







Selenium 库
1、Chrome 浏览器
1、安装 WebDriver 驱动
0、注意点
如果你的电脑能没有内网的限制,则可以不需要下载 Chrome 驱动,前提是你的 selenium 版本必须大于等于 4.6
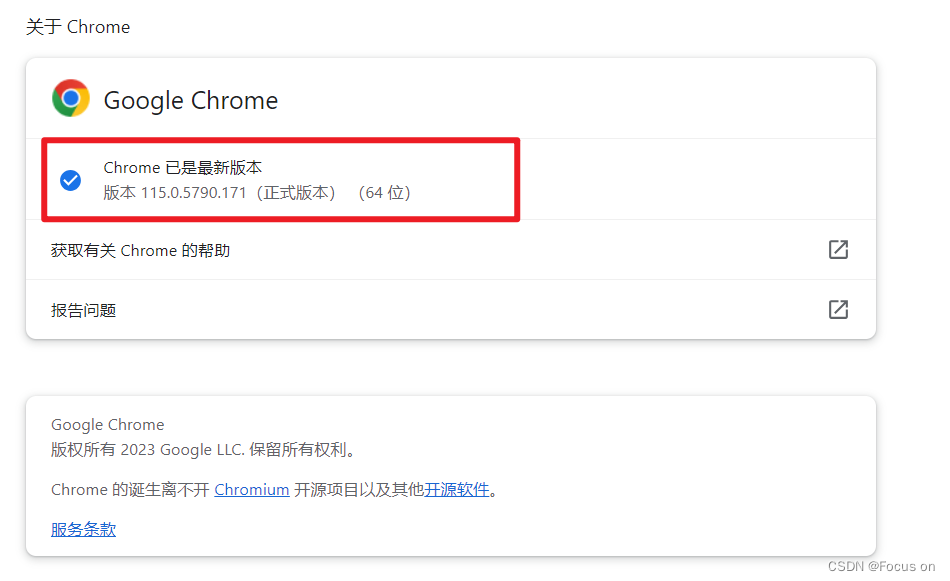
1、查看自己的Chrome 版本
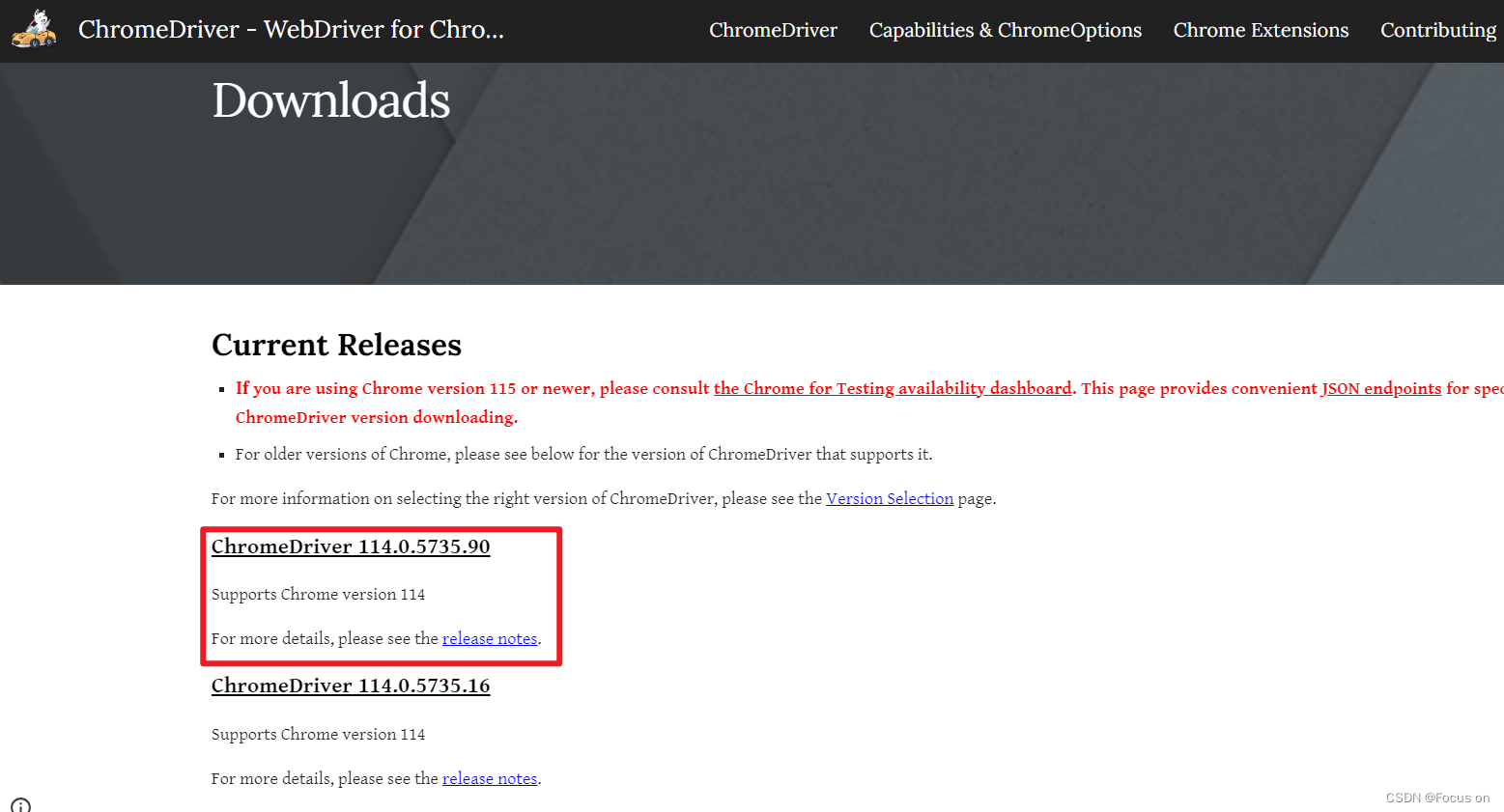
2、下载驱动
注意这里的驱动一定要选择和自己 Chrome 版本一致的版本(我另外安装了一个114版本的Chrome)
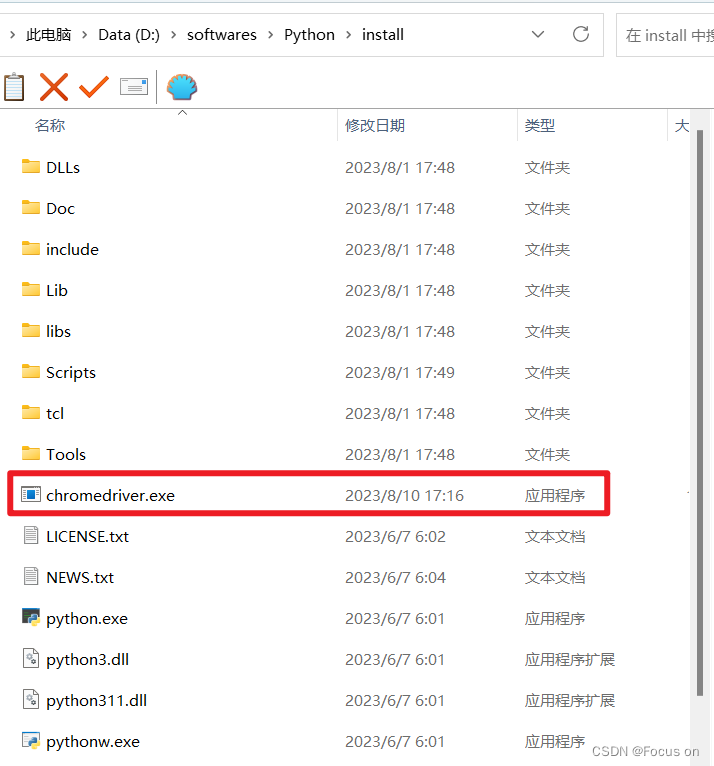
3、将下载好的驱动移动到 python 安装目录下
配置完成之后就可以了
2、Selenium 的使用案例
1、百度搜索 demo
1、配置 selenium 模拟访问时的一些参数
header = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36"
}
# 添加一些特殊的配置,使得界面更加的美观
options = webdriver.ChromeOptions()
# 1、关闭 selenium 调用时的 Chrome 浏览器的“开发者模式提示栏”
options.add_experimental_option("excludeSwitches", ['enable-automation'])
# 2、配置这个参数可以模拟各种设备上不同的环境,从而访问不同版本的浏览器
options.add_argument('user-agent=%s' % header)
# 3、最大化浏览器界面
options.add_argument("--start-maximized")
# selenium 从 4.6 版本开始,无需自己下载浏览器驱动
driver = webdriver.Chrome(options=options)
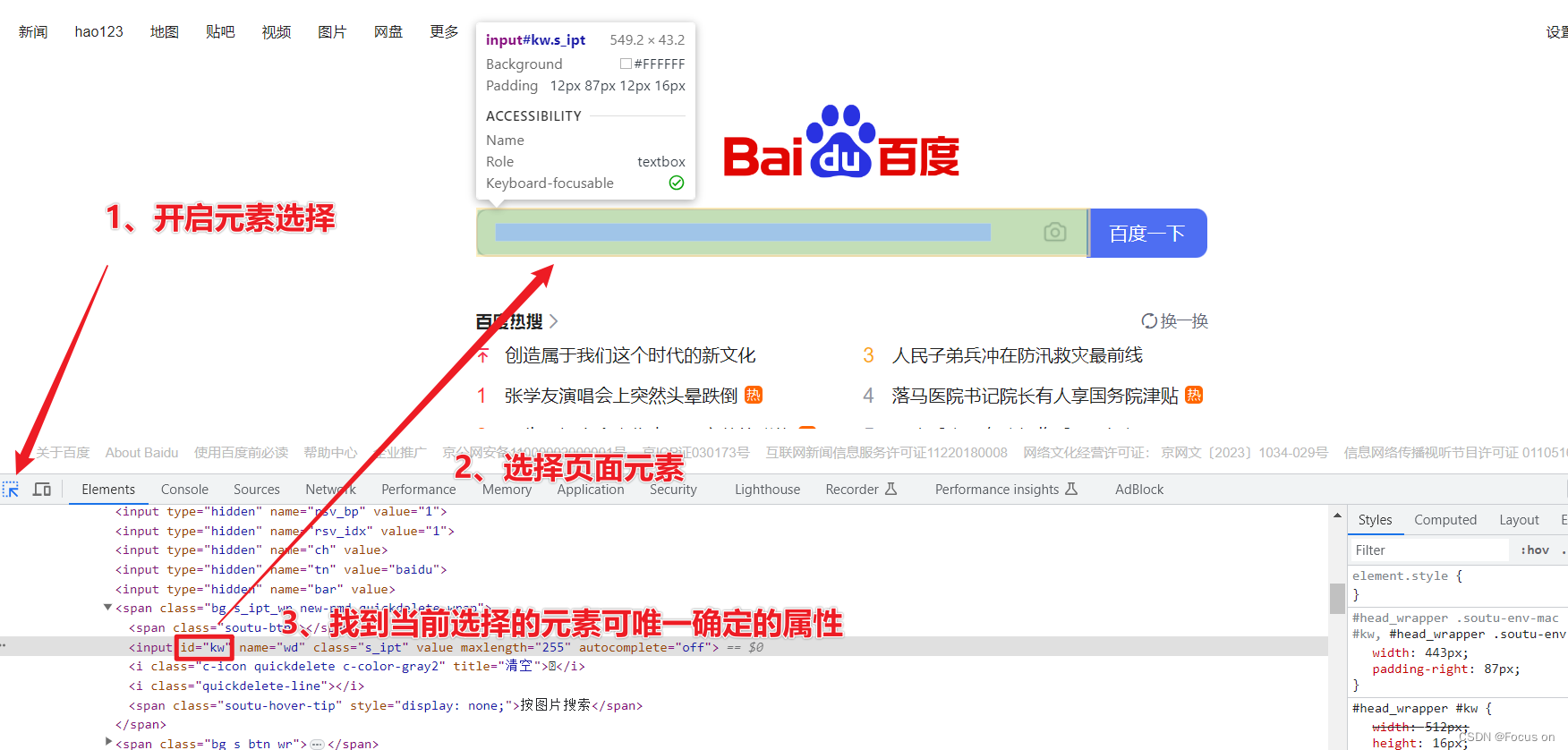
2、选择输入框并点击搜索按钮
①、打开百度搜索;
②、打开开发者模式(F12 或者 Ctrl + Shift + I);
③、选择元素
选择内容输入框:
找到“百度一下”按钮:
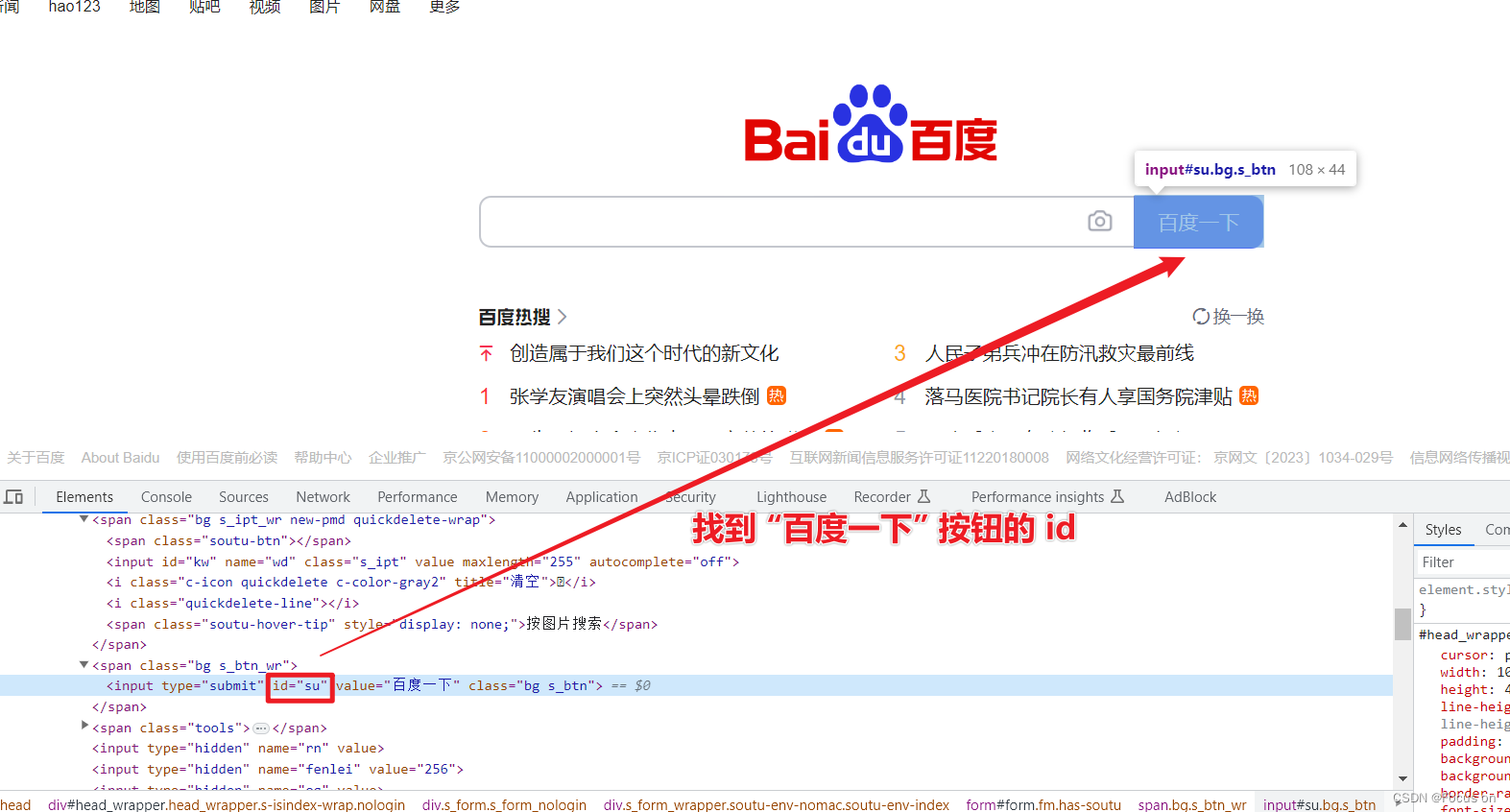
因此我们的代码可以这样写:
# 1、配置要访问的地址信息
url = "https://www.baidu.com/"
# 打开对应的页面
driver.get(url)
# 2、找到对应的元素并进行操作
# 百度搜索框
select_tag = driver.find_element(By.ID, 'kw')
# 百度一下 按钮
submit_tag = driver.find_element(By.ID, 'su')
# 填写信息,并点击搜索按钮
select_tag.send_keys("树叶")
# 点击 "百度一下"
submit_tag.click()
3、常用的 Selenium 选择器
建议优先看官网内容,下方内容基本来自官网,建议使用统一的选择器,例如 XPath 选择器 (XPath 选择器)
0、链接
1、官方链接
1、Class 选择器
# <input class="information" type="text" id="fname" name="fname" value="Jane">
# CLASS_NAME 使用唯一类的名称
driver.find_element(By.CLASS_NAME, "information")
