







看博客好多人都说这本来应该在数据结构里边学,奈何我一点印象都没有,估计当时老师也跳过了。然后今天从9点看到现在,好像才大致懂了
emmm,然后,我在这个算法上边遇到的第一个坎,竟然是分不清楚文本串(test)和模式串(pattern)??算法里边没说清楚next是对谁求得。这里明确一下:
- 模式串应该是短的那个,求next数组的对象是模式串
目录
字符串的前缀和后缀:
先理解字符串的前缀和后缀
- 前缀:除字符串的最后一个字符外,字符串的所有头部子串
- 后缀:除字符串的第一个字符外,字符串的所有尾部子串
举一个例子来看
字符串abcjkdabc
- 前缀有[abcjkdab,abcjkda,abcjkd,abcjk,abcj,abc,ab,a]

- 后缀有[bcjkdabc,cjkdabc,jkdabc,kdabc,dabc,abc,bc,c]

该字符串前缀与后缀相同的最大长度为3,即abc。
这一概念必须理解,在下边的next求解中会用到
暴力求解算法
#include<iostream>
#include<string.h>
#include<string>
using namespace std;
int ViolentMatch(char* s,char* p){
int slen=strlen(s);
int plen=strlen(p);
int i=0,j=0;
while(i<strlen(s)&& j<strlen(p)){
if(s[i]==p[j]){ //成功匹配
i++;
j++;
}
else{ //未成功匹配,i回溯,j=0
i=i-j+1;
j=0;
}
}
if(j==strlen(p)){ //说明成功匹配
return i-j;
}
else{ //未成功匹配返回-1
return -1;
}
}
int main(){
char* s="BBC ABCDAB ABCDABCDABDE";char* p="ABCDABD";
//cout<<s<<p;
cout<<ViolentMatch(s,p);
return 0;
} KMP算法
1、求最大长度表
即寻找最长前缀后缀
如果给定的模式串是:“ABCDABD”,从左至右遍历整个模式串,其各个子串的前缀后缀分别如下表格所示:
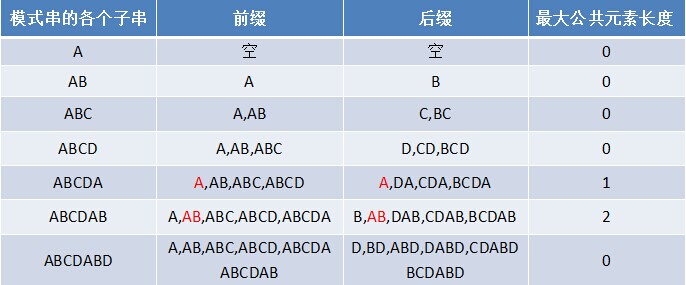
也就是说,原模式串子串对应的各个前缀后缀的公共元素的最大长度表为(下简称《最大长度表》):

那么·最大长度表有什么用呢?
最大长度表中每个元素long_length(j-1)=k的含义
- 定义:原模式串子串对应的各个前缀后缀的公共元素的最大长度。
- 在p[0]~p[j-1]中,p[0],p[1]……p[k-1]=p[j-k],……p[j-1],即这两个字符串是相等的,长度为k。这两个字符串以下记为p1、p2
- 看个图:如下,有蓝底的两块是完全相等的,每块长度为k

- k-1:与s2相同的字符串s1最后一个字符(即p[k-1])的下标,
- 如果 t[i]!=p[j] 接下来 j 应该移动到k,因为可以看出,由于p[j-k]~p[j-1]已经和t中对应位置成功匹配了,所以p[0]~p[k-1]也可以和刚刚t串的对应位置相匹配
总结一下我的理解:
前缀后缀和 t[i]!=p[j] 时 j 的移动是如何关联起来的?:
前缀必定从头(p[0])开始,后缀必定以最后一个字符(p[j-1])结束,如果前缀和后缀有长为k的公共元素,就是从 p[j-1] 往前的k个元素(p[j-k]~p[j-1]),与从字符串头开始的k个元素(p[0],p[1]……p[k-1])。此时如果 t[i]!=p[j] ,j往前移动 j-k 就可以到p[k],这样p[k]之前的k个元素就不用再去重新匹配了。而此处的 j-k 中的k,正是long_length(j-1)也是next(j)
这样就可以把next数组与j的移动联系起来啦
2、求next数组
他和long_length的关系红字已经解释了
最大长度表整体右移一位得到next数组,开头补-1,可以当成一个特殊标记,表示不存在

