John”}
2. 使用中括号添加字典值
student ["202-2016-125"] = "Sunan"
3. 使用键查询字典中的值
student ["202-2016-125"]
'Sunan'
若输入的键不存在,则返回错误信息
4. 使用 del dictionaryName[key] 删除字典中的值
del student ["202-2016-125"]
5. 使用 for key in dictionaryName:
print (key+":"+str(diationaryName[key])) 通过字典的键遍历字典
字典的遍历:
5.1 遍历字典的键key:for key in dictionaryName.keys():print(key)
5.2 遍历字典的值value:for value in dictionaryName.values():print(value)
5.3 遍历字典的项:for item in dictionaryName.items():print(item)
5.4 遍历字典的key-value:for item,value in adict.items():print(item,value)
6. 使用 in 或者 not in 判断是否一个键在字典中
“202-2016-125” in student
True
“202-2016-120” in student
False
7. 字典的标准操作符:-,<,>,<=,>=,==,!=,and,or,not
d1 = {“red”:41,"blue":3}
d2 = {"blue":3,“red”:41}
True
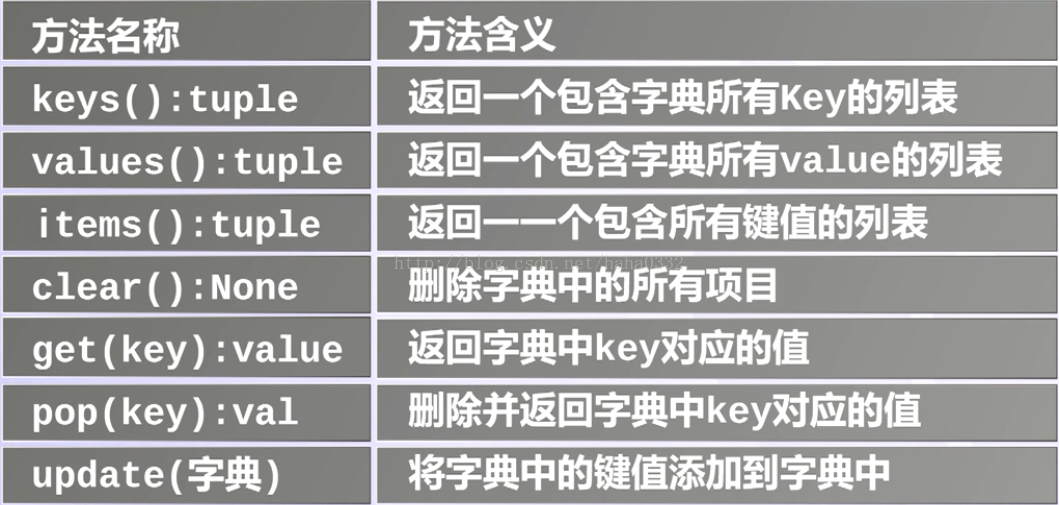
8. 字典中的方法
9. 实例——词频统计
步骤:
(1)输入英文文章
(2)建立用于词频计算的空字典
(3)对文本的每一行计算词频
(4)从字典中获取数据对到列表中
(5)对列表中的数据对交换位置,并从大到小进行排列
(6)输出结果
(7)用Turtle库绘制统计词频结果图表
代码如下:
import turtle
#全局变量
data=[] #单词频率数组—作为y轴数据
words=[] #单词词组—作为x轴数据
yScale=6 #y轴显示放大倍数—可以根据词频数量进行调节
xScale=50 #x轴显示放大倍数—可以根据count数量进行调节
###################### 绘制图像函数组 ####################
#从点(x1,y1)到(x2,y2)绘制线段
def drawLine(t,x1,y1,x2,y2):
t.penup()
t.goto(x1,y1)
t.pendown()
t.goto(x2,y2)
#在坐标(x,y)处写文字
def drawText(t,x,y,text):
t.penup()
t.goto(x,y)
t.pendown()
t.write(text)
#绘制一个柱体
def drawRectangle(t,x,y):
x=x*xScale
y=y*yScale #放大倍数显示
drawLine(t,x-5,0,x-5,y)
drawLine(t,x-5,y,x+5,y)
drawLine(t,x+5,y,x+5,0)
drawLine(t,x+5,0,x-5,0)
#绘制多个柱体
def drawBar(t,count):
for i in range(count):
drawRectangle(t,i+1,data[i])
#完整的统计图绘制
def drawGraph(t,count):
#绘制x/y轴线
drawLine(t,0,0,360,0)
drawLine(t,0,300,0,0)
#x轴:坐标及描述
for x in range(count):
x=x+1 #向右移一位,为了不画在原点上
drawText(t,x*xScale-4,-20,(words[x-1]))
drawText(t,x*xScale-4,data[x-1]*yScale+10,data[x-1])
drawBar(t,count)
###################### 辅助程序 ####################
#对文本的每一行计算词频的函数
def processLine(line,wordCounts):
#空格替换标点符号
line=replacePunctuations(line)
#从每一行获取每个词
words=line.split()
for word in words:
if word in wordCounts:
wordCounts[word]+=1
else:
wordCounts[word]=1
#空格替换标点的函数
def replacePunctuations(line):
for ch in line:
if ch in "~!@#$%^&*()_-+=<>?,./:;{}[]|\'""":
line=line.replace(ch," ")
return line
###################### 主程序 ####################
def main():
#用户输入一个文件名
filename=input("enter a filename:").strip() #strip()函数删除掉开头结尾处的空格
infile=open(filename,"r")
#建立用于计算词频的空字典
wordCounts={}
for line in infile:
processLine(line.lower(),wordCounts) #lower()将所有大写字母变成小写,方便排序
#从字典中获取数据对
pairs=list(wordCounts.items())
#列表中的数据对交换位置,数据对排序
items = [[x,y]for (y,x)in pairs]
items.sort() #sort()函数从小到大排序
count=len(items)
#输出count个数词频结果
for i in range(count - 1, -1, -1):
print(items[i][1]+"\t"+str(items[i][0]))
data.append(items[i][0])
words.append(items[i][1])
infile.close()
#根据词频结果绘制柱状图
turtle.title('词频结果柱状图')
turtle.setup(900,750,0,0)
t=turtle.Turtle() #初始化画笔
t.hideturtle()
t.width(3)
drawGraph(t,count)
#调用main()函数
if __name__=='__main__':
main()
############################################################
enter a filename:111.txt
china 4
is 3
a 3
big 2
country 1















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











