






Pyttsx3库介绍
pyttsx3 库是一个功能强大且使用方便的 Python 本地文本转语音库。它不仅能在离线下将文本转换为语音MP3格式文件,也能在 Windows、MacOS 和 Linux 等多个操作系统上实现语音播报。同时,还可以调整语音播报的语速、音量和音色。
安装与基本使用
安装:cmd命令行中执行 pip install pyttsx3。
基本使用示例:
import pyttsx3
# 初始化语音引擎
engine = pyttsx3.init()
# 可以通过 engine.setProperty('rate', new_rate) 方法来调整语音的语速。
# new_rate 是一个整数,表示每分钟的单词数。
# 例如,默认语速可能是 150,若想加快语速,可以将其设置为 200。
engine.setProperty('rate', 150)
# engine.setProperty('volume', new_volume) 来设置音量。
# new_volume 是一个介于 0.0(静音)和 1.0(最大音量)之间的浮点数。
# 比如,engine.setProperty('volume', 0.8) 会将音量设置为最大音量的 80%。
engine.setProperty('volume', 0.8)
# 在 Windows 系统中,可以通过语音 ID 来选择不同的语音音色,只有两种音色。
# voices[0].name为Microsoft Huihui Desktop - Chinese (Simplified)
# voices[1].name为Microsoft Zira Desktop - English (United States)
voices = engine.getProperty('voices')
for voice in voices:
print(voice.id)
print(voice.name)
# 选择第二个语音,适用于英语朗读。
engine.setProperty('voice', voices[1].id)
# 设置需要朗读的文本。
text = "Hello, this is a simple text-to-speech example."
# 指定要转换为语音的文本内容。
engine.say(text)
# 执行语音播放任务。
engine.runAndWait()
# 定义MP3文件名称。
filename = "output.mp3"
# 保存MP3音频文件。
engine.save_to_file(text, filename)
engine.runAndWait() # 需要这行才能保存MP3音频文件。
构建Pyttsx3库的GUI使用界面
为方便大家理解使用,作者已构建Pyttsx3库的GUI界面,美化了界面,为每行代码添加注释,免去编程的烦恼,直接复制即可用,代码如下:
import tkinter as tk # 导入tkinter库,用于创建GUI应用程序,并将其简称为tk
from tkinter import ttk # 从tkinter库中导入ttk模块,用于创建更美观的GUI组件
import pyttsx3 # 导入pyttsx3库,用于实现文本到语音的转换
import datetime # 导入datetime库,用于处理日期和时间相关的操作
import threading # 导入threading库,用于在后台线程中执行任务,避免阻塞主线程
engine = pyttsx3.init() # 初始化pyttsx3语音引擎,创建一个用于语音操作的对象
is_playing = False # 定义一个布尔变量,用于标记语音是否正在播放,初始值为False
def save_speech():
global is_playing # 声明要使用全局变量is_playing
if is_playing:
status_label.config(text="正在试听中,请等待停止后再保存!") # 如果正在播放语音,更新状态标签提示用户
return # 直接返回,不执行后续保存操作
text = text_entry.get("1.0", "end-1c") # 获取文本输入框中的文本内容
filename = filename_entry.get() # 获取用户输入的文件名
if not filename:
filename = datetime.datetime.now().strftime("%Y%m%d%H%M%S") # 如果用户没有输入文件名,使用当前时间生成一个文件名
filename += ".mp3" # 给文件名添加.mp3后缀
engine.setProperty('rate', int(rate_entry.get())) # 设置语音播放的语速,从语速输入框中获取值并转换为整数
engine.setProperty('volume', float(volume_entry.get()) / 100) # 设置语音播放的音量,从音量输入框中获取值并转换为浮点数,再除以100得到0到1之间的音量值
engine.setProperty('voice', voice_var.get()) # 设置要使用的语音音色,从语音选择框中获取选择的语音ID
def save_file():
engine.save_to_file(text, filename) # 将文本内容保存为音频文件
engine.runAndWait() # 运行语音引擎,等待音频文件保存完成
status_label.config(text=f"文件已保存为:{filename}") # 更新状态标签,显示文件已保存的信息
threading.Thread(target=save_file, daemon=True).start() # 在后台线程中启动保存文件的任务,daemon=True表示该线程会在主线程结束时自动结束
