







1.简介
想要一个深度学习模型的效果出众,很重要的两个点是数据和结构。结构上的优化,可以通过研究backbone和neck的特点进行调整,门槛较低,但是从数据的角度去增强模型,其门槛和成本就高很多了。为了获得一个泛化能力强、精度高的模型,往往需要大量的标注数据,但是短时间内又无法获取,该怎么办呢?这个时候,就要使用迁移学习的思路。
迁移学习的其中一种普遍的用法,是用一个预训练好的图像分类模型,转化成目标检测模型、或者关键点回归模型,这么做的原因在于图像分类模型可以用图像分类的数据集来训练,我们比较容易获得大量的图像分类数据集,比如我们熟悉的imagenet,而目标检测数据集的图片数量则少很多,关键点回归数据集的样本数量更少,如果不通过迁移学习,直接用这些少量的图片进行训练,效果就没法达到想要的精度,还有可能造成过拟合的现象。因此,用imagenet预训练的模型来进行迁移学习,对模型的泛华能力和精度的提升都有重要意义。
下面我将分三个部分依次介绍这三类任务的具体内容,以及它们之间该如何进行迁移学习。
2.图像分类模型
本节讨论的是用深度学习网络来做图像分类任务,先从一个典型的网络vggnet开始讲解。下图是vggnet的网络结构图。
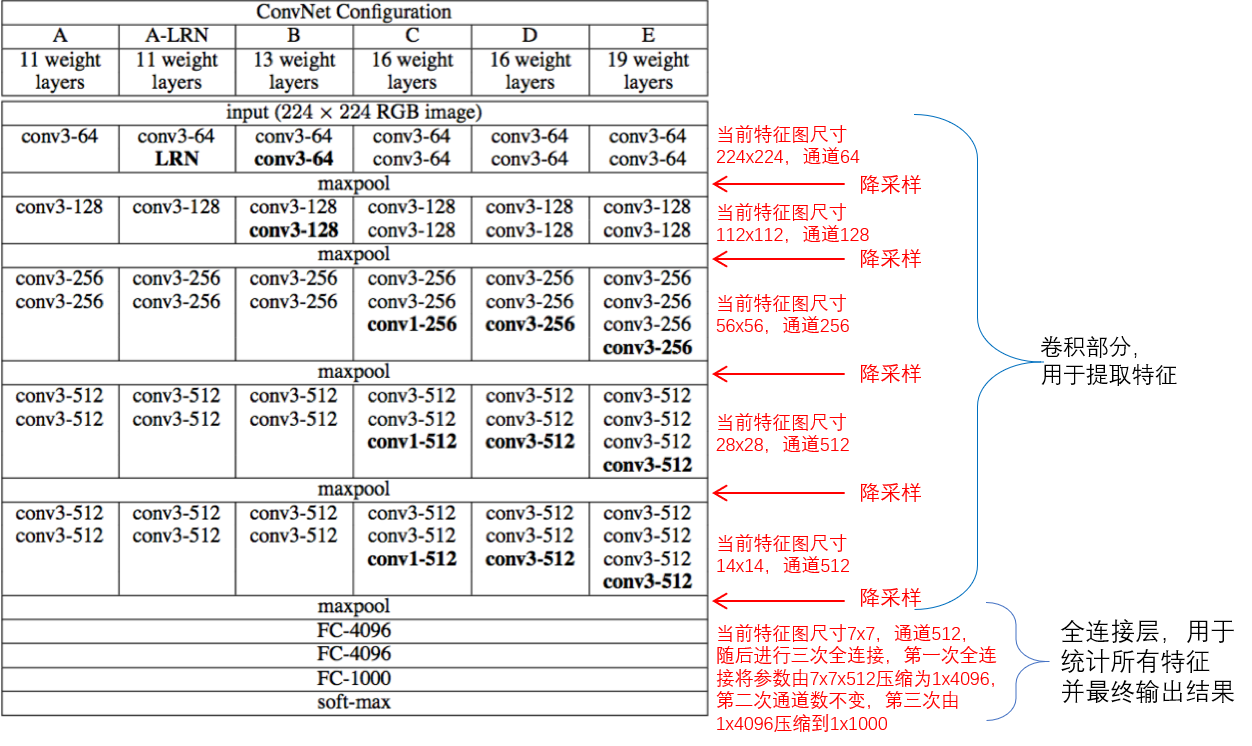
可以看到,图像在网络中一共经过了5次降采样,特征图分辨率也由224x224降到了7x7,而随着特征图分辨率的降低,通道数是翻倍增长的,这么做的目的是尽可能的提取和保留图像的语义信息,也就是逐渐将图像的纹理特征组合成类别特征。提取后的特征经过全连接层,最终输出为1x1000,代表了该图可能属于imagenet的1000个类别的概率,最后经过softmax函数修正后输出。全连接层之间一般是线性函数连接,两个FC-4096的意义在于更加充分地整合图像的特征,增强网络的表达能力。
了解了vggnet的网络结构之后,思考一个问题:这样的结构,其可迁移的部分有哪些呢?或者说,我们该如何修改它,使其能够转为关键点回归任务和目标检测任务所需的结构呢&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