2、CSS 选择器
# <input class="information" type="text" id="fname" name="fname" value="Jane">
# CSS_SELECTOR 这里使用的是 ID 属性
driver.find_element(By.CSS_SELECTOR, "#fname")
3、ID 选择器
# <input class="information" type="text" id="lname" name="lname" value="Doe">
# 一般情况下 ID 是比较好的选择,因为 ID 一般都是唯一的
driver.find_element(By.ID, "lname")
4、NAME 选择器
# <input type="checkbox" name="newsletter" value="1" />
driver.find_element(By.NAME, "newsletter")
5、link text 选择器(全部文本)
# <a href ="www.selenium.dev">Selenium Official Page</a>
driver.find_element(By.LINK_TEXT, "Selenium Official Page")
6、partial link text 选择器 (部分文本)
# <a href ="www.selenium.dev">Selenium Official Page</a>
driver.find_element(By.PARTIAL_LINK_TEXT, "Official Page")
7、tag name 选择器
# <a href ="www.selenium.dev">Selenium Official Page</a>
driver.find_element(By.TAG_NAME, "a")
8、xpath 选择器 (建议使用)
# <input type="radio" name="gender" value="f" />Female <br>
driver.find_element(By.XPATH, "//input[@value='f']")
4、Selenium 其他使用技巧(推荐)
1、使用 Selenium 中的时间等待方法
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
...
driver = webdriver.Chrome(options=options)
# 设置一个全局的 wait,如果在 wait 时间段内元素就找到了,那么就直接开始后续的执行
# 最大等待 10s 时间,在这 10s 内每 0.5s 尝试一次
wait = WebDriverWait(driver, 10, 0.5)
# 等待直到页面元素加载完成(例如这个案例就是等待页面上出现 NAME 为 username 的元素出现之后,就会开始后续操作)
wait.until(EC.presence_of_element_located((By.NAME, "username")))
5、关于 Xpath 的详细使用说明
0、整体的 txt 文本内容
text = '''
<html>
<body>
<style>
.information {
background-color: white;
