







在开发controller时,用的最多的就是client-go的informer机制。该机制保证了消息的实时性,可靠性、顺序性。
本文结合informer源码,对informer的设计实现进行详细解析。
informer框架设计
首先给出informer机制架构图(图片来自《k8s源码剖析》一书)
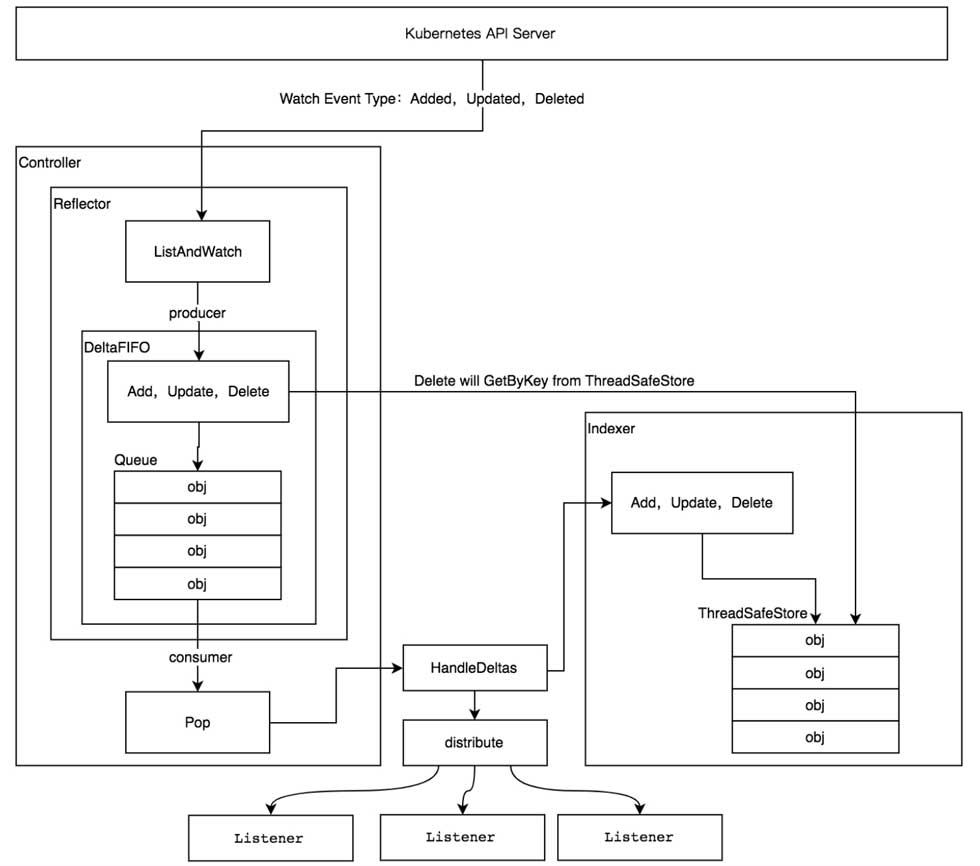
![]()
核心组件
1、reflector
从上图可以看到,reflector与api server直接交互,监听k8s资源,包括全量list,以及watch资源的变化事件,包括增删改。将对象放入deltafifo中。
2、deltafifo
这个是保证事件分类存储和有序处理的组件。组件分为两个功能,FIFO是一个先进先出的有序队列,是queue的实现,因此拥有队列的操作方法,pop,add,update,delete等。delta是一个资源对象的存储,可以保存对象的操作类型,比如add,update,delete,sync等类型。实现是一个map。用map的作用是能够根据key实现时间复杂度为o(1)的查找。
3、indexer
indexer是一个本地缓存,将deltafifo拿出消费的资源对象,存储在indexer中,这样当使用get或者list时,会使用indexer,无需请求api server。
informer在controller开发中的使用
kubeClient, err := kubernetes.NewForConfig(restConfig)
if err != nil {
klog.Fatalf("Error building kubernetes clientset: %s", err.Error())
os.Exit(1)
}
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
![]()
利用informer.NewSharedInformerFactory实例化一个sharedinformer对象,接收两个参数:第一个参数clientset是用于和kubernetes apiserver通信的客户端。第二个参数time.Minute是设置多久进行一次resync。resync会周期性把indexer的所有缓存数据,重新放在deltafifo中进行处理。这里文章后面会详细分析。
deploymentInformer := kubeInformerFactory.Apps().V1().Deployments().Informer()
deploymentInformer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newDepl := new.(*appsv1.Deployment)
oldDepl := old.(*appsv1.Deployment)
if newDepl.ResourceVersion == oldDepl.ResourceVersion {
// Periodic resync will send update events for all known Deployments.
// Two different versions of the same Deployment will always have different RVs.
return
}
controller.handleObject(new)
},
DeleteFunc: controller.handleObject,
})
![]()
kubeInformerFactory是informer的一个工厂。
然后通过kubeInformerFactory.core().V1().Pods().Informer(),可以得到具体pod资源的informer对象。然后通过informer.AddEventHandler为pod资源提供回调函数。
资源informer
每一个k8s资源都实现了informer机制,每个informer上都会实现informer和lister方法。比如
type ConfigMapInformer interface {
Informer() cache.SharedIndexInformer
Lister() v1.ConfigMapLister
}
方法具体如下:
func (f *configMapInformer) Informer() cache.SharedIndexInformer {
return f.factory.InformerFor(&corev1.ConfigMap{}, f.defaultInformer)
}
func (f *configMapInformer) Lister() v1.ConfigMapLister {
return v1.NewConfigMapLister(f.Informer().GetIndexer())
}
![]()
在上面使用informer例子时,我们是kubeInformerFactory.core().V1().Pods().Informer()这样调用的,最后的informer,就是调用的对应资源的informer方法。那么我们看configmap的informer方法,会调用factory.InformerFor的方法。这个方法也就是向sharedinformer注册了自己的informer。
factory.InformerFor参数有两个:第一个是runtime.obj,是填的资源对象的种类,比如configmap。第二个参数是提供资源对象的new informer的函数。configmap填的是f.defaultInformer函数,该函数也在configmap的informer实现中。
func (f *configMapInformer) defaultInformer(client kubernetes.Interface, resyncPeriod time.Duration) cache.SharedIndexInformer {
return NewFilteredConfigMapInformer(client, f.namespace, resyncPeriod, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc}, f.tweakListOptions)
}
func NewFilteredConfigMapInformer(client kubernetes.Interface, namespace string, resyncPeriod time.Duration, indexers cache.Indexers, tweakListOptions internalinterfaces.TweakListOptionsFunc) cache.SharedIndexInformer {
return cache.NewSharedIndexInformer(
&cache.ListWatch{
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.CoreV1().ConfigMaps(namespace).List(options)
},
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.CoreV1().ConfigMaps(namespace).Watch(options)
},
},
&corev1.ConfigMap{},
resyncPeriod,
indexers,
)
}
![]()
可以看到该函数返回的就是一个SharedIndexInformer类型的configmap informer。
sharedinformer:
sharedinformer是可以共享使用的informer,就是同一资源的informer如果被实例化太多次,每个informer都会使用一个reflector,会运行很多的listAndWatch,这样会造成api server压力过大。同时本地的缓存也会过大。
sharedinformer可以让同一类资源informer共享一个reflector,节约资源。
factory.InformerFor:
接下来再来看看factory.InformerFor函数的做了啥,是如何实现sharedinfomer的共享机制的。
k8s.io/client-go/informers/factory.go
func (f *sharedInformerFactory) InformerFor(obj runtime.Object, newFunc internalinterfaces.NewInformerFunc) cache.SharedIndexInformer {
f.lock.Lock()
defer f.lock.Unlock()
informerType := reflect.TypeOf(obj)
informer, exists := f.informers[informerType]
if exists {
return informer
}
resyncPeriod, exists := f.customResync[informerType]
if !exists {
resyncPeriod = f.defaultResync
}
informer = newFunc(f.client, resyncPeriod)
f.informers[informerType] = informer
return informer
}
![]()
当informerFor函数被configmap的informer调用了,会对obj进行类型断言,判断该类型是否已经有informer注册过了,如果注册了,则直接返回该注册过的infromer,如果没有注册过,则调用参数的newFunc对informer进行new,然后保存到informer map中。
注意点:
也就是在controller代码中,我们只有调用了具体的资源的informer方法,或者lister方法,才能实际上将informer实例化并注册到informerFactory。这样才能让informer真正准备启动。在controller后续代码中调用informerFactory.start方法,才能逐一开启每个注册informer。进行list watch。
下述方法是错误的:
rgController := NewController(kubeClient, kubeInformerFactory.Core().V1().ConfigMaps())
![]()
如果不在NewContorller方法里继续调用informer或者lister方法,则不会触发informer的生成和注册。
informer Run(实际运行)
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
eventRecorder := createRecorder(kubeClient, controllerAgentName)
rgController := NewController(kubeClient, kubeInformerFactory.Core().V1().ConfigMaps().Informer)
kubeInformerFactory.Start(stopCh)
![]()
在NewController里使用了各种资源对象的informer。创建好了回调函数等。
就开始使用kubeInformerFactory.Start(stopCh)去正式开启所有注册informer。
start方法如下:
k8s.io/client-go/informers/factory.go
// Start initializes all requested informers.
