







 本文详细介绍了Picoc编译器的脚本运行模式,从系统头文件处理到脚本的解析与执行。在脚本模式下,Picoc首先处理系统头文件,然后解析并执行用户指定的脚本文件。解析过程中涉及词法分析、函数定义、表达式处理等多个环节,通过PicocParse()函数实现脚本的解释和执行。文章深入探讨了关键函数如ParseStatement()的工作原理,涵盖了条件语句、循环语句等控制结构的处理流程。
本文详细介绍了Picoc编译器的脚本运行模式,从系统头文件处理到脚本的解析与执行。在脚本模式下,Picoc首先处理系统头文件,然后解析并执行用户指定的脚本文件。解析过程中涉及词法分析、函数定义、表达式处理等多个环节,通过PicocParse()函数实现脚本的解释和执行。文章深入探讨了关键函数如ParseStatement()的工作原理,涵盖了条件语句、循环语句等控制结构的处理流程。
Picoc编译器支持程序、脚本和终端三种运行模式。这篇文章主要对picoc的脚本解析和运行流程做一个整理,对其中涉及到的知识点做一些简要的解释和分析。
一、脚本运行模式
脚本模式的启动方式是通过-s参数实现。
./picoc -s test.c
该模式首先调用PicocIncludeAllSystemHeaders()函数进行系统头文件处理,然后进入到执行脚本文件处理函数PicocPlatformScanFile()的for循环,直至所有指定脚本执行完毕。所有脚本执行完毕后会调用PicocCleanup()执行清理并退出。
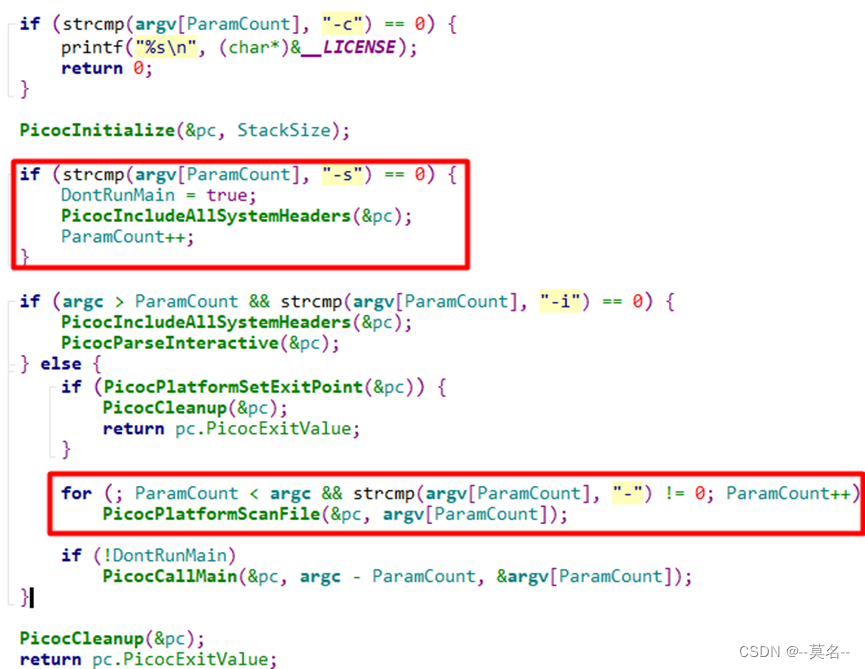
二、系统头文件处理
这里主要是调用IncludeFile()函数对初始化时包含的所有头文件(#include表达式)进行处理,即遍历Parser的包含文件列表IncludeLibList(预定义的库或实际的文件内容),并重复进行以下工作:
a.检查头文件是否已定义,未定义则进行注册,否则跳过。避免重复包含相同的库文件。
b.检查头文件是否需要运行自己的启动函数,需要则执行。
c.检查头文件中是否存在类型定义等,并调用PicocParse()进行处理。
d.检查头文件中是否存在库函数FuncList,调用LibraryAdd()对所有库函数进行处理。
LexAnalyse()àLexTokenize():对库函数进行词法分析,生成令牌并分配栈空间。返回值Tokens为指向令牌存储的栈地址。
LexInitParser()将函数信息存储到Parser结构中。
TypeParse()对库函数的类型进行解析,包含标识符的完整声明。
ParseFunctionDefinition()解析函数定义并保存。
三、脚本解释及执行
系统头文件处理完成后,调用PicocPlatformScanFile()函数对用户指定的每一个脚本文件进行解析和执行,主要工作包括:
(1)读取指定的脚本文件PlatformReadFile()。
该函数打开用户指定的脚本文件,并读取到临时分配的内存ReadText中。这里用到了C语言的stat()和fread函数,整个文件按文件大小的字节数读取到ReadText中,并在内存的结尾处加了’\0’,因此ReadText的大小是文件字节数加1。
读取完成后将ReadText中的开头的注释部分“#!”去掉(以空格字符代替)。
后续代码会将读到的文件中的“#”和“!”用“/”代替。这里实际上存在重复处理,两段代码有一段就可以了。
(2)调用PicocParse()对读取到的脚本文件进行解析和执行。
由于Picoc的解释和执行放在一起,这些工作都是在这个函数中实现的,函数定义如下:
void PicocParse(Picoc *pc, const char *FileName, const char *Source,
int SourceLen, int RunIt,int CleanupNow, int CleanupSource, int EnableDebugger)
下面我们仔细分析一下调用时各个参数的状态,然后看看其在执行中都有什么作用。
PicocParse(pc, FileName, SourceStr, strlen(SourceStr), true, false,true, gEnableDebugger);
Picoc *pc:指向解释器结构的指针
const char *FileName:脚本文件名称
const char *Source:脚本文件内容
int SourceLen:脚本文件长度
int RunIt:是否执行标志。此处调用时为true
int CleanupNow:是否清除。此处调用时为false
int CleanupSource:是否清除源文件。此处调用时为true
int EnableDebugger:是否开启调试,这个可以不管。
前4个参数实际上是把总体数据以及需要处理的脚本文件内容传递给PicocParse()。
第5个参数为true用于标记表达式是需要执行的。
第6个参数为false表明需要为脚本分配内存并存储到pc中。
第7个参数为true表明为脚本新建记录结点用于退出时清除。
PicocParse()函数的主要流程如下:
首先调用TableStrRegister()注册基本文件,返回值为脚本文件名称。
调用LexAnalyse()àLexTokenize()对脚本文件进行词法分析。