color: black;
padding: 10px;
}
</style>
<h2>Contact Selenium</h2>
<form action="/action_page.php">
<input type="radio" name="gender" value="m" />Male
<input type="radio" name="gender" value="f" />Female <br>
<br>
<label for="fname">First name:</label><br>
<input class="information" type="text" id="fname" name="fname" value="Jane"><br><br>
<label for="lname">Last name:</label><br>
<input class="information" type="text" id="lname" name="lname" value="Doe"><br><br>
<label for="newsletter">Newsletter:</label>
<input type="checkbox" name="newsletter" value="1" /><br><br>
<input type="submit" value="Submit">
</form>
<p>To know more about Selenium, visit the official page
<a href ="www.selenium.dev"> Selenium Official Page </a>
<a href ="www.selenium.dev"> test002 《a》 </a>
<a href ="www.selenium.dev"> test003 《a》 </a>
<span>
test001 《p》
<a id='parentSpan' href ="www.selenium.dev"> test001 《a》 </a>
<a id='parentSpan' href ="www.selenium.dev"> test004 《a》 </a>
</span>
</p>
<p>
<div class="div01 div02"> div demo </div>
<div class="div01 div03"> div demo2 </div>
</p>
</body>
</html>
'''
1、匹配所有节点
# 1、匹配所有节点
result = html.xpath('//*')
# 将会把所有的节点都打印出来
for result_inner in result:
print(etree.tostring(result_inner, encoding='unicode', method='html'))
2、匹配所有的 input 标签
# 2、匹配所有的 input 标签
result = html.xpath('//input')
# 将会把所有的节点都打印出来
for result_inner in result:
print(etree.tostring(result_inner, encoding='unicode', method='html'))
运行结果:
<input type="radio" name="gender" value="m">Male