func (f *sharedInformerFactory) Start(stopCh <-chan struct{}) {
f.lock.Lock()
defer f.lock.Unlock()
for informerType, informer := range f.informers {
if !f.startedInformers[informerType] {
go informer.Run(stopCh)
f.startedInformers[informerType] = true
}
}
}
![]()
遍历informerfactory的informer map,对每个注册的informer,运行其run方法。正式开始运行每个informer。
组件详细解析
接下来介绍informer每个组件的具体实现。最后再介绍informer run方法是如何将这些组件串联在一起的。
Reflector
结构体字段定义
type Reflector struct {
// name identifies this reflector. By default it will be a file:line if possible.
name string
// The name of the type we expect to place in the store. The name
// will be the stringification of expectedGVK if provided, and the
// stringification of expectedType otherwise. It is for display
// only, and should not be used for parsing or comparison.
expectedTypeName string //表示存储的资源名
// The type of object we expect to place in the store.
expectedType reflect.Type
// The GVK of the object we expect to place in the store if unstructured.
expectedGVK *schema.GroupVersionKind
// The destination to sync up with the watch source
store Store //list watch资源后需要同步到的地方,对于informer而言,也就是deltafifo
// listerWatcher is used to perform lists and watches.
listerWatcher ListerWatcher //list watch方法,该方法负责与api server通信
// period controls timing between one watch ending and
// the beginning of the next one.
period time.Duration // 表示上次watch退出后,下次开启watch间隔的周期
resyncPeriod time.Duration //表示同步的周期,这个值就是在controller newInformerFactory时填的参数。
ShouldResync func() bool //该函数是由processor提供的,表示processor中的listener是否有达到需要同步的时间了。其实就是controller里 addEventHander填的同步时间参数。上面两个参数,联合起来才能表示哪些listener(回调函数)在何时可以进行resync了。
// clock allows tests to manipulate time
clock clock.Clock
//上一次resync或者list的时候,资源的resourceversion
lastSyncResourceVersion string
// lastSyncResourceVersionMutex guards read/write access to lastSyncResourceVersion
lastSyncResourceVersionMutex sync.RWMutex
// WatchListPageSize is the requested chunk size of initial and resync watch lists.
// Defaults to pager.PageSize.
WatchListPageSize int64 //WatchListPageSize是init时list和resync监视列表的请求块大小。
}
创建方法
//该函数有4个参数,是创建reflector必需的配置
func NewReflector(lw ListerWatcher, expectedType interface{}, store Store, resyncPeriod time.Duration) *Reflector {
return NewNamedReflector(naming.GetNameFromCallsite(internalPackages...), lw, expectedType, store, resyncPeriod)
}
// NewNamedReflector same as NewReflector, but with a specified name for logging
func NewNamedReflector(name string, lw ListerWatcher, expectedType interface{}, store Store, resyncPeriod time.Duration) *Reflector {
r := &Reflector{
name: name, //表示refletor的名字
listerWatcher: lw, //lw表示reflector使用的list watch方法,这些方法会用于与api server通信。
store: store, //表示reflector获得的数据存储的地方,这里实际上是informer的deltafifo。意味着reflector与deltafifo打交道比较多
period: time.Second, //表示重启list watch的周期,如果上一次watch退出,则过period时间后继续启动list watch
resyncPeriod: resyncPeriod,//resync的周期。就是new factory传入的时间。
clock: &clock.RealClock{},
}
r.setExpectedType(expectedType) // expectType表示何种资源
return r
}
注意, 创建方法中,没有设置ShouldResync参数,这个参数的设置放在最后说。
运行方法Run
// Run starts a watch and handles watch events. Will restart the watch if it is closed.
// Run will exit when stopCh is closed.
func (r *Reflector) Run(stopCh <-chan struct{}) {
klog.V(3).Infof("Starting reflector %v (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
wait.Until(func() {
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.period, stopCh)
}
该方法在wait.until中运行listandwatch。每隔period时间运行listandwatch。保证listwatch一直在运行。
ListAndWatch方法【核心】:
//ListAndWatch首先全量list列出所有对象,并获得其resourceversion,
//然后使用resourceversion进行watch。
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
klog.V(3).Infof("Listing and watching %v from %s", r.expectedTypeName, r.name)
var resourceVersion string
// Explicitly set "0" as resource version - it's fine for the List()
// to be served from cache and potentially be delayed relative to
// etcd contents. Reflector framework will catch up via Watch() eventually.
//对于list,将resourceversion设置为0,表示从etcd拿到所有资源版本。方便作为cache提供服务。
//在lis过程中,可能会慢于etcd更新的内容,这将会从watch机制赶上。
options := metav1.ListOptions{ResourceVersion: "0"}
if err := func() error {
initTrace := trace.New("Reflector ListAndWatch", trace.Field{"name", r.name})
defer initTrace.LogIfLong(10 * time.Second)
var list runtime.Object
var err error
listCh := make(chan struct{}, 1)
panicCh := make(chan interface{}, 1)
go func() {
defer func() {
if r := recover(); r != nil {
panicCh <- r
}
}()
//尝试使用chunk机制进行list。如果listwatcher不支持,则第一次list会返回所有
//这里new了一个pager,传入的是reflector的list方法
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
return r.listerWatcher.List(opts)
}))
//这里的pagesize表示list回来,每一页可以存放多少数据,由于r.WatchListPageSize为空。所以使用的是pager默认的pagesize=500.
if r.WatchListPageSize != 0 {
pager.PageSize = r.WatchListPageSize
}
// Pager falls back to full list if paginated list calls fail due to an "Expired" error.
//通过pager的list方法正式开始list。pager的list方法就是上面new pager传入的reflector的lsit方法。
list, err = pager.List(context.Background(), options)
close(listCh)
}()
select {
case <-stopCh:
return nil
case r := <-panicCh:
panic(r)
case <-listCh:
}
if err != nil {
return fmt.Errorf("%s: Failed to list %v: %v", r.name, r.expectedTypeName, err)
}
initTrace.Step("Objects listed")
listMetaInterface, err := meta.ListAccessor(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v: %v", r.name, list, err)
}
//通过list的数据获得resourceversion
resourceVersion = listMetaInterface.GetResourceVersion()
initTrace.Step("Resource version extracted")
items, err := meta.ExtractList(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v (%v)", r.name, list, err)
}
initTrace.Step("Objects extracted")
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("%s: Unable to sync list result: %v", r.name, err)
}
initTrace.Step("SyncWith done")
//在这里设置list的resourceversion,用于后续watch的起点。
r.setLastSyncResourceVersion(resourceVersion)
initTrace.Step("Resource version updated")
return nil
}(); err != nil {
return err
}
resyncerrc := make(chan error, 1)
cancelCh := make(chan struct{})
defer close(cancelCh)
//接着起了一个go协程,用于resync。
go func() {
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
//resync是否正式开始,由reflector的resync周期以及processor的每个listener的ShouldResync函数是否达到resync时间 决定
if r.ShouldResync == nil || r.ShouldResync() {
klog.V(4).Infof("%s: forcing resync", r.name)
//如果达到了要求,则进行resync
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()
//进入死循环,进行watch
for {
// give the stopCh a chance to stop the loop, even in case of continue statements further down on errors
select {
case <-stopCh:
return nil
default:
}
timeoutSeconds := int64(minWatchTimeout.Seconds() * (rand.Float64() + 1.0))
options = metav1.ListOptions{
ResourceVersion: resourceVersion,
// We want to avoid situations of hanging watchers. Stop any wachers that do not
// receive any events within the timeout window.