def preview_speech():
status_label.config(text="正在试听中...") # 更新状态标签,提示用户正在试听
global is_playing # 声明要使用全局变量is_playing
if is_playing:
status_label.config(text="正在试听中,请等待停止后再点击!") # 如果正在播放语音,更新状态标签提示用户
return # 直接返回,不执行后续试听操作
is_playing = True # 将is_playing设置为True,表示开始试听
text = text_entry.get("1.0", "end-1c") # 获取文本输入框中的文本内容
engine.setProperty('rate', int(rate_entry.get())) # 设置语音播放的语速,从语速输入框中获取值并转换为整数
engine.setProperty('volume', float(volume_entry.get()) / 100) # 设置语音播放的音量,从音量输入框中获取值并转换为浮点数,再除以100得到0到1之间的音量值
engine.setProperty('voice', voice_var.get()) # 设置要使用的语音音色,从语音选择框中获取选择的语音ID
def play():
try:
engine.say(text) # 让语音引擎开始播放文本内容
engine.runAndWait() # 运行语音引擎,等待语音播放完成
finally:
global is_playing
is_playing = False # 无论语音播放是否正常完成,都将is_playing设置为False,表示试听结束
status_label.config(text="试听已结束!") # 更新状态标签,提示用户试听已结束
threading.Thread(target=play, daemon=True).start() # 在后台线程中启动播放语音的任务,daemon=True表示该线程会在主线程结束时自动结束
root = tk.Tk() # 创建一个Tkinter窗口对象,这是GUI应用程序的主窗口
root.title("文字转语音转换器") # 设置主窗口的标题为“文字转语音转换器”
# 输入文本
input_frame = tk.Frame(root) # 创建一个框架(Frame)用于组织输入文本相关的组件
input_frame.grid(row=0, column=0, padx=10, pady=10, sticky="nsew") # 使用grid布局管理器将框架放置在主窗口的第0行第0列,设置水平和垂直方向的间距为10,并且使框架在四个方向上都能拉伸
tk.Label(input_frame, text="输入文本:").grid(row=0, column=0, sticky=tk.W, padx=5, pady=5) # 在框架内创建一个标签,显示“输入文本:”,并使用grid布局将其放置在第0行第0列,左对齐,设置水平和垂直方向的间距为5
text_entry = tk.Text(input_frame, height=10, width=50) # 在框架内创建一个文本输入框,高度为10,宽度为50
text_entry.grid(row=1, column=0, sticky="nsew", padx=5, pady=5) # 使用grid布局将文本输入框放置在第1行第0列,使其在四个方向上都能拉伸,设置水平和垂直方向的间距为5
# 语速
settings_frame = tk.Frame(root) # 创建一个框架用于组织语速、音量、选择语音和文件名相关的设置组件
settings_frame.grid(row=1, column=0, padx=10, pady=10, sticky="nsew") # 使用grid布局将框架放置在主窗口的第1行第0列,设置水平和垂直方向的间距为10,并且使框架在四个方向上都能拉伸
tk.Label(settings_frame, text="语速(0-200):").grid(row=0, column=0, sticky=tk.W, padx=5, pady=5) # 在框架内创建一个标签,显示“语速(0-200):”,并使用grid布局将其放置在第0行第0列,左对齐,设置水平和垂直方向的间距为5
rate_entry = tk.Entry(settings_frame, width=34) # 在框架内创建一个输入框用于输入语速,宽度为34
rate_entry.insert(0, '150') # 在语速输入框中插入默认值150
rate_entry.grid(row=0, column=1, padx=5, pady=5) # 使用grid布局将语速输入框放置在第0行第1列,设置水平和垂直方向的间距为5
# 音量
tk.Label(settings_frame, text="音量(0-100):").grid(row=1, column=0, sticky=tk.W, padx=5, pady=5) # 在框架内创建一个标签,显示“音量(0-100):”,并使用grid布局将其放置在第1行第0列,左对齐,设置水平和垂直方向的间距为5
volume_entry = tk.Entry(settings_frame, width=34) # 在框架内创建一个输入框用于输入音量,宽度为34
volume_entry.insert(0, '100') # 在音量输入框中插入默认值100
volume_entry.grid(row=1, column=1, padx=5, pady=5) # 使用grid布局将音量输入框放置在第1行第1列,设置水平和垂直方向的间距为5