<input type="radio" name="gender" value="f">Female
<input class="information" type="text" id="fname" name="fname" value="Jane">
<input class="information" type="text" id="lname" name="lname" value="Doe">
<input type="checkbox" name="newsletter" value="1">
<input type="submit" value="Submit">
3、匹配到 p 标签下的 a 标签
# 3、匹配到 p 标签下的 a 标签
result = html.xpath('//p/a')
# 将会把所有的节点都打印出来
for result_inner in result:
print(etree.tostring(result_inner, encoding='unicode', method='html'))
运行结果:
<a href="www.selenium.dev"> Selenium Official Page </a>
<a href="www.selenium.dev"> test002 《a》 </a>
<a href="www.selenium.dev"> test003 《a》 </a>
4、匹配到 p 标签下所有的 a 标签
# 4、匹配到 p 标签下所有的 a 标签
result = html.xpath('//p//a')
# 将会把所有的节点都打印出来
for result_inner in result:
print(etree.tostring(result_inner, encoding='unicode', method='html'))
运行结果:
<a href="www.selenium.dev"> Selenium Official Page </a>
<a href="www.selenium.dev"> test002 《a》 </a>
<a href="www.selenium.dev"> test003 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test001 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test004 《a》 </a>
5、根据 id 为 parentSpan 匹配到 a 标签
# 5、根据 id 为 parentSpan 匹配到 a 标签
result = html.xpath('//a[@id="parentSpan"]')
# 将会把所有的节点都打印出来
for result_inner in result:
print(etree.tostring(result_inner, encoding='unicode', method='html'))
运行结果:
<a id="parentSpan" href="www.selenium.dev"> test001 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test004 《a》 </a>
6、匹配到以 span 标签为父标签的 a 标签
# 6、匹配到以 span 标签为父标签的 a 标签
result = html.xpath('//a[@id="parentSpan"]/..')