TimeoutSeconds: &timeoutSeconds,
// To reduce load on kube-apiserver on watch restarts, you may enable watch bookmarks.
// Reflector doesn't assume bookmarks are returned at all (if the server do not support
// watch bookmarks, it will ignore this field).
AllowWatchBookmarks: true,
}
//调用reflector的watch方法生成一个watch对象
w, err := r.listerWatcher.Watch(options)
if err != nil {
switch err {
case io.EOF:
// watch closed normally
case io.ErrUnexpectedEOF:
klog.V(1).Infof("%s: Watch for %v closed with unexpected EOF: %v", r.name, r.expectedTypeName, err)
default:
utilruntime.HandleError(fmt.Errorf("%s: Failed to watch %v: %v", r.name, r.expectedTypeName, err))
}
// If this is "connection refused" error, it means that most likely apiserver is not responsive.
// It doesn't make sense to re-list all objects because most likely we will be able to restart
// watch where we ended.
// If that's the case wait and resend watch request.
//错误处理,如果错误是连接拒绝,则表示apiserver没有响应了,这种情况下,重新list所有对象就没有意义了,因为我们很可能可以重新开始watch上次结束的位置。因此会等待一秒,然后重新发送watch请求。
if utilnet.IsConnectionRefused(err) {
time.Sleep(time.Second)
continue
}
return nil
}
//进行watch以及watch的处理
if err := r.watchHandler(w, &resourceVersion, resyncerrc, stopCh); err != nil {
if err != errorStopRequested {
switch {
case apierrs.IsResourceExpired(err):
klog.V(4).Infof("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
default:
klog.Warningf("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
}
}
return nil
}
}
}
上述listAndWatch比较长。对整个方法的流程做了一些注解。其中很多细节和调用,我们一一来看。
pager
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
return r.listerWatcher.List(opts)
}))
pager的作用是作为一个分页器,list的数据很大,response需要进行分页展示。结构体如下:
type ListPager struct {
PageSize int64 //每页的大小
PageFn ListPageFunc //接受reflector的list方法
FullListIfExpired bool //如果遇到过期错误,它将返回到完整列表
// Number of pages to buffer
PageBufferSize int32 //page的页数
}
看下listwatch中调用的pager.New方法
k8s.io/client-go/tools/pager/pager.go
func New(fn ListPageFunc) *ListPager {
return &ListPager{
PageSize: defaultPageSize, //默认是500
PageFn: fn,//lsitwatch的list方法
FullListIfExpired: true, //表示如果遇到过期错误,它将返回到完整列表
PageBufferSize: defaultPageBufferSize, //默认是5
}
}
知道pager的作用后,再看来下list方法具体是怎么实现的。
list
options := metav1.ListOptions{ResourceVersion: "0"}
......
// Pager falls back to full list if paginated list calls fail due to an "Expired" error.
list, err = pager.List(context.Background(), options)
close(listCh)
pager的list方法:
//List返回单个List对象,但尝试从服务器检索较小的块以减少对服务器的影响。如果区块尝试失败,它将加载完整列表。
func (p *ListPager) List(ctx context.Context, options metav1.ListOptions) (runtime.Object, error) {
//如果limit没有设置,则用pager的size,也就是500
if options.Limit == 0 {
options.Limit = p.PageSize
}
//这里的值为0
requestedResourceVersion := options.ResourceVersion
var list *metainternalversion.List
//for循环,进行分块传输
for {
select {
case <-ctx.Done():
return nil, ctx.Err()
default:
}
//掉用reflector的list方法。
obj, err := p.PageFn(ctx, options)
if err != nil {
// Only fallback to full list if an "Expired" errors is returned, FullListIfExpired is true, and
// the "Expired" error occurred in page 2 or later (since full list is intended to prevent a pager.List from
// failing when the resource versions is established by the first page request falls out of the compaction
// during the subsequent list requests).
//如果出现错误,且错误不是资源过期错误,或者pager的FullListIfExpired参数不是为true,或者continue为空,则直接返回。
if !errors.IsResourceExpired(err) || !p.FullListIfExpired || options.Continue == "" {
return nil, err
}
//否则的话,则尝试进行full list。也就是把limit设置为0,再调用一次list方法。这次是全量,因此直接返回pageFn
options.Limit = 0
options.Continue = ""
options.ResourceVersion = requestedResourceVersion
return p.PageFn(ctx, options)
}
m, err := meta.ListAccessor(obj)
if err != nil {
return nil, fmt.Errorf("returned object must be a list: %v", err)
}
// exit early and return the object we got if we haven't processed any pages
if len(m.GetContinue()) == 0 && list == nil {
return obj, nil
}
// initialize the list and fill its contents
if list == nil {
list = &metainternalversion.List{Items: make([]runtime.Object, 0, options.Limit+1)}
list.ResourceVersion = m.GetResourceVersion()
list.SelfLink = m.GetSelfLink()
}
//将拿到的数据,存入list中。
if err := meta.EachListItem(obj, func(obj runtime.Object) error {
list.Items = append(list.Items, obj)
return nil
}); err != nil {
return nil, err
}
// if we have no more items, return the list
//如果没有更多的items说明list结束,返回list,结束list。continue参数应该是下一次获取的对象的index
if len(m.GetContinue()) == 0 {
return list, nil
}
// set the next loop up
//设置下一块list的配置,也即是index的值。
options.Continue = m.GetContinue()
// Clear the ResourceVersion on the subsequent List calls to avoid the
// `specifying resource version is not allowed when using continue` error.
// See https://github.com/kubernetes/kubernetes/issues/85221#issuecomment-553748143.
options.ResourceVersion = ""
}
}
来看看api server是怎么规定list 请求的:
为了用分块的形式返回一个列表,集合请求上可以设置两个新的参数 limit 和 continue,并且所有 list 操作的返回结果列表的 metadata 字段中会包含一个 新的 continue 字段。 客户端应该将 limit 设置为希望在每个数据块中收到的结果个数上限,而服务器则 会在结果中至多返回 limit 个资源并在集合中还有更多资源的时候包含一个 continue 值。客户端在下次请求时则可以将此 continue 值传递给服务器, 告知后者要从何处开始返回结果的下一个数据块。 通过重复这一操作直到服务器端返回空的 continue 值,客户端可以受到结果的 全集。
我们看下具体的reflector的list方法是什么,其实就是每个资源对象informer的list方法。比如对于configmap,其实际的list方法就是:
func NewFilteredConfigMapInformer(client kubernetes.Interface, namespace string, resyncPeriod time.Duration, indexers cache.Indexers, tweakListOptions internalinterfaces.TweakListOptionsFunc) cache.SharedIndexInformer {
return cache.NewSharedIndexInformer(
&cache.ListWatch{
//这就是实际的list方法
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.CoreV1().ConfigMaps(namespace).List(options)
},
//这也是实际的watch方法。
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.CoreV1().ConfigMaps(namespace).Watch(options)
},
},
&corev1.ConfigMap{},
resyncPeriod,
indexers,
)
}
这些方法都会在我们写newInformerFactory时,实例化每个资源对象的informer时被new。也就是NewFilteredConfigMapInformer方法。
list拿到数据后,reflctor将其存入deltafifo中。进一步处理
select {
case <-stopCh:
return nil
case r := <-panicCh:
panic(r)
case <-listCh:
}
if err != nil {
return fmt.Errorf("%s: Failed to list %v: %v", r.name, r.expectedTypeName, err)
}
initTrace.Step("Objects listed")
listMetaInterface, err := meta.ListAccessor(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v: %v", r.name, list, err)
}
resourceVersion = listMetaInterface.GetResourceVersion()
initTrace.Step("Resource version extracted")
items, err := meta.ExtractList(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v (%v)", r.name, list, err)
}
initTrace.Step("Objects extracted")
//这里对list出的数据,调用syncWith交给deltafifo处理
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("%s: Unable to sync list result: %v", r.name, err)
}
syncWith方法
// syncWith replaces the store's items with the given list.
//这里是调用deltafifo的replace方法。因为list是全量,表示etcd的最新全量数据,对deltafifo需要完全替换掉老数据。
func (r *Reflector) syncWith(items []runtime.Object, resourceVersion string) error {
found := make([]interface{}, 0, len(items))
for _, item := range items {
found = append(found, item)
}
return r.store.Replace(found, resourceVersion)
}
watch
for {
// give the stopCh a chance to stop the loop, even in case of continue statements further down on errors
select {
case <-stopCh:
return nil
default:
}
timeoutSeconds := int64(minWatchTimeout.Seconds() * (rand.Float64() + 1.0))
options = metav1.ListOptions{
ResourceVersion: resourceVersion,
// We want to avoid situations of hanging watchers. Stop any wachers that do not
// receive any events within the timeout window.
