







学习网址:https://tf.wiki/zh/basic/basic.html
考虑一个实际问题,某城市在 2013 年 - 2017 年的房价如下表所示:
| 年份 | 2013 | 2014 | 2015 | 2016 | 2017 |
| 房价 | 12000 | 14000 | 15000 | 16500 | 17500 |
现在,我们希望通过对该数据进行线性回归,即使用线性模型
y=aX+b
来拟合上述数据,此处 a 和 b 是待求的参数。
import tensorflow as tf
import numpy as np
#归一化
X_raw=np.array([2013,2014,2015,2016,2017],dtype=np.float32)
Y_raw=np.array([12000,14000,15000,16500,17500],dtype=np.float32)
X=(X_raw-X_raw.min())/(X_raw.max()-X_raw.min())
Y=(Y_raw-Y_raw.min())/(Y_raw.max()-Y_raw.min())
#初始化自变量
X=tf.constant(X)
Y=tf.constant(Y)
#变量a,b为0
a=tf.Variable(initial_value=0.)
b=tf.Variable(initial_value=0.)
# print(X) 输出可以看到他的类型,检查一下是否匹配,不匹配会报InvalidArgumentError错误
# print(a)
# print(b)
variable=[a,b]
num_epoch=100 #迭代次数
#声明了一个梯度下降 优化器 (Optimizer),其学习率为 5e-4。
#优化器可以帮助我们根据计算出的求导结果更新模型参数,
#从而最小化某个特定的损失函数
optimizer=tf.keras.optimizers.SGD(learning_rate=5e-4)
for e in range(num_epoch):
# 使用tf.GradientTape()记录损失函数的梯度信息
with tf.GradientTape() as tape:
y_pred=a*X+b
#损失函数
loss=tf.reduce_sum(tf.square(y_pred-Y))
#Tensorflow自动计算损失函数关于自变量的梯度值
grads=tape.gradient(loss,variable)
# TensorFlow自动根据梯度更新参数
optimizer.apply_gradients(grads_and_vars=zip(grads,variable))
print(a,b)
zip() 函数
是 Python 的内置函数。用自然语言描述这个函数的功能很绕口,但如果举个例子就很容易理解了:
如果 a = [1, 3, 5], b = [2, 4, 6],那么 zip(a, b) = [(1, 2), (3, 4), ..., (5, 6)] 。
即 “将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表”,和我们日常生活中拉上拉链(zip)的操作有异曲同工之妙。在 Python 3 中, zip() 函数返回的是一个 zip 对象,本质上是一个生成器,需要调用 list() 来将生成器转换成列表。
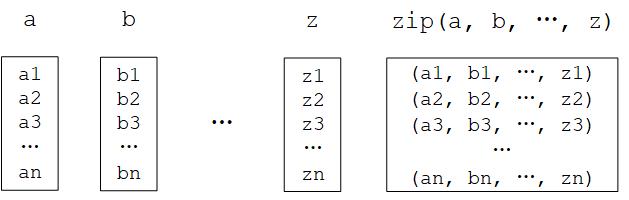
Python 的 zip() 函数图示















 208
208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









