







一、问题
OHMER旨在将人类手写轨迹点的坐标转换为计算机可以处理的格式化文件,如LaTeX字符串和inkml。与在线手写文本识别问题相比,OHMER面临着两个独特的挑战:复杂的二维空间结构和较小的开放数据集。
通常可以根据管道的数量将识别方法分为两种类型:两步方法[6]、[7]和端到端方法[2]、[8]、[9]。
在两步方法中,第一条管道是识别轨迹点为数学符号的符号识别,第二条管道是从给定的数学符号解析公式结构的结构识别。符号识别可以通过神经网络或传统的方法[10]来实现。结构识别可以通过二维上下文自由语法[11],[12]进行分析。
逐步识别方法的缺点如下:首先,编写复杂数学规则来解析复杂数学表达式需要数学先验知识。其次,结构识别取决于符号识别的结果,从而导致误差的积累。
端到端系统在一个单一的管道[13]-[16]中执行符号识别和结构识别。这些系统通常基于编码器解码器框架[17],[18],它可以将一系列轨迹点序列转换为LaTeX字符串,用于数学表达式识别。端到端方法的特征之一是其性能很大程度上依赖于注意机制获得的对齐信息。本文研究了一种端到端的基于笔画的后验注意网络,是对TAP的改进。
首先,用后验注意机制来代替软注意机制。在后验注意机制中,每次解码,首先计算每个轨迹点的软注意概率。然后,将每个点作为符号分类的输入,从而得到点的输出概率。通过将所有点的软注意力概率归一化,并以输出概率作为每个点的置信度来计算后验注意力。因此,通过考虑每个点的后验信息,后验注意可以得到比软注意得到更好的对齐信息。虽然TAP提出了一种注意引导器来增强软注意机制,但它需要额外的标记对齐数据来构建引导器,而且这样的对齐数据很难标记。
其次,我们认为后验注意机制的条件是,每个点产生的输出后验概率是可靠的。然而,对OHMER,一个数学符号通常由几十或数百个点组成,一个点不足以描述一个数学符号。故提出了计算除点以外的笔画的后验注意,因为笔画级特征比点级特征更集中、更丰富,更适合后验注意机制。通过使用笔画平均池化层,能够将同一笔画中所有点的相应局部特征聚合到笔画级特征中。
二、主要方法
首先介绍了模型的整体框架:编码器-解码器框架,它以轨迹点作为输入和输出一个乳胶字符串。然后,介绍了编码器的改进:笔画平均池化层,它将编码器模块获得的特征从点级聚合到笔画级。最后,介绍了解码器的改进:后验注意机制,这是一种统计上更合理和准确的注意机制。
1、编解码器框架

基于笔画的后注意机制的编解码器模型,其结构包括两部分:带有笔画平均池化层的GRU编码器和带有后注意的GRU解码器。
首先,将原始输入表示为N_p的序列点。每个点都由空间坐标(x_i、y_i)和一个笔画索引s_i组成。笔划索引s_i表示该点属于哪个笔画。预处理过程实现于从每个点提取一个8维特征向量x_i。使用序列X作为编码器的输入。编码器由四个Bi-GRU层、两个最大池化层和一个笔画平均池化层组成。编码器将从输入X中提取符号特征,表示为S的序列。
解码器由两个GRU层和一个后验注意机制组成。以S作为输入,解码器在每个步骤t输出每个类别P(y_t|y_(t-1),S)的概率。输出标记由序列Y表示。
2、Encoder with Stroke Average Pooling Layer
在TAP中,由编码器获得的特征可以表示为P:![]() P为点级特征,因为特征的数量和轨迹点的数量是相同的。
P为点级特征,因为特征的数量和轨迹点的数量是相同的。
点级特征有两个缺点:首先,每个点级特征没有包含足够的上下文信息。此外,相邻的点有很多冗余信息。虽然通过GRU获得的特征具有上下文信息,但当序列太长时,上下文信息不足。其次,输出序列的长度远小于点级特征的长度。
因此,用笔画平均池化层来将点级特征聚合为笔画级特征。由于笔画信息可以直接从输入设备获得,因此该操作不会导致数据标记过程的任何额外成本。根据笔画信息Xmask,通过行程平均池层聚合到点级特征S中。
3、Decoder With Posterior Attention Machanism
软注意为A_t,后注意为ˆA_t。后注意是在相应时间步观察输出标签后的 注意分布。因为注意力反映了输入和输出的对齐,所以当输出已知,注意力分布就会得到改善。
![]()
与软注意机制相比,主要的不同有三点:
1、在计算上,A_t的计算基于^A_(t-1)![]() ,F_att是计算软注意分布的函数,h_(t-1)表示解码器以前的隐藏状态。
,F_att是计算软注意分布的函数,h_(t-1)表示解码器以前的隐藏状态。
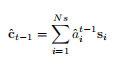 ,^c_(t-1)是基于后验注意ˆA_(t-1)计算的时间步t-1时的上下文向量,并与之前的目标标记y_(t-1)相连接以获得一个新的向量。
,^c_(t-1)是基于后验注意ˆA_(t-1)计算的时间步t-1时的上下文向量,并与之前的目标标记y_(t-1)相连接以获得一个新的向量。
ˆA_0的所有元素都被初始化为0。然后使用先前的隐藏状态h_(t-1)和连接向量[y_(t-1),ˆc_(t-1)]来计算注意的query,符号特征S表示注意的key。
此外,为注意机制附加了一个覆盖向量,用过去所有后验注意概率的总和进行和计算,以解决过度解析或解析不足的问题。
2、其次,注意力执行的位置从输入更改为输出。输出概率分布的公式为:![]()
3、传播到下一个解码步骤的后验注意分布ˆA_t以输出为条件。![]()

三、实验
数据集是CROHME2014+CROHME2016
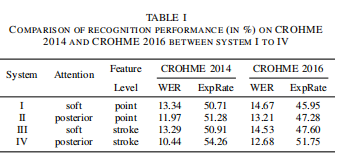
系统I——TAP
系统II使用后验注意机制,证明仅仅增加后验注意机制并不会带来显著的改善。原因是点级特征不足以描述数学符号。
系统III——在系统I的编码器中加入笔画平均池化层
系统IV——基于笔画的后注意机制

软注意和后验注意的注意可视化。使用红色来表示注意概率,深色表示更高的注意概率。为了更直观地显示注意力权值在两个分布之间的差异,绘制了直方图。直方图的水平轴表示笔画的序列号,而垂直轴表示注意权值。
















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