调用LexInitParser()时,将令牌加入到Parser中,并将Mode标记为RunModeRun(解析并运行)。
循环调用ParseStatement()对脚本文件进行解释和执行,直至完成或报错。
解析出错则进行报错处理,否则调用HeapFreeMem()进行内存清除处理。
四、关键函数流程分析
1.ParseStatement()函数分析
ParseStatement()函数通过对Parser中的所有Token分类处理,解析所有表达式并存储到栈中,对需要执行的表达式进行执行并将结果同样存储到栈中。
主要流程如下:
a.TokenEOF
文件结束则退出运行。
b.Token标识处理(TokenIdentifier)
首先检查Token是否已定义,如果Token为Type_Type类型则调用ParseDeclaration()进行解释,完成后检查行结束标志“;”后退出;其它类型则进入步骤c。如果Token没有定义,则判断是否为标签(TokenColon),是则标记为Goto标签后退出(此处完成后不检查行结束标志),否则进入步骤c。
c.表达式处理
对于变量和函数定义语句,会在ParseStatement()的TokenIdentifier之后处理。对于赋值语句,在经过TokenIdentifier处理后,直接进入其后的表达式处理流程中。
表达式处理的主要分类如下:
(1)TokenAsterisk(*、&、++、--、()
这几个运算符通常代表后续大概率是表达式,因此这里会调用ExpressionParse()进行表达式处理。
(2)TokenLeftBrace({)
调用ParseBlock()处理程序块。
(3)TokenIf(if)
处理IF语句块,完成后不检查行结束标志“;”。包括Token“(”处理、条件判断处理、Token“)”处理、条件满足分支语句处理、Token“else”处理、“else”分支语句处理。
其中,Token的处理主要由LexGetToken()函数实现(#if也由该函数处理)。条件判断表达式由ExpressionParseInt()函数处理。条件判断结果及各类相关分支语句的执行由ParseStatementMaybeRun()函数处理。在分支语句处理中,会递归调用ParseStatement()对其中表达式进行处理。
(4)TokenWhile(while)
处理while语句块,完成后不检查行结束标志“;”。首先调用ParserCopyPos()把Parser的当前位置(脚本文件的文件指针位置、行号、行字符位置等)做一个备份,然后进入do-while循环处理while循环的内部语句块。循环内部处理过程与IF语句类似,只是每次执行前会将Parser重置为执行前备份的位置。
调用do-while语句对条件进行循环检查直至满足或执行到退出语句。
(5)TokenDo(do)
处理do-while语句块,完成后检查行结束标志“;”。处理流程与while语句类似。
(6)TokenFor(for)
调用ParseFor()处理语句块,完成后不检查行结束标志“;”。for语句块的处理要更加复杂一点。首先需要对for后面的关键字和条件表达式进行解析,然后根据条件判断是否进入for循环体。条件满足时进入for循环内部,采用while循环对for内部的语句块进行处理,这个流程跟上面的几个关键字处理思路基本一致。
(7)TokenSemicolon(;)
这里没有需要处理的,直接跳出。
(8)TokenIntType等基本数据类型(int、float、double、struct、extern…)
调用ParseDeclaration()解析数据类型定义,完成后检查行结束标志“;”。数据类型的处理分为变量定义和函数,处理过程其实就是分别对数据类型或返回值类型、变量或函数名称以及变量赋值的处理。内部涉及的主要函数如下:
TypeParseFront():变量及函数返回值类型的处理,返回变量或函数返回值的基本类型以及是否为静态变量static。
TypeParseIdentPart():获得变量或函数的名称及类型
ParseFunctionDefinition():函数处理。
VariableDefineButIgnoreIdentical():变量定义处理。如果是静态变量则在全局列表中查找,查找是先调用TableStrRegister()获取变量的注册名,然后调用TableGet()根据注册名在pc->GlobalTable中查找,找不到则调用函数VariableAllocValueFromType()在全局变量表中注册该静态变量,并调用函数TableSet()将值存储到其中。然后调用函数VariableDefinePlatformVar()在当前作用域中创建一个镜像变量。不是静态变量,则根据当前作用域选择在pc->GlobalTable还是pc->TopStackFrame->LocalTable中查找该变量,找到了则返回变量地址。未找到则调用函数VariableDefine()注册该变量。
ParseDeclarationAssignment():变量赋值处理。数组调用ParseArrayInitializer()处理。表达式调用ExpressionParse()处理,然后检查Parser->Mode是否为RunModeRun,是则调用ExpressionAssign()给变量赋值,调用VariableStackPop()将变量出栈。