TimeoutSeconds: &timeoutSeconds,
// To reduce load on kube-apiserver on watch restarts, you may enable watch bookmarks.
// Reflector doesn't assume bookmarks are returned at all (if the server do not support
// watch bookmarks, it will ignore this field).
AllowWatchBookmarks: true,
}
w, err := r.listerWatcher.Watch(options)
对于watch方法,是listAndWatch函数的最后一段,也是利用for一直死循环的一段。
利用select监听stop通道,进行退出。否则则一直执行watch。
watch的参数:
resourceversion。这个参数是上面list后,对象的meta的resourceversion给出的。表示从该版本开始进行watch。
TimeoutSeconds:表示能容忍多久的无响应。每次都会设置一个随机值。
AllowWatchBookmarks:为了减少watch重新启动时api server的压力。可以启用监视书签。Reflector根本不假设返回书签(如果服务器不支持watchbookmarks,它将忽略此字段)。也即是说我们不能假定服务器端会按某特定时间间隔返回书签事件,甚至也不能 假定服务器一定会发送 bookmark 事件。
bookmark技术
那么bookmark是啥?
它是api server为了帮助用户回溯指定resourceversion的书签。称之为监视书签(watch bookmark)
为了处理历史窗口过短的问题,我们引入了 bookmark(书签) 监视事件的概念。 该事件是一种特殊事件,用来标示客户端所请求的、指定的 resourceVersion 之前 的所有变更都以被发送。该事件中返回的对象是所请求的资源类型,但其中仅包含 resourceVersion 字段,例如:
GET /api/v1/namespaces/test/pods?watch=1&resourceVersion=10245&allowWatchBookmarks=true
---
200 OK
Transfer-Encoding: chunked
Content-Type: application/json
{
"type": "ADDED",
"object": {"kind": "Pod", "apiVersion": "v1", "metadata": {"resourceVersion": "10596", ...}, ...}
}
...
{
"type": "BOOKMARK",
"object": {"kind": "Pod", "apiVersion": "v1", "metadata": {"resourceVersion": "12746"} }
}
对于类型为BOOKMARK类型的时事件,对象只包含resourceVersion字段。表示12746之前的所有变更都已经发送给过客户端。这可以告诉客户端,12746之前的事件都可以不用入队处理。
回到watch方法,设置好这些options后,就调用reflector的watch方法(也就是具体资源对象informer的watch方法)开始监听。
然后调用reflector的watchHandler方法对watch到的对象进行处理。
if err := r.watchHandler(w, &resourceVersion, resyncerrc, stopCh); err != nil {
if err != errorStopRequested {
switch {
case apierrs.IsResourceExpired(err):
klog.V(4).Infof("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
default:
klog.Warningf("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
}
}
return nil
}
详细解析watchHandler
k8s.io/client-go/tools/cache/reflector.go
func (r *Reflector) watchHandler(w watch.Interface, resourceVersion *string, errc chan error, stopCh <-chan struct{}) error {
start := r.clock.Now()
eventCount := 0
// Stopping the watcher should be idempotent and if we return from this function there's no way
// we're coming back in with the same watch interface.
defer w.Stop()
//for死循环处理watch的结果
loop:
for {
select {
case <-stopCh:
return errorStopRequested
case err := <-errc:
return err
case event, ok := <-w.ResultChan():
if !ok {
break loop
}
if event.Type == watch.Error {
return apierrs.FromObject(event.Object)
}
//判断watch的对象type是否和预期的一致
if r.expectedType != nil {
if e, a := r.expectedType, reflect.TypeOf(event.Object); e != a {
utilruntime.HandleError(fmt.Errorf("%s: expected type %v, but watch event object had type %v", r.name, e, a))
continue
}
}
//判断watch的对象GVK是否和预期的一致
if r.expectedGVK != nil {
if e, a := *r.expectedGVK, event.Object.GetObjectKind().GroupVersionKind(); e != a {
utilruntime.HandleError(fmt.Errorf("%s: expected gvk %v, but watch event object had gvk %v", r.name, e, a))
continue
}
}
meta, err := meta.Accessor(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event))
continue
}
//获取新的resource version
newResourceVersion := meta.GetResourceVersion()
//对于不同的事件,调用reflector的store的对应接口进行处理,这里也就是deltafifo
switch event.Type {
case watch.Added:
err := r.store.Add(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to add watch event object (%#v) to store: %v", r.name, event.Object, err))
}
case watch.Modified:
err := r.store.Update(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to update watch event object (%#v) to store: %v", r.name, event.Object, err))
}
case watch.Deleted:
// TODO: Will any consumers need access to the "last known
// state", which is passed in event.Object? If so, may need
// to change this.
err := r.store.Delete(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to delete watch event object (%#v) from store: %v", r.name, event.Object, err))
}
case watch.Bookmark:
//对于书签的type,表示该revision之前的都已经同步过了,因此不需要入deltafifo处理。直接记录版本号就行
// A `Bookmark` means watch has synced here, just update the resourceVersion
default:
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event))
}
*resourceVersion = newResourceVersion
r.setLastSyncResourceVersion(newResourceVersion)
eventCount++
}
}
watchDuration := r.clock.Since(start)
if watchDuration < 1*time.Second && eventCount == 0 {
return fmt.Errorf("very short watch: %s: Unexpected watch close - watch lasted less than a second and no items received", r.name)
}
klog.V(4).Infof("%s: Watch close - %v total %v items received", r.name, r.expectedTypeName, eventCount)
return nil
}
resync
在listAndWatch中,单独起了一个协程进行resync处理。
go func() {
//判断reflector自身设置的resync周期是否到了,这里时间就是newShareInformerFactory传入的时间参数。
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
//然后会判断reflector中的ShouldResync函数是否为true,该函数其实是调用的processor的ShouldResync函数。用于判断processor是否有listener达到resync周期,如果达到了。才可以进行同步。
if r.ShouldResync == nil || r.ShouldResync() {
klog.V(4).Infof("%s: forcing resync", r.name)
//同步是调用deltafifo的resync方法进行全量resync,具体实现在deltafifo中解答
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()
注意的是,processor的ShouldResync函数,其周期的设置是在AddEventHandlerWithResyncPeriod设置。一般我们在写controller时,都只会调用AddEventHandler进行回调函数的设置,该函数默认的同步周期是和informer那设置的一样。如果想自定义,就通过AddEventHandlerWithResyncPeriod函数。
总结下,也就是对于resync而言,需要同时达到reflector自身的resync周期,以及processor的resync周期,才能触发resync。
那么processor和listener是什么?用户通过AddEventHandler设置的自定义回调函数又是怎么注入的呢?接着看下一节。
Processor&Listener
sharedProcessor结构体
processor是管理这些回调函数的资源对象,每个informer都会有一个。在newSharedInformer时,进行初始化。
processor是管理这些回调函数的资源对象,每个informer都会有一个。在newSharedInformer时,进行初始化。
func NewSharedIndexInformer(lw ListerWatcher, objType runtime.Object, defaultEventHandlerResyncPeriod time.Duration, indexers Indexers) SharedIndexInformer {
realClock := &clock.RealClock{}
sharedIndexInformer := &sharedIndexInformer{
processor: &sharedProcessor{clock: realClock}, //这个就是每个informer的processor
indexer: NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers),
listerWatcher: lw,
objectType: objType,
resyncCheckPeriod: defaultEventHandlerResyncPeriod,
defaultEventHandlerResyncPeriod: defaultEventHandlerResyncPeriod,
cacheMutationDetector: NewCacheMutationDetector(fmt.Sprintf("%T", objType)),
clock: realClock,
}
return sharedIndexInformer
}
NewSharedIndexInformer该函数会在每个资源对象的new informer函数那被调用。
看下sharedProcessor结构
type sharedProcessor struct {
listenersStarted bool
listenersLock sync.RWMutex
listeners []*processorListener //存储回调函数的list
syncingListeners []*processorListener //存储可以进行resync的回调函数的list
clock clock.Clock
wg wait.Group
}
也就是Listener代表着回调函数。
listener结构体
type processorListener struct {
nextCh chan interface{} //事件notify通道
addCh chan interface{} //事件notify通道,add和next组成了一个环形缓冲区,进行限速,防止用户的workqueue处理不过来。
handler ResourceEventHandler //回调函数
//pendingNotifications是一个无限的环形缓冲区,它保存所有尚未分发的通知。每个listener有一个
pendingNotifications buffer.RingGrowing
// requestedResyncPeriod 是addEventHandler填入的参数,表示用户希望该函数多久进行一次resync
requestedResyncPeriod time.Duration
// resyncPeriod is how frequently the listener wants a full resync from the shared informer. This
// value may differ from requestedResyncPeriod if the shared informer adjusts it to align with the
// informer's overall resync check period.