# 选择语音
tk.Label(settings_frame, text="选择语音:").grid(row=2, column=0, sticky=tk.W, padx=5, pady=5) # 在框架内创建一个标签,显示“选择语音:”,并使用grid布局将其放置在第2行第0列,左对齐,设置水平和垂直方向的间距为5
voice_var = tk.StringVar(root) # 创建一个字符串变量,用于存储选择的语音ID
voices_combo = ttk.Combobox(settings_frame, textvariable=voice_var, state="readonly", width=32) # 在框架内创建一个只读的下拉组合框,用于选择语音,宽度为32,关联到voice_var变量
voices = engine.getProperty('voices') # 获取语音引擎支持的所有语音
voices_combo['values'] = [voice.name for voice in voices] # 将所有语音的名称设置为下拉组合框的可选值
voices_combo.current(0) # 设置下拉组合框的默认选择为第一个语音
voices_combo.grid(row=2, column=1, padx=5, pady=5) # 使用grid布局将下拉组合框放置在第2行第1列,设置水平和垂直方向的间距为5
# 文件名
tk.Label(settings_frame, text="文件名(可选):").grid(row=3, column=0, sticky=tk.W, padx=5, pady=5) # 在框架内创建一个标签,显示“文件名(可选):”,并使用grid布局将其放置在第3行第0列,左对齐,设置水平和垂直方向的间距为5
filename_entry = tk.Entry(settings_frame, width=34) # 在框架内创建一个输入框用于输入文件名,宽度为34
filename_entry.grid(row=3, column=1, padx=5, pady=5) # 使用grid布局将文件名输入框放置在第3行第1列,设置水平和垂直方向的间距为5
# 控制按钮
control_frame = tk.Frame(root) # 创建一个框架用于组织控制按钮
control_frame.grid(row=2, column=0, padx=10, pady=10, sticky="nsew") # 使用grid布局将框架放置在主窗口的第2行第0列,设置水平和垂直方向的间距为10,并且使框架在四个方向上都能拉伸
# 配置列权重,使按钮均匀分布
control_frame.columnconfigure(0, weight=1) # 配置框架的第0列权重为1,使该列在水平方向上均匀分配空间
control_frame.columnconfigure(1, weight=1) # 配置框架的第1列权重为1,使该列在水平方向上均匀分配空间
control_frame.columnconfigure(2, weight=1) # 配置框架的第2列权重为1,使该列在水平方向上均匀分配空间
preview_button = tk.Button(control_frame, text="试听", command=preview_speech) # 在框架内创建一个按钮,显示“试听”,点击时调用preview_speech函数
preview_button.grid(row=0, column=0, sticky="ew", padx=5, pady=5) # 使用grid布局将试听按钮放置在第0行第0列,使其在水平方向上拉伸,设置水平和垂直方向的间距为5
save_button = tk.Button(control_frame, text="保存为MP3", command=save_speech) # 在框架内创建一个按钮,显示“保存为MP3”,点击时调用save_speech函数
save_button.grid(row=0, column=2, sticky="ew", padx=5, pady=5) # 使用grid布局将保存按钮放置在第0行第2列,使其在水平方向上拉伸,设置水平和垂直方向的间距为5
# 状态标签
status_label = tk.Label(root, text="", relief=tk.SUNKEN, bd=1, padx=5, pady=5) # 创建一个标签用于显示状态信息,设置凹陷的边框样式,边框宽度为1,水平和垂直方向的间距为5
status_label.grid(row=3, column=0, sticky="nsew", padx=5, pady=10) # 使用grid布局将状态标签放置在第3行第0列,使其在四个方向上都能拉伸,设置水平和垂直方向的间距为5和10
root.mainloop() # 启动Tkinter主事件循环,使窗口保持显示并响应用户操作
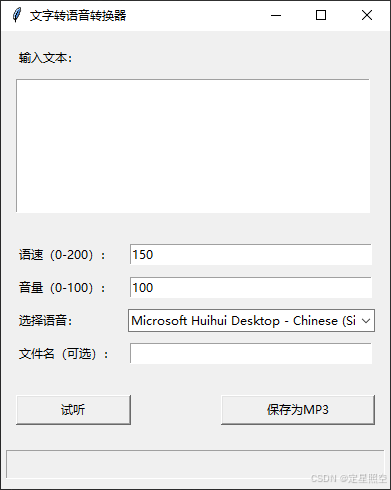
该代码在输入文本后,可实现语速和音量的调节,音色的选择,文本的试听,重命名MP3格式文件名和保存MP3格式文件,如下图所示:
参考资料
利用Python的Pyttsx3库实现离线文字转语音(TTS)功能:
https://blog.csdn.net/weixin_45498383/article/details/137688557
python如何将word文档内容转换成语音:
https://blog.csdn.net/weixin_57635535/article/details/141922644
作者创作不易,如果对你有帮助,可以点赞或者关注作者,支持一下呗!


















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









