







在一次数据的需求中,去用order by+limit 1和 max两种方式求数据的最大值时,发现在同一过滤条件下order by limit 1执行时间要比max快。然后从一下两个角度对问题进行来思考。
1.查看执行计划:
a.max查询计划

b.order by+limit 1查询计划
 其中Extra是指执行情况的描述和说明。max的extra对应的值是 Select tables optimized away
其中Extra是指执行情况的描述和说明。max的extra对应的值是 Select tables optimized away
order by + limit 的extra选项对应的值是 Using index
extra项解释:
Select tables optimized away:
使用某些聚合函数(比如 max、min)来访问存在索引的某个字段
来自于mysql官网对Select tables optimized away的描述:
For explains on simple count queries (i.e. explain select count(*) from
people) the extra section will read "Select tables optimized away.
" This is due to the fact that MySQL can read the result directly from
the table internals and therefore does not need to perform the select.Using index:直接在主键索引上完成查询和所有数据的获取。
2.order by和where的执行顺序是否是先做的order by,后使用where过滤。
结论:因为max和order by+limit 1都是使用的主键值进行查询,而主键在mysql中是b+树。在叶子节点主键id本身就是按从小大的顺序排列的。所以在查询中会出现以下两种情况:
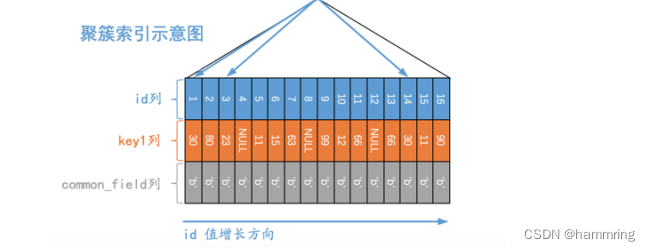
a.如果是查询普通列(非主键且该值没有索引列)条件,max()的查询速度要优于order by+limit 1,原因是从explain的执行计划中可以看出:order by+limit 1使用了索引,而使用max根本没有遍历表或索引就返回数据了
b.如果是主键值的查询可以分两种情况来讨论:
1.)如果是max()和order by速度的比较,max()的速度要比order by快,order by会把所有查询到的结果并展示出来。
select max(id) from table_name:
select id from table_name order by id desc;2.)如果是max()和order by+limit 1 速度的比较,order by+limit 1会在查到第一条数据时返回结果。而不是对整个结果进行排序。如果使用索引来完成排序,这将非常快。如果你将LIMIT row_count子句与ORDER BY子句组合在一起使用的话,一旦找到第一个row_count之后,MySQL不会对结果集的任何剩余部分进行排序。这种行为的一种表现形式是,一个ORDER BY查询带或者不带LIMIT可能返回行的顺序是不一样的。
参考资料:
我们都是小青蛙MySQL系列文章
mysql官方文档

















 2660
2660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