//这个表示实际的resync周期,该值是由上面参数requestedResyncPeriod和informer的resync参数比较得到的。
resyncPeriod time.Duration
// nextResync is the earliest time the listener should get a full resync
nextResync time.Time
// resyncLock guards access to resyncPeriod and nextResync
resyncLock sync.Mutex
}
入口,AddeventHandler
向processor注册这些回调函数。
configmapInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: rgController.handleObject,
UpdateFunc: func(old, new interface{}) {
newDepl := new.(*v1.ConfigMap)
oldDepl := old.(*v1.ConfigMap)
if newDepl.ResourceVersion == oldDepl.ResourceVersion {
return
}
rgController.handleObject(new)
},
DeleteFunc: rgController.handleObject,
})
AddEventHandler实际上是调用AddEventHandlerWithResyncPeriod。
func (s *sharedIndexInformer) AddEventHandler(handler ResourceEventHandler) {
s.AddEventHandlerWithResyncPeriod(handler, s.defaultEventHandlerResyncPeriod)
}
回调函数默认的resync周期就是和reflector的resync周期一样。
AddEventHandlerWithResyncPeriod:
func (s *sharedIndexInformer) AddEventHandlerWithResyncPeriod(handler ResourceEventHandler, resyncPeriod time.Duration) {
s.startedLock.Lock()
defer s.startedLock.Unlock()
if s.stopped {
klog.V(2).Infof("Handler %v was not added to shared informer because it has stopped already", handler)
return
}
if resyncPeriod > 0 {
if resyncPeriod < minimumResyncPeriod {
klog.Warningf("resyncPeriod %d is too small. Changing it to the minimum allowed value of %d", resyncPeriod, minimumResyncPeriod)
resyncPeriod = minimumResyncPeriod
}
//这里的resyncCheckPeriod就是informer设置的resync周期。
//如果回调函数的同步周期小于resyncCheckPeriod
if resyncPeriod < s.resyncCheckPeriod {
if s.started {
klog.Warningf("resyncPeriod %d is smaller than resyncCheckPeriod %d and the informer has already started. Changing it to %d", resyncPeriod, s.resyncCheckPeriod, s.resyncCheckPeriod)
//如果informer已经开始了,则将listener的同步周期改为和informer的resync周期一致
resyncPeriod = s.resyncCheckPeriod
} else {
// if the event handler's resyncPeriod is smaller than the current resyncCheckPeriod, update
// resyncCheckPeriod to match resyncPeriod and adjust the resync periods of all the listeners
// accordingly
//如果iformer还没有start,如果事件处理程序的resyncPeriod小于当前resyncCheckPeriod,则更新
//resyncCheckPeriod以匹配resyncPeriod并调整所有listener的同步周期
s.resyncCheckPeriod = resyncPeriod
s.processor.resyncCheckPeriodChanged(resyncPeriod)
}
}
}
//然后对于回调函数,新建一个对应的listener
listener := newProcessListener(handler, resyncPeriod, determineResyncPeriod(resyncPeriod, s.resyncCheckPeriod), s.clock.Now(), initialBufferSize)
//并当informer还没启动时,立即注册进processor
if !s.started {
s.processor.addListener(listener)
return
}
//否则为了安全加入processor中。
//1 停止发送add/update/delete等通知事件,也就是停止deltafifo进行通知。
//2 加入listener
//3 遍历informer当前的缓存indexer中的所有对象,作为add事件,加入给到新的listener
//4 解除第一步
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
s.processor.addListener(listener)
for _, item := range s.indexer.List() {
listener.add(addNotification{newObj: item})
}
}
接着分析addListener方法干了什么。
func (p *sharedProcessor) addListener(listener *processorListener) {
p.listenersLock.Lock()
defer p.listenersLock.Unlock()
p.addListenerLocked(listener)
if p.listenersStarted {
p.wg.Start(listener.run)
p.wg.Start(listener.pop)
}
}
func (p *sharedProcessor) addListenerLocked(listener *processorListener) {
p.listeners = append(p.listeners, listener)
p.syncingListeners = append(p.syncingListeners, listener)
}
比较简单,先调用addListenerLocked函数,将listener注册到processor的listeners和syncinglisteners两个列表中。
接着就是判断processor的listener是否开始了,如果开始了,就要listener的run和pop方法进行start。
接下里看下processor是怎么运行的,如何保证事件的监听和回调的。
processor和listener运行
processor run
func (p *sharedProcessor) run(stopCh <-chan struct{}) {
func() {
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
for _, listener := range p.listeners {
对每个listener,开启run和pop方法
p.wg.Start(listener.run)
p.wg.Start(listener.pop)
}
p.listenersStarted = true
}()
<-stopCh
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
for _, listener := range p.listeners {
close(listener.addCh) // Tell .pop() to stop. .pop() will tell .run() to stop
}
p.wg.Wait() // Wait for all .pop() and .run() to stop
}
shouldResync函数
// shouldResync queries every listener to determine if any of them need a resync, based on each
// listener's resyncPeriod.
//查询每个listener。判断哪些需要进行resync,如果需要,则加入到syncingListeners 列表中
func (p *sharedProcessor) shouldResync() bool {
p.listenersLock.Lock()
defer p.listenersLock.Unlock()
p.syncingListeners = []*processorListener{}
resyncNeeded := false
now := p.clock.Now()
for _, listener := range p.listeners {
// need to loop through all the listeners to see if they need to resync so we can prepare any
// listeners that are going to be resyncing.
if listener.shouldResync(now) {
resyncNeeded = true
p.syncingListeners = append(p.syncingListeners, listener)
listener.determineNextResync(now)
}
}
return resyncNeeded
}
该函数,就是reflector在resync时,调用的r.ShouldResync()方法。
processor distribute
该方法会在deltafifo的处理中被调用,deltafifo获得list/watch的数据后,进行处理,然后分别调用indexer进行数据存储,然后再调用distribute函数进行数据分发处理。
func (p *sharedProcessor) distribute(obj interface{}, sync bool) {
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
//如果数据类型是sync,则将数据分发给处于syncingListeners列表中的Listeners
if sync {
for _, listener := range p.syncingListeners {
listener.add(obj)
}
} else {
//否则。则把数据分发给处于listener列表中的Listeners
for _, listener := range p.listeners {
listener.add(obj)
}
}
}
Listener add
func (p *processorListener) add(notification interface{}) {
p.addCh <- notification
}
把资源对象传给listener的addCh通道。
Listener pop(环形缓冲区)
该函数是实现环形缓冲区的关键
func (p *processorListener) pop() {
defer utilruntime.HandleCrash()
defer close(p.nextCh) // Tell .run() to stop
//初始化nextCh为空
var nextCh chan<- interface{}
//初始化数据为空
var notification interface{}
for {
//用select对nextCh和addCh两个通道进行操作。
select {
//对于nextCh通道,把notification对象数据传入。
case nextCh <- notification:
// 如果成功,则从pendingNotifications缓存区里再拿一个数据
var ok bool
notification, ok = p.pendingNotifications.ReadOne()
if !ok { // Nothing to pop
//如果没有数据,说明缓冲区为空了,则将nextCh关闭
nextCh = nil // Disable this select case
}
//对于addCh,一直是监听状态,如果有数据来了。
case notificationToAdd, ok := <-p.addCh:
if !ok {
return
}
//如果这时notification为空,则可以认为没东西发了(并且可以认为环形缓冲区pendingNotifications也是空),或者是第一次
if notification == nil { // No notification to pop (and pendingNotifications is empty)
//就把刚接收到的数据给notification,并开启nextCh通道,也就是让nextCh开始接受数据。
notification = notificationToAdd
nextCh = p.nextCh
} else { // There is already a notification waiting to be dispatched
//如果notification不为空,则表示notification一直没有被nextCh消费。为了防止nextCh数据堆积,也就是用户的
//事件处理不过来。则用一个pendingNotifications缓冲区先存入。
p.pendingNotifications.WriteOne(notificationToAdd)
}
}
}
}
注意,由于select是没有顺序的,因此执行nextCh和addCh的概率各为50%,这也是实现环形缓冲区的关键设计。
环形缓冲区的设计十分巧妙。根据上面的实现逻辑,可以考虑一些特殊情况,比如当select概率性只走第二个case,也就是一直未消费notification时,会发现notification不为空,就会一直将数据存入pendingNotifications缓存。然后突然,走了第一个case,也就是数据被消费,消费完后,会从p.pendingNotifications.ReadOne()取下一个数据,如果接下来一直走第一个case,也即是会一直把pendingNotifications的缓存数据消费完,然后nextCh就会被赋予nil,也就是关闭。只能走第二个case,重新等待数据的传入。
Listener run
func (p *processorListener) run() {
// this call blocks until the channel is closed. When a panic happens during the notification
// we will catch it, **the offending item will be skipped!**, and after a short delay (one second)
// the next notification will be attempted. This is usually better than the alternative of never
// delivering again.