(9)TokenHashDefine(#define)
调用ParseMacroDefinition()解析宏定义,完成后不检查行结束标志“;”。
(10)TokenHashInclude(#include)
调用IncludeFile()解析包含的头文件,完成后不检查行结束标志“;”。
(11)TokenSwitch(switch)
处理switch语句,完成后不检查行结束标志“;”。调用ExpressionParseInt()处理判断条件。调用ParseBlock()处理switch的语句块。
(12)TokenCase(case)
处理case语句,完成后不检查行结束标志“;”。调用ExpressionParseInt()处理判断条件。
(13)TokenDefault(default)
处理default语句,完成后不检查行结束标志“;”。
(14)TokenBreak(break)
切换运行模式为RunModeBreak。
(15)TokenContinue(continue)
切换运行模式为RunModeContinue。
(16)TokenReturn(return)
运行模式为RunModeRun则检查栈指针来决定如何退出函数处理,否则调用ExpressionParse()解析表达式。
(17)TokenTypedef(typedef)
调用ParseTypedef()来处理类型定义。
(18)TokenGoto(goto)
处于运行模式RunModeRun则在Parser中记录需要寻找的标签,然后将运行模式变为RunModeGoto。
(19)TokenDelete(delete)
删除指定的函数名或变量名,并清除其占用的内存。
2.表达式处理函数
(1)ExpressionParse()
表达式解析处理,分为运算符处理、表达式执行和表达式结果返回三部分。运算符处理位于do-while语句内,对一个表达式进行处理,包括前缀运算符处理、中缀或后缀运算符处理、标识符(变量、函数或宏)处理、常量处理、类型定义处理以及非表达式Token处理等部分。
表达式执行是通过ExpressionStackCollapse()函数实现。函数中会根据表达式中操作符类型(OderPrefix、OrderInfix、OrderPostfix)、优先级以及是否为运行模式(RunModeRun)来决定是对表达式进行求解处理还是将表达式保存到栈中并返回。
表达式结果返回要判断当前表达式是否为RunModeRun模式,是则将位于栈顶的表达式值返回,然后执行“ExpressionStack结构”出栈处理,保留栈中表达式结果的存储位置;否则直接执行“ExpressionStack结构+Value结构+StackTop->Val结构”的出栈处理,即清除该表达式在栈中的所有内存。
在ExpressionParse()函数处理完表达式并返回表达式结果后,如果Parser->Mode为RunModeRun,则调用VariableStackPop()函数执行出栈动作,将表达式相关内存清除。
(2)ExpressionParseInt()
处理用在if、for、do、while、switch、case之后的条件判断表达式。
(3)ParseTypedef
解析typedef声明表达式。其中调用TypeParse()解析类型定义表达式。
(4)ParseMacroDefinition()
解析宏定义语句(以“#define”开头的表达式)并将其存储以备后续使用。
(5)ExpressionAssign()
处理函数中返回时的赋值过程。针对各种数据类型分别进行赋值处理,包括基本数据类型、指针、数据、结构等。
3.语句块处理函数
(1)ParseDeclaration()
处理变量声明表达式或函数块。
ParseFunctionDefinition()解析函数定义并将其存储以备以后使用。
ParseDeclarationAssignment()为变量赋初始值,其中数组采用ParseArrayInitializer()进行初始化,普通表达式使用ExpressionParse()和ExpressionAssign()进行处理。
(2)ParseStatementMaybeRun()
解析语句块,并递归调用ParseStatement()执行调用条件为True的语句。
(3)ParseBlock()
解析代码块并返回其返回的模式。其中根据运行模式递归调用ParseStatement()。
(4)ParseFor()
解析for语句块。分为条件判断表达式和循环体解析两部分。循环体解析过程与前面处理while、if等语句块的流程类似。
五、结论
解析的重点其实就是各种类型表达式的处理及存储。脚本处理是将脚本文件内容逐行解析后存储到变量ParseState结构(Parser)中,解析过程中根据Token类型设置运行标志(Parser->Mode),在处理到需要执行的语句时对相应的表达式或函数根据预定规则执行并将结果存储到Parser中或直接输出。
-----------------------------------
原创不易,请多支持!

















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