# 将会把所有的节点都打印出来
for result_inner in result:
print(etree.tostring(result_inner, encoding='unicode', method='html'))
运行结果:
<span>
test001 《p》
<a id="parentSpan" href="www.selenium.dev"> test001 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test004 《a》 </a>
</span>
7、获取文本
# 7、获取文本
result = html.xpath('//a[@id="parentSpan"]/text()')
print(result)
运行结果:
[' test001 《a》 ', ' test004 《a》 ']
8、获取 href 属性
# 8、获取 href 属性
result = html.xpath('//a[@id="parentSpan"]/@href')
print(result)
运行结果:
['www.selenium.dev', 'www.selenium.dev']
9、获取多属性元素
# 没有匹配到任何数据
result_first = html.xpath('//div[@class="div01"]')
result_second = html.xpath('//div[contains(@class, "div01")]')
# 将会把所有的节点都打印出来
for result_inner in result_first:
print(etree.tostring(result_inner, encoding='unicode', method='html'))
# 将会把所有的节点都打印出来
for result_inner in result_second:
print(etree.tostring(result_inner, encoding='unicode', method='html'))
运行结果:(注意下面的结果中是第二条匹配到的结果,第一条没有匹配到)
<div class="div01 div02"> div demo </div>
<div class="div01 div03"> div demo2 </div>
10、多属性匹配
# 10、多属性匹配
result = html.xpath('//div[contains(@class, "div01") and contains(@class, "div02")]')
# 将会把所有的节点都打印出来
for result_inner in result_second:
print(etree.tostring(result_inner, encoding='unicode', method='html'))
运行结果:
<div class="div01 div02"> div demo </div>
11、匹配某类节点中的某个特定次序的元素
1、匹配所有
result = html.xpath('//a')
# 将会把所有的节点都打印出来
for result_inner in result_second:
print(etree.tostring(result_inner, encoding='unicode', method='html'))
运行结果:
<a href="www.selenium.dev"> Selenium Official Page </a>
<a href="www.selenium.dev"> test002 《a》 </a>
<a href="www.selenium.dev"> test003 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test001 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test004 《a》 </a>
2、匹配第 1 个元素
(注意这里不是从 0 开始的,而是从 1 开始的)
【如果存在多组不同一个级别的 a 标签,这种匹配会匹配到多组数据的第1个】
# 匹配第 1 个元素(注意这里不是从 0 开始的,而是从 1 开始的)
result = html.xpath('//a[1]')
运行结果:
<a href="www.selenium.dev"> Selenium Official Page </a>
<a id="parentSpan" href="www.selenium.dev"> test001 《a》 </a>
3、匹配最后一个元素(以组为单位)
# 匹配到最后一个元素
result = html.xpath('//a[last()]')
运行结果:
<a href="www.selenium.dev"> test003 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test004 《a》 </a>
4、匹配倒数第3个元素(以组为单位)
result = html.xpath('//a[last() - 2]')
运行结果:==注意:==上面的元素总共分为两组,第一组为前三个,第二组为后两个,倒数第三个只有第一组有(参考全部运行结果)
<a href="www.selenium.dev"> Selenium Official Page </a>
5、匹配大于2的(以组为单位)
# 匹配大于2的
result = html.xpath('//a[position() > 2]')
运行结果:
<a href="www.selenium.dev"> test003 《a》 </a>
12、节点轴选择方式
1、获取祖先节点 ancestor
# ①、获取祖先节点 ancestor
result = html.xpath('//a[position() > 2]/ancestor::p')
运行结果:
<p>To know more about Selenium, visit the official page
<a href="www.selenium.dev"> Selenium Official Page </a>
<a href="www.selenium.dev"> test002 《a》 </a>
<a href="www.selenium.dev"> test003 《a》 </a>
<span>
test001 《p》
<a id="parentSpan" href="www.selenium.dev"> test001 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test004 《a》 </a>
</span>
</p>
2、获取被匹配到元素的属性值