stopCh := make(chan struct{})
wait.Until(func() {
// this gives us a few quick retries before a long pause and then a few more quick retries
err := wait.ExponentialBackoff(retry.DefaultRetry, func() (bool, error) {
//这里是不断监听nextCh的通道,如果有数据来,则根据数据的类型,进行相应回调函数的调用。
for next := range p.nextCh {
switch notification := next.(type) {
case updateNotification:
p.handler.OnUpdate(notification.oldObj, notification.newObj)
case addNotification:
p.handler.OnAdd(notification.newObj)
case deleteNotification:
p.handler.OnDelete(notification.oldObj)
default:
utilruntime.HandleError(fmt.Errorf("unrecognized notification: %T", next))
}
}
// the only way to get here is if the p.nextCh is empty and closed
return true, nil
})
// the only way to get here is if the p.nextCh is empty and closed
if err == nil {
close(stopCh)
}
}, 1*time.Minute, stopCh)
}
该方法就是对nextCh进行消费。获取nextCh中的数据,根据数据类型,进行相应回调函数的调用。
DeltaFIFO
deltafifo可以分两部分看,delta和fifo,
其中delta是map实现的。key是对象的key,value则是对象数据,包括数据和事件类型。
fifo则是一个队列,用list实现,该fifo实际上是为了保证数据的有序消费。
结构体
type DeltaFIFO struct {
// lock/cond protects access to 'items' and 'queue'.
lock sync.RWMutex
cond sync.Cond
// items可以认为是delta,key是对象的key
items map[string]Deltas
queue []string
// populated is true if the first batch of items inserted by Replace() has been populated
// or Delete/Add/Update was called first.
populated bool
// initialPopulationCount是第一次调用Replace()插入的项数
initialPopulationCount int
// keyFunc 用于计算出对象的key的
keyFunc KeyFunc
// knownObjects list keys that are "known", for the
// purpose of figuring out which items have been deleted
// when Replace() or Delete() is called.
//knownObjects表示哪些“known”的key,以便在调用Replace()或Delete()时确定哪些项已被删除。其实就是本地的缓存indexer
knownObjects KeyListerGetter
// Indication the queue is closed.
// Used to indicate a queue is closed so a control loop can exit when a queue is empty.
// Currently, not used to gate any of CRED operations.
closed bool
closedLock sync.Mutex
}
创建方法
func NewDeltaFIFO(keyFunc KeyFunc, knownObjects KeyListerGetter) *DeltaFIFO {
f := &DeltaFIFO{
items: map[string]Deltas{},
queue: []string{},
keyFunc: keyFunc,
knownObjects: knownObjects,
}
f.cond.L = &f.lock
return f
}
fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, s.indexer)
可以看到,deltafifo的knownObjects就是indexer缓存。
MetaNamespaceKeyFunc
func MetaNamespaceKeyFunc(obj interface{}) (string, error) {
if key, ok := obj.(ExplicitKey); ok {
return string(key), nil
}
meta, err := meta.Accessor(obj)
if err != nil {
return "", fmt.Errorf("object has no meta: %v", err)
}
if len(meta.GetNamespace()) > 0 {
return meta.GetNamespace() + "/" + meta.GetName(), nil
}
return meta.GetName(), nil
}
很明显,是namespace + '/' + name的方式作为key。
HasSynced方法
当我们写controller时,在启动sharedinformerFactory.Start方法后,就要利用下列函数等待cache完成,才能开始controller的worker逻辑:
configmapInformer: configmapInformer.Informer().HasSynced, ...... cache.WaitForCacheSync(stopCh, c.configmapsSynced);
那么Informer().HasSynced,最终调用的就是deltafifo的hasSynced方法:
func (f *DeltaFIFO) HasSynced() bool {
f.lock.Lock()
defer f.lock.Unlock()
//如果initialPopulationCount为0,并且populated 为true,则表示已经第一次list同步完成。
return f.populated && f.initialPopulationCount == 0
}
initialPopulationCount表示第一次list的Population数量。这个值的初始化,会在reflector第一次list时,调用deltafifo的Replace函数进行设置。并在deltafifo的pop函数被减少,每次减1,表示被消费一个,一直到0,表示第一次list全部被消费掉。具体的调用在后面会说到。
Add/Update/Delete方法
func (f *DeltaFIFO) Add(obj interface{}) error {
f.lock.Lock()
defer f.lock.Unlock()
f.populated = true
return f.queueActionLocked(Added, obj)
}
// Update is just like Add, but makes an Updated Delta.
func (f *DeltaFIFO) Update(obj interface{}) error {
f.lock.Lock()
defer f.lock.Unlock()
f.populated = true
return f.queueActionLocked(Updated, obj)
}
func (f *DeltaFIFO) Delete(obj interface{}) error {
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
f.lock.Lock()
defer f.lock.Unlock()
f.populated = true
if f.knownObjects == nil {
if _, exists := f.items[id]; !exists {
//如果该对象已经被删了,则直接返回nil
// Presumably, this was deleted when a relist happened.
// Don't provide a second report of the same deletion.
return nil
}
} else {
// We only want to skip the "deletion" action if the object doesn't
// exist in knownObjects and it doesn't have corresponding item in items.
// Note that even if there is a "deletion" action in items, we can ignore it,
// because it will be deduped automatically in "queueActionLocked"
_, exists, err := f.knownObjects.GetByKey(id)
_, itemsExist := f.items[id]
if err == nil && !exists && !itemsExist {
// Presumably, this was deleted when a relist happened.
// Don't provide a second report of the same deletion.
return nil
}
}
return f.queueActionLocked(Deleted, obj)
}
将事件add/update/delete以及对象传入给queueActionLocked方法进行进一步处理,该方法下面介绍。
queueActionLocked方法
func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error {
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
newDeltas := append(f.items[id], Delta{actionType, obj})
//这里对deltas进行去重,对于连续两个是delete type的对象进行去重。
newDeltas = dedupDeltas(newDeltas)
if len(newDeltas) > 0 {
if _, exists := f.items[id]; !exists {
f.queue = append(f.queue, id)
}
f.items[id] = newDeltas
//处理好后,进行广播,使得监听的pop方法进行执行。pop方法下面会讲到
f.cond.Broadcast()
} else {
// We need to remove this from our map (extra items in the queue are
// ignored if they are not in the map).
delete(f.items, id)
}
return nil
}
看下dedupDeltas方法:
func dedupDeltas(deltas Deltas) Deltas {
n := len(deltas)
if n < 2 {
return deltas
}
//取delta列表的最后两个,如果是相同的,那么就去掉一个。
a := &deltas[n-1]
b := &deltas[n-2]
if out := isDup(a, b); out != nil {
d := append(Deltas{}, deltas[:n-2]...)
return append(d, *out)
}
return deltas
}
func isDup(a, b *Delta) *Delta {
if out := isDeletionDup(a, b); out != nil {
return out
}
// TODO: Detect other duplicate situations? Are there any?
return nil
}
// keep the one with the most information if both are deletions.
func isDeletionDup(a, b *Delta) *Delta {
if b.Type != Deleted || a.Type != Deleted {
return nil
}
// Do more sophisticated checks, or is this sufficient?
if _, ok := b.Object.(DeletedFinalStateUnknown); ok {
return a
}
return b
}
Pop方法
该方法是对fifo的数据进行消费。实际上是调用其参数process函数。该函数其实就是sharedinformer的HandleDeltas方法。
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
f.lock.Lock()
defer f.lock.Unlock()
for {
for len(f.queue) == 0 {
// When the queue is empty, invocation of Pop() is blocked until new item is enqueued.
