






主成分分析法(Principal Component Analysis)大多在数据维度比较高的时候,用来减少数据维度,因而加快模型训练速度。另外也有些用途,比如图片压缩(主要是用SVD,也可以用PCA来做)、因子分析等。具体怎么用,看个人需求如何,这篇文章主要解释一下PCA的原理。当然应用起来也非常简单,现在常用的语言,Python、R、matlab都有直接求解PCA或者SVD的包了。
这篇文章主要想讲讲PCA的思想,当然有很多看官并不在乎这个算法的思想是什么,而仅仅急切地想要实现它,在文章最后,我们给出了R语言的实现方法,想看实现方法的可以直接跳到文章最后。
下面我们看看PCA具体做了些什么。
我们有一组数据
X
,维度是m x n,表示有 n个样本,每个样本有m个特征,即:
现在我们想知道这个数据具体包含了哪些信息,这里可能需要引入一个大家都很熟悉的概念,方差。让我们先看其中某一维的数据,例如: x1=[x1,1,x1,2,⋯,x1,n] 。如果说 x1 其中每一项都相等,也就是每一项都等于一个常数,那么我们认为 x1 并没有包含什么信息,因为它 就是一个已知的常数。所以,我们想要某一维的数据越多样性越好,这样它可以包含更多的信息,我们可以据此做出更多的推断。笼统来说,我们可以用方差来表示数据的多样性。
PCA对数据的分布其实是有一个假设的,即每一个维度上的数据都服从Gaussian分布。假设 x1 平均值是 x1¯¯¯¯ 、方差是 σ21 ,令 x1=[x1,1−x1¯¯¯σ1,⋯,x1,n−x1¯¯¯σ1] ,这样 x1 就服从均值为0,方差为1的高斯分布。后面我们默认X的每一个维度都服从均值为0,方差为1 的高斯分布,即每一个维度上的数据方差都为1。这样处理过后,似乎每一个维度上的数据都包含等量的信息。
然而真实情况好像并不是这样,我们会发现有些特征能给我们带来更大的帮助,往往某一个或者两个特征能对模型产生重要的影响,而继续增加更多特征,也只会使模型在小幅度内提升。这说明有些特征能够给我们带来更多的信息,这是怎么回事呢?下面,我们来看另一个定义,协方差。
协方差是来反映数据间的相关性。有两组数据,他们的关系如下图:
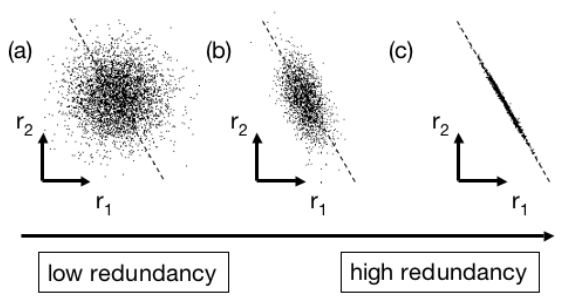
如果如图(a),则说明两组数据相关性低(或者说low redundancy);如果如图(c),则说明两组数据的相关性高,也就是high redundancy,因为我们基本上可以认为
r2=k∗r1
,也就是
r2
其实是多余的。
x1=[x1,1,x1,2,⋯,x1,n] , x2=[x2,1,x2,2,⋯,x2,n] 是服从均值为0,方差为1 的高斯分布的两组数据。我们知道方差的定义:
我们现在定义数据 x1 和 x2 的协方差:
协方差有两个性质: 1)当且仅当 x1 和 x2 完全不相关时, σ21,2=0 ;2)如果 x1=x2 ,那么 σ21,2=σ21 。
现在,让我们看一个矩阵 XXT ,实际上它是一个表示各维度之间方差的对称方阵, σ21,2=σ22,1 ,也可以叫做协方差矩阵。 X 的维度是 m×n , XT 的维度是 n×m ,那么 XXT 的维度则是 m×m ,即:
假设我们有一个矩阵 3×4 的矩阵 A :
我们可以得到矩阵 AAT :
可以看到 AAT 是一个对称的矩阵,且每一个维度与自己的方差为1,而与其它维度的协方差则各不相同。也就是说每一个维度不仅表达了自身,这个维度所带有的信息,还表达了与其它维度的部分信息。这也就能解释,虽然每个维度的方差都为1,但是它们所包含的真实信息量是不同的。