# ②、获取被匹配到元素的属性值
# 这里 element 实际上是一个列表,所以没办法直接使用 attribute 进行更加详细的属性获取
element = html.xpath('//a[position() > 2]')[0]
result = element.xpath('attribute::*')
print(result)
运行结果:
['www.selenium.dev']
3、获取 p 标签下的 href 属性值为 www.selenium.dev 的 a 标签
# ③、获取 p 标签下的 href 属性值为 www.selenium.dev 的 a 标签
result = html.xpath('//p/child::a[@href="www.selenium.dev"]')
运行结果:
<a href="www.selenium.dev"> Selenium Official Page </a>
<a href="www.selenium.dev"> test002 《a》 </a>
<a href="www.selenium.dev"> test003 《a》 </a>
4、获取子孙节点
result = html.xpath('//p/descendant::a[@id="parentSpan"]')
运行结果:
<a id="parentSpan" href="www.selenium.dev"> test001 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test004 《a》 </a>
5、获取当前节点 之后的所有节点
# ⑤、获取当前节点之后的所有 节点
element = html.xpath('//a[text()=" test003 《a》 "]')
result = html.xpath('//a[text()=" test003 《a》 "]/following::*')
运行结果:
<span>
test001 《p》
<a id="parentSpan" href="www.selenium.dev"> test001 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test004 《a》 </a>
</span>
<a id="parentSpan" href="www.selenium.dev"> test001 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test004 《a》 </a>
<p></p>
<div class="div01 div02"> div demo </div>
<div class="div01 div03"> div demo2 </div>
6、获取当前节点之后的所有同级节点
# ⑥、获取当前节点之后的所有 同级节点
result = html.xpath('//a[text()=" test003 《a》 "]/following-sibling::*')
运行结果:
<span>
test001 《p》
<a id="parentSpan" href="www.selenium.dev"> test001 《a》 </a>
<a id="parentSpan" href="www.selenium.dev"> test004 《a》 </a>
</span>














 949
949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