// When Close() is called, the f.closed is set and the condition is broadcasted.
// Which causes this loop to continue and return from the Pop().
if f.IsClosed() {
return nil, ErrFIFOClosed
}
//这里是等待queueActionLocked的锁的释放。表示是有数据来了
f.cond.Wait()
}
//取出队列fifo的第一个。
id := f.queue[0]
//并把第一个给删掉
f.queue = f.queue[1:]
//这里就是对initialPopulationCount的减少,消费一个,就减1.
if f.initialPopulationCount > 0 {
f.initialPopulationCount--
}
//根据id,获得map的value,也就是deltas
item, ok := f.items[id]
if !ok {
// Item may have been deleted subsequently.
continue
}
//把该id从map中删掉
delete(f.items, id)
//调用HandleDeltas方法处理这些deltas
err := process(item)
if e, ok := err.(ErrRequeue); ok {
f.addIfNotPresent(id, item)
err = e.Err
}
// Don't need to copyDeltas here, because we're transferring
// ownership to the caller.
return item, err
}
}
该方法会持续运行。运行的入口,会在最后详细说,下面先贴下调用的代码:会在processLoop函数中持续运行。
func (c *controller) processLoop() {
for {
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
if err != nil {
if err == ErrFIFOClosed {
return
}
if c.config.RetryOnError {
// This is the safe way to re-enqueue.
c.config.Queue.AddIfNotPresent(obj)
}
}
}
}
而processLoop函数则会在sharedinformer的controller中被一秒调用一次(如果退出的话)
wait.Until(c.processLoop, time.Second, stopCh)
HandleDeltas方法
k8s.io/client-go/tools/cache/shared_informer.go
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// from oldest to newest
//该函数就是会对deltas进行遍历,处理。对每个对象,根据其事件类型,进行indexer的存储,以及processor的分发,给到回调函数处理。
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
isSync := d.Type == Sync
s.cacheMutationDetector.AddObject(d.Object)
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
if err := s.indexer.Add(d.Object); err != nil {
return err
}
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
case Deleted:
if err := s.indexer.Delete(d.Object); err != nil {
return err
}
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}
Replace方法
func (f *DeltaFIFO) Replace(list []interface{}, resourceVersion string) error {
f.lock.Lock()
defer f.lock.Unlock()
keys := make(sets.String, len(list))
for _, item := range list {
//对每一个list对象,计算其key,并插入到新的对象keys里暂存
key, err := f.KeyOf(item)
if err != nil {
return KeyError{item, err}
}
keys.Insert(key)
//并作为sync的类型,放入deltafifo中
if err := f.queueActionLocked(Sync, item); err != nil {
return fmt.Errorf("couldn't enqueue object: %v", err)
}
}
如果indexer为空。理论上不可能
if f.knownObjects == nil {
// Do deletion detection against our own list.
queuedDeletions := 0
for k, oldItem := range f.items {
if keys.Has(k) {
continue
}
var deletedObj interface{}
if n := oldItem.Newest(); n != nil {
deletedObj = n.Object
}
queuedDeletions++
if err := f.queueActionLocked(Deleted, DeletedFinalStateUnknown{k, deletedObj}); err != nil {
return err
}
}
if !f.populated {
f.populated = true
// While there shouldn't be any queued deletions in the initial
// population of the queue, it's better to be on the safe side.
f.initialPopulationCount = len(list) + queuedDeletions
}
return nil
}
// Detect deletions not already in the queue.
//对本地缓存indexer和新的list对象进行同步
knownKeys := f.knownObjects.ListKeys()
queuedDeletions := 0
for _, k := range knownKeys {
//如果list中已经有的key,那么跳过这个key,无需处理
if keys.Has(k) {
continue
}
//如果list没有这个key,也就是indexer缓存的对象实际上已经不存在了,这时需要处理。找到其需要删除的对象
deletedObj, exists, err := f.knownObjects.GetByKey(k)
if err != nil {
deletedObj = nil
klog.Errorf("Unexpected error %v during lookup of key %v, placing DeleteFinalStateUnknown marker without object", err, k)
} else if !exists {
deletedObj = nil
klog.Infof("Key %v does not exist in known objects store, placing DeleteFinalStateUnknown marker without object", k)
}
//如果存在,则需要处理的对象数量+1,并作为delete类型,传入deltafifo中
queuedDeletions++
if err := f.queueActionLocked(Deleted, DeletedFinalStateUnknown{k, deletedObj}); err != nil {
return err
}
}
if !f.populated {
//最后计算list后,对象的数量。在对deltafifo进行消费时,每处理一个对象,传入indexer和
//listener,initialPopulationCount都要-1,一直到initialPopulationCount都要为0,informer的hassyncd才是true。
f.populated = true
f.initialPopulationCount = len(list) + queuedDeletions
}
return nil
}
Resync方法
该方法用于reflector的resync。也就是会周期性执行。
func (f *DeltaFIFO) Resync() error {
f.lock.Lock()
defer f.lock.Unlock()
if f.knownObjects == nil {
return nil
}
keys := f.knownObjects.ListKeys()
for _, k := range keys {
//对于indexer的所有对象的key,进行同步
if err := f.syncKeyLocked(k); err != nil {
return err
}
}
return nil
}
func (f *DeltaFIFO) syncKeyLocked(key string) error {
obj, exists, err := f.knownObjects.GetByKey(key)
if err != nil {
klog.Errorf("Unexpected error %v during lookup of key %v, unable to queue object for sync", err, key)
return nil
} else if !exists {
klog.Infof("Key %v does not exist in known objects store, unable to queue object for sync", key)
return nil
}
// If we are doing Resync() and there is already an event queued for that object,
// we ignore the Resync for it. This is to avoid the race, in which the resync
// comes with the previous value of object (since queueing an event for the object
// doesn't trigger changing the underlying store <knownObjects>.
//这里对对象有个禁止赛跑的处理,如果该对象已经在fifo处理队列中了,那就忽略这次resync。
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
if len(f.items[id]) > 0 {
return nil
}
//如果对象不在fifo处理队列中,那么就可以进行resync处理
if err := f.queueActionLocked(Sync, obj); err != nil {
return fmt.Errorf("couldn't queue object: %v", err)
}
return nil
}
Indexer
indexer是client-go用来存储资源对象并自带索引功能的本地存储,reflector从deltafifo将消费的对象存储到indexer,indexer中的数据与etcd保持完全一致。client-go中list,get方法可以从本地indexer中获取数据而无需从远端k8s集群中读取。
indexer的底层存储实现是threadSafeMap。threadSafeMap是并发安全的存储,curd都会加锁处理。indexer在此基础上封装了索引index的功能,方便用户通过自己写的索引函数,高效的按需获取数据。
threadSafeMap
该存储是一个内存中的存储,不会落盘,每次增删改查都会加锁。该存储将资源存在map中
// NewThreadSafeStore creates a new instance of ThreadSafeStore.