已知next [0, ..., j],如何求出next [j + 1]呢?
对于P的前j+1个序列字符:
- 若p[k] == p[j],则next[j + 1 ] = next [j] + 1 = k + 1;
- 若p[k ] ≠ p[j],如果此时p[ next[k] ] == p[j ],则next[ j + 1 ] = next[k] + 1,否则继续递归前缀索引k = next[k],而后重复此过程。 相当于在字符p[j+1]之前不存在长度为k+1的前缀"p0 p1, …, pk-1 pk"跟后缀“pj-k pj-k+1, …, pj-1 pj"相等,那么是否可能存在另一个值t+1 < k+1,使得长度更小的前缀 “p0 p1, …, pt-1 pt” 等于长度更小的后缀 “pj-t pj-t+1, …, pj-1 pj” 呢?如果存在,那么这个t+1 便是next[ j+1]的值,此相当于利用已经求得的next 数组(next [0, ..., k, ..., j])进行P串前缀跟P串后缀的匹配。
优化:
将
nextTable[j]=k;变为
if(p[j]!=p[k]) {
nextTable[j]=k; //next[j + 1 ] = next [j] + 1 = k + 1
} else {
//p[j+1]=p[k+1]
//如果p[j]=p[next[j]], 应该继续递归, k=next[k]=next[next[k]]
nextTable[j]=next[k];
}如果 p[j]==p[k]时,还要进行 nextTable[j]=k;,最后就会导致p[j]=p[nextTable[j]]。p[j]匹配失败时,与他相同的p[nextTable[j]]必然匹配失败,这一步是非常多余的,所以 当p[j]==p[k]时,不进行 nextTable[j]=k;而是继续递归,直到找到和 p[j]不同的p[nextTable[j]]才停止。
//char p[100]; 模式串
//m为p的长度
void GetNextTable(int m){ //m是模式串的长度
int j=0;
nextTable[0]=-1; //初始值赋值-1
int k=-1;
while(j<m){
if(k==-1 || p[j]==p[k]){
k++;
j++;
if(p[j]!=p[k]){
nextTable[j]=k; //next[j + 1 ] = next [j] + 1 = k + 1
}
else{
//p[j+1]=p[k+1]
//如果p[j]=p[next[j]], 应该继续递归, k=next[k]=next[next[k]]
nextTable[j]=next[k];
}
}
else{
//k回溯,直到找到长度为t的前缀“p0 p1, …, pt-1 pt” 等于 长度为t的后缀“pj-t pj-t+1, …, pj-1 pj”
//t<=k
k=nextTable[k];
}
}
}
3、完善KMP算法
//char s[100] 文本串 长为n
//char p[100] 模式串 长为m
int KMP(int n,int m){
GetNextTable(m);
int i=0;
int j=0;
while(i<n && j<m){
//如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
if(j==-1 || s[i] == p[j]) {
i++;
j++;
}
else{
//如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]
//next[j]即为j所对应的next值,根据上边的分析,即为p[j]不能匹配时,j应该移动到的位置
j=next[j];
}
}
if(j==m){
return i-j;
}
else{
return -1;
}
}最后是一个KMP模板题,趁热打铁,练一练
Number Sequence
#include<iostream>
using namespace std;
int s[1000005];
int p[10005];
int nextTable[10005];
void GetNextTable(int m){ //m是模式串的长度
int j=0;
nextTable[0]=-1; //初始值赋值-1
int k=-1;
while(j<m){
if(k==-1 || p[j]==p[k]){
k++;
j++;
if(p[j]!=p[k]){
nextTable[j]=k; //next[j + 1 ] = next [j] + 1 = k + 1
}
else{
//p[j+1]=p[k+1]
//如果p[j]=p[next[j]], 应该继续递归, k=next[k]=next[next[k]]
nextTable[j]=nextTable[k];
}
}
else{
//k回溯,直到找到长度为t的前缀“p0 p1, …, pt-1 pt” 等于 长度为t的后缀“pj-t pj-t+1, …, pj-1 pj”
//t<=k
k=nextTable[k];
}
}
}
int KMP(int n,int m){
GetNextTable(m);
int i=0;
int j=0;
while(i<n && j<m){
//如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
if(j==-1 || s[i] == p[j]) {
i++;
j++;
}
else{
//如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]
//next[j]即为j所对应的next值
j=nextTable[j];
}
}
if(j==m){
return i-j+1; //注意这块有个+1,看题目的例子就相当于下标从1开始,而我们一直都是从0
}
else{
return -1;
}
}
int main(){
int number;
int n,m;
scanf("%d",&number);
while(number--){
scanf("%d%d",&n,&m);
for(int i=0;i<n;i++){
scanf("%d",&s[i]);
}
for(int j=0;j<m;j++){
scanf("%d",&p[j]);
}
printf("%d\n",KMP(n,m));
}
return 0;
}















 2390
2390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









