









1、分析流程
https://www.geetest.com/adaptive-captcha-demo
2、进入网页后,点击配置,选择文字点选验证。打开开发者人员工具(F12)进行抓包,刷新页面。可以找到一个 /pre_auth 和 /load 的请求。
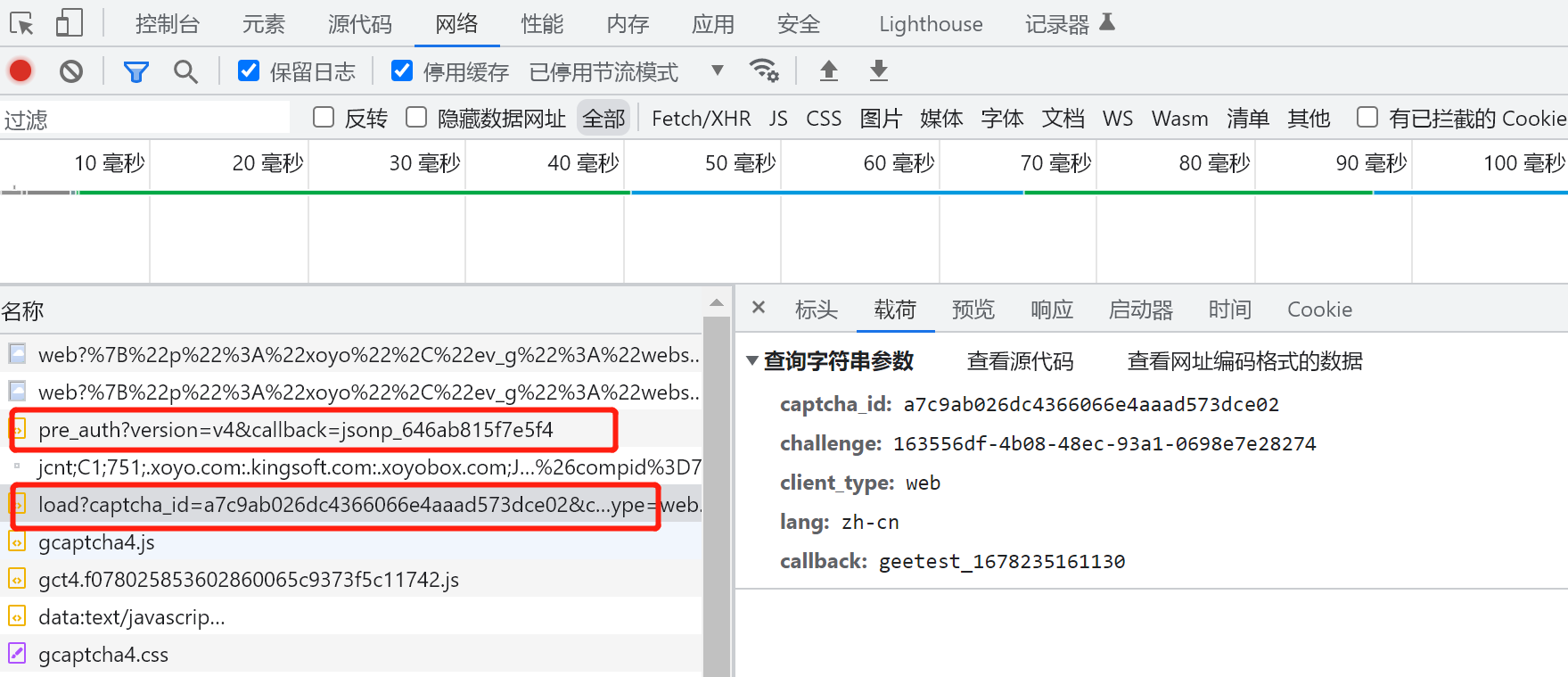
/pre_auth 类似获取一个当前设备ID或者请求获取验证码的标识ID来用,简单说,就是为了获取captcha_id,方便load 加载验证码用的一个入参
3、分析 /load
#请求参数说明
captcha_id : (/pre_auth 获取得到)
challenge: (uuid)
client_type: web #定值