func NewThreadSafeStore(indexers Indexers, indices Indices) ThreadSafeStore {
return &threadSafeMap{
items: map[string]interface{}{}, //这个就是threadSafeMap
indexers: indexers, //这些就是索引函数
indices: indices, // 这个也是索引函数
}
}
indexer索引器
每次增删改查threadSafeMap数据时,都会通过updateIndices或者deleteFromIndices函数变更indexer。indexer被设计为可以用户自定义索引函数。
indexer的四个重要数据结构
// Indexers maps a name to a IndexFunc
type Indexers map[string]IndexFunc
type IndexFunc func(obj interface{}) ([]string, error)
// Indices maps a name to an Index
type Indices map[string]Index
type Index map[string]sets.String
Indexers:存储索引器,key是用户命名索引器的名称,value是用户实现的索引器函数indexFunc。
indexFunc:用户实现的索引器函数,定义为接收一个资源对象,返回索引结果列表,也就是用户告诉index,根据输入的资源对象中需返回啥值作为索引。
Indices:存储缓存器,key是索引器的名字,也就是和Indexers的key一样。value是这个索引器下的数据
index:存储的缓存数据,key是通过indexFunc计算出来的索引,value其实就是真正存储数据items的key。也就是通过index,可以拿到符合用户自定义索引器条件的数据,提高查询效率。
比如
//indexFunc,用户实现的。表明要从obj对象中,获得对象的namespace,以此作为索引
func MetaNamespaceIndexFunc(obj interface{}) ([]string, error) {
meta, err := meta.Accessor(obj)
if err != nil {
return []string{""}, fmt.Errorf("object has no meta: %v", err)
}
return []string{meta.GetNamespace()}, nil
}
func main() {
//这里表示new一个indexers,其中索引器的名字为byns,对应索引器的索引函数为MetaNamespaceIndexFunc
index := cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{"byns": MetaNamespaceIndexFunc})
pod1 := &v1.Pod{}
pod2 := &v1.Pod{}
index.Add(pod1)
index.Add(pod2)
//这里是使用index的功能,使用byns的索引器,然后索引的key是kube-system,也就是对象的ns满足kube-system都要索引出来。
nspod, err := index.ByIndex("byns", "kube-system")
}
来看看这个ByIndex函数的实现
func (c *threadSafeMap) ByIndex(indexName, indexKey string) ([]interface{}, error) {
c.lock.RLock()
defer c.lock.RUnlock()
//通过indexName索引器的名字,获取索引器的索引函数。如果不存在,则说明该索引器不存在,是用户填错了,直接返回错误
indexFunc := c.indexers[indexName]
if indexFunc == nil {
return nil, fmt.Errorf("Index with name %s does not exist", indexName)
}
//然后根据索引器获得该索引器下的数据。
index := c.indices[indexName]
//根据用户想要查的key,在index中进行查找,index是一个map,key就是索引函数计算出来的索引,value是满足这些索引的值,也就是set。value实际上也是真正存储的items的key。
set := index[indexKey]
list := make([]interface{}, 0, set.Len())
for key := range set {
list = append(list, c.items[key])
}
return list, nil
}
那么索引器函数是怎么工作的呢?前面说了,在每次数据curd时,都会通过updateIndices或者deleteFromIndices函数变更indexer。
//add update delete方法,除了将数据真正存入items之外,还会更新indexer。
func (c *threadSafeMap) Add(key string, obj interface{}) {
c.lock.Lock()
defer c.lock.Unlock()
oldObject := c.items[key]
c.items[key] = obj
c.updateIndices(oldObject, obj, key)
}
func (c *threadSafeMap) Update(key string, obj interface{}) {
c.lock.Lock()
defer c.lock.Unlock()
oldObject := c.items[key]
c.items[key] = obj
c.updateIndices(oldObject, obj, key)
}
func (c *threadSafeMap) Delete(key string) {
c.lock.Lock()
defer c.lock.Unlock()
if obj, exists := c.items[key]; exists {
c.deleteFromIndices(obj, key)
delete(c.items, key)
}
}
接下来详细分析updateIndices方法,这是indexer实现的核心
func (c *threadSafeMap) updateIndices(oldObj interface{}, newObj interface{}, key string) {
// if we got an old object, we need to remove it before we add it again
//如果存在旧数据,则会先从索引中删掉该旧数据
if oldObj != nil {
c.deleteFromIndices(oldObj, key)
}
//然后遍历所有的索引器,因为可能用户注册了很多不同的索引器,有的按照ns索引,有的按照其他的。
//因此每次数据变动,都会将所有索引器全部更新。
for name, indexFunc := range c.indexers {
//对于索引器,获得indexFunc,然后获得计算出的索引值。这些索引值,才是用户关心的,比如计算出ns是啥?这些索引值,可能是个数组,因为可能一个对象里,有好几个用户关心的索引值。比如获得对象的所有label,作为索引值。
indexValues, err := indexFunc(newObj)
if err != nil {
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err))
}
//根据索引器的名字获得索引器下的所有缓存。
index := c.indices[name]
if index == nil {
index = Index{}
c.indices[name] = index
}
//然后对于每个计算出的索引值,判断index中是否有这个索引对应的数据。
for _, indexValue := range indexValues {
set := index[indexValue]
if set == nil {
set = sets.String{}
index[indexValue] = set
}
//然后将真正的key插入到索引对应的数据里。这样就保存了索引器算出来的每个索引值,所对应的数据。
set.Insert(key)
}
}
}
Informer运行
这一节会详细描述哦informer是怎么运行的,是如何将上面的那些组件组合一起运行的。
sharedinformer Start
在我们的控制器中,一般通过informerFactory的start方法开启每个informer的运行:
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30) eventRecorder := createRecorder(kubeClient, controllerAgentName) rgController := NewOamTemplateManagerControllerController(kubeClient, kubeInformerFactory.Core().V1().ConfigMaps(), eventRecorder, opts.Config.TraitJsonFilePath, opts.Config.WorkloadJsonFilePath) kubeInformerFactory.Start(stopCh)
k8s.io/client-go/informers/factory.go
实际上,会调用每个注册的informer的run方法
func (f *sharedInformerFactory) Start(stopCh <-chan struct{}) {
f.lock.Lock()
defer f.lock.Unlock()
for informerType, informer := range f.informers {
if !f.startedInformers[informerType] {
go informer.Run(stopCh)
f.startedInformers[informerType] = true
}
}
}
Run方法
informer会以一个controller的形式运行,run方法作为入口。
每个注册的informer都是sharedinformer类型的,因此其run方法是通用的:
k8s.io/client-go/tools/cache/shared_informer.go
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
//新建一个deltafifo,参数包括一个设置key的方法,一个indexer
fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, s.indexer)
//sharedinformer最终以一个contoller形式运行。设置下配置
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
Process: s.HandleDeltas,
}
func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
// Separate stop channel because Processor should be stopped strictly after controller
processorStopCh := make(chan struct{})
var wg wait.Group
defer wg.Wait() // Wait for Processor to stop
defer close(processorStopCh) // Tell Processor to stop
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
//开启每个processor的listener的运行
wg.StartWithChannel(processorStopCh, s.processor.run)
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true // Don't want any new listeners
}()
s.controller.Run(stopCh)
}
run方法是启动一个controller完成shareinformer的工作。cfg表示controller的配置。
Informer Controller
cfg的每个参数如下:
1、Queue是informer的deltafifo的实例。
2、listWatcher,是informer的list watch方法,这个在实例化资源的informer时会赋予这些方法。
3、object type,是资源对象类型
4、fullresyncperiod:全量resync的周期时间,该参数就是在用户写controller时new informerfactory时填的值。
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
![]()
5、retryonerror,失败时是否重试。
6、ShouldResync。该参数是一个函数,传入的是processor的shouldResync,该方法根据每个listener设置的resyncPeriod查询每个listener,以确定其中是否有任何listener需要重新同步。
该函数如下:
k8s.io/client-go/tools/cache/shared_informer.go
func (p *sharedProcessor) shouldResync() bool {
p.listenersLock.Lock()
defer p.listenersLock.Unlock()
p.syncingListeners = []*processorListener{}
resyncNeeded := false
now := p.clock.Now()
for _, listener := range p.listeners {
// need to loop through all the listeners to see if they need to resync so we can prepare any
// listeners that are going to be resyncing.
if listener.shouldResync(now) {
resyncNeeded = true
p.syncingListeners = append(p.syncingListeners, listener)
listener.determineNextResync(now)
}
}
return resyncNeeded
}
可以看到每次进入该函数,首先把processor的syncingListener列表重置为空。
Controller run方法
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
go func() {
<-stopCh
c.config.Queue.Close()
}()
//会新建一个reflector
r := NewReflector(
c.config.ListerWatcher, //传入informer的list watch方法,也就是每个资源对象informer的list watch
c.config.ObjectType,
c.config.Queue, //传入的是deltafifo
c.config.FullResyncPeriod, //resync的周期
)
r.ShouldResync = c.config.ShouldResync //processor的shouldresync方法
r.clock = c.clock
c.reflectorMutex.Lock()
c.reflector = r
c.reflectorMutex.Unlock()
var wg wait.Group
defer wg.Wait()
wg.StartWithChannel(stopCh, r.Run) //开启一个线程启动reflector的run方法,不停的在list watch,并将对象传入给deltafifo。
wait.Until(c.processLoop, time.Second, stopCh) //运行controller的processLoop方法
}
再看下processLoop方法,可以看到就是在不停启动deltafifo的pop方法,一直在消费该队列。
ifunc (c *controller) processLoop() {
for {
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
if err != nil {
if err == ErrFIFOClosed {
return
}
if c.config.RetryOnError {
// This is the safe way to re-enqueue.
c.config.Queue.AddIfNotPresent(obj)
}
}
}
}















 956
956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









