









1、下载PaddleOCR
https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_ch/installation.md
https://github.com/PaddlePaddle/PaddleOCR
2、安装PaddlePaddle
https://paddlepaddle.org.cn/install/quick
3、部署
https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#windows
4、安装gflags、glog
遇到问题:无法打开包括文件: “glog/logging.h”:
解决办法:安装glog
https://blog.csdn.net/lostcorner/article/details/110576179
5、错误
遇到问题:无法打开包括文件:“dirent.h":No such file or directory
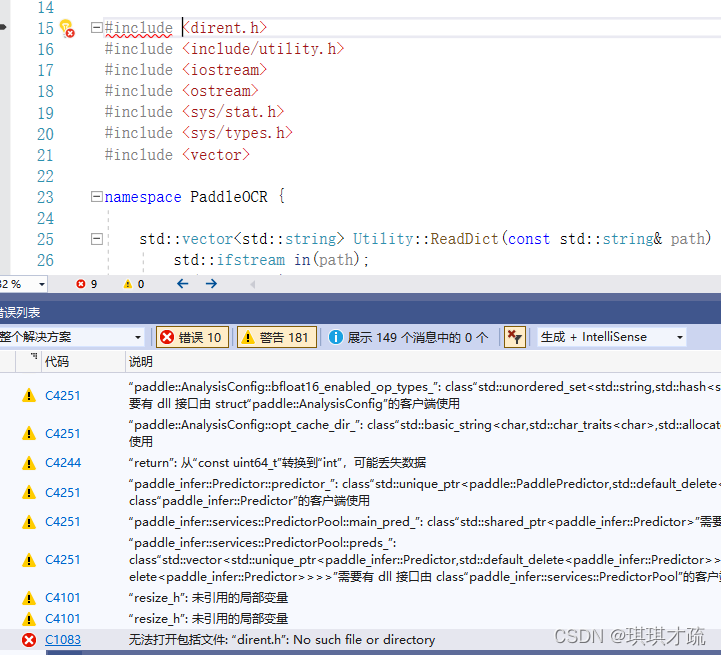
解决办法:下载dirent,引用到工程
https://github.com/tronkko/dirent















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