lang: zh-cn #定值
callback: geetest_{utc} #回调时间戳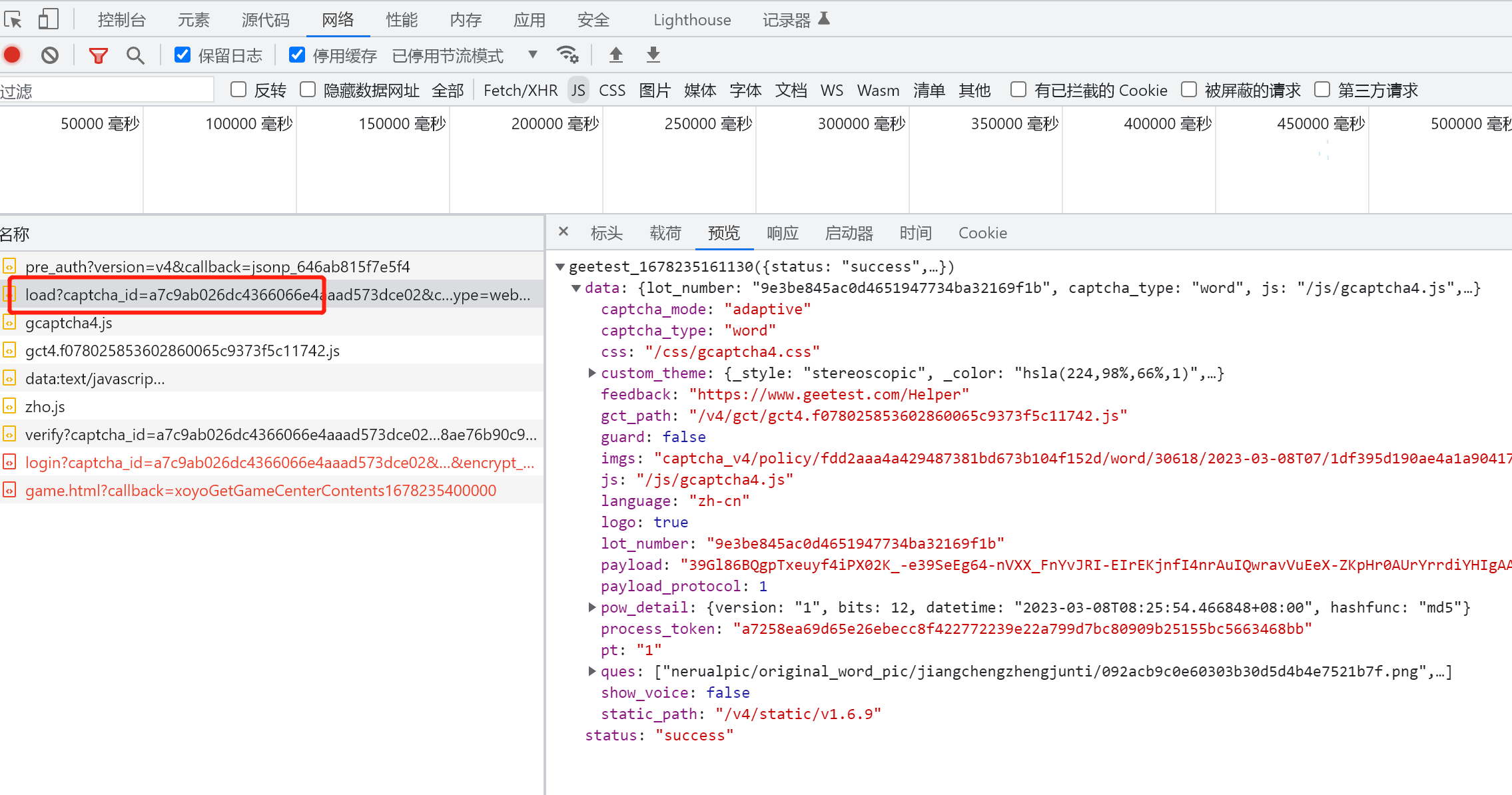
#响应参数说明
imgs: 需要识别的图片地址
ques: 目标文字点选的次序
captcha_type: 验证码类型 word为文字,nine为九宫格
gct_path: gct4 文件路径
lot_number: 计算w的关键参数
payload: (verify) 请求所需参数
pow_detail: 关键参数
process_token: (verify) 请求所需参数4、load请求之后就是到关键的verify请求验证了

5、w值分析
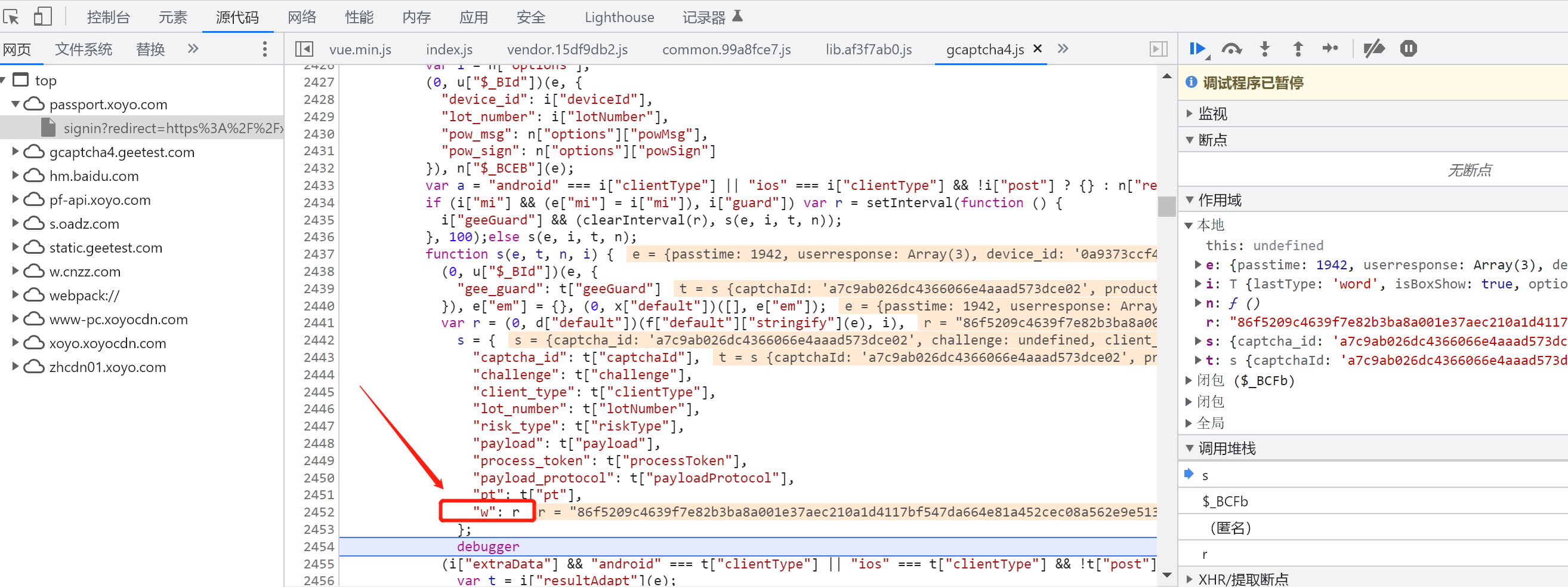
w值,简单说就是根据图识的结果,进行加密计算得到的最终密文,再拼接上其它参数。请求verify之后,整个流程就算请求结束了。
这里可能朋友们还会遇到两步:
第一步,拿到gcapchat4.js是一个乱码js文件(不是明文)。需要做反混淆处理。
第二步,关于文字图像识别的部分,需要OCR。这里可以采用CNN、YOLOv3等等AI模型去搞定;
以上两步需要的话我会在后续更新如何解析转化(网上也有类似例子,可以自己搜搜看);
下一期讲解w值的跟栈分析。
技术交流与资源分享(博主Q微同号: 446794914),感兴趣的朋友欢迎交流。















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