然而,假如我们得到一个 AAT 的矩阵:
也就是说,各个维度是完全独立的,维度与维度之间的相关性为0。这样每个维度就只包含了自己的信息,我们现在就可以说第一个维度包含了矩阵 A 59%(0.59/(0.59 + 0.29 + 0.12))的信息,第二个维度包含了29%的信息,第三个维度包含了12%的信息。
这是不是给了你一个启发,要是我能有一个数据(矩阵),它的每一个维度都是完全独立的,那么我计算出每个维度的方差,取方差最大的几个,这样我就可以用很少的几个维度,包含整个数据大部分的信息。比如上面那个例子,我用前面两个维度,就可以包含所有数据88%的信息。
这就是PCA的基本思想。然而现实中,并不是遇到的每个数据集合,它各个维度之间的方差均为0。实际上,基本上不可能存在这样的数据集合。我们收集到的数据之间或多或少都会存在关联。例如我们要预测一个人是否会发生购买行为,我们会看他浏览了了多少商品,收藏了多少商品,然而浏览与收藏之间肯定是有联系的。那么如何实现PCA呢。
矩阵当中有一个非常著名的理论,一个 n×n 的对称矩阵 A 可以表示为: A=VDVT 。其中, V 是一个正交矩阵, D 是一个对角矩阵,除了对角线上的值可能不为0以外,其它的值均为0。
根据上面理论,对于任意一个
m×n
的矩阵
A
,
AAT
是一个
m×m
的对称矩阵,因而
AAT
可以表示为:
AAT=VDVT
,即
VTA(VTA)T=D
。也就是对于任意一个
m×n
的矩阵
A
,我们可以找到一个
m×m
的矩阵
V
,使得矩阵
VTA
的方差矩阵
VTA(VTA)T
,只有对角线上的值不为0,即矩阵各个维度之间相互独立。
以上,PCA的思想就介绍完了。但是 VTA 具体是做了什么事情呢?它对矩阵 A 又有什么影响?让我们来看一下 V 是一个什么样子的矩阵。
根据这个定理 AAT=VDVT ,实际上 V 是矩阵 A 中所有的特征向量构成的一个矩阵,不过这里我们并不考虑V是如何求来的,如何求得,不过是线性代数里面的一些知识。这里我们关心的是, V 是一个 m×m 的矩阵,所以 VTA 是一个 m×n 的矩阵。如果我们在的 VTA 左边乘上 (VT)−1 ,矩阵又会变回 A ,也就是 (VT)−1VTA=A 。所以,实际上用 V 的转置乘上 A ,只是对 A 做了一些行列上的变换,并没有减少任何信息,如果我们想要,我们还可以把 A 变回来。这样,我们完全可以由变换后的矩阵 VTA ,来表示原来的数据 A ,且不会有任何信息损失。而且,转换后的矩阵有一个非常好的性质,就是各个维度之间相互独立,所以我们可以得到它的方差矩阵 VTA(VTA)T=D ,是一个只有对角线上元素不为0的对角矩阵。
这样,我们就可以知道每一个维度分别包含了多少信息。假如数据的维度m,是一个非常大的值,例如10,0000,如果我们发现仅仅使用前10个维度,就能包含95%以上的信息,那么我们将很高兴用这10个维度,而舍弃掉剩下的其它维度,这相当于将数据压缩了10000倍,而并没有损失多少信息。当然这只是我们的臆想,实际情况不一定有这么好。
R实现:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
这里我们使用R中内置的函数SVD,来实现PCA的算法。实际情况中,我们常常可以看到SVD和批PCA在一起被提到,它们之间又有什么关系。感兴趣的话,可以看看我的下一篇blog:SVD与PCA详解。















 1520
1520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









