







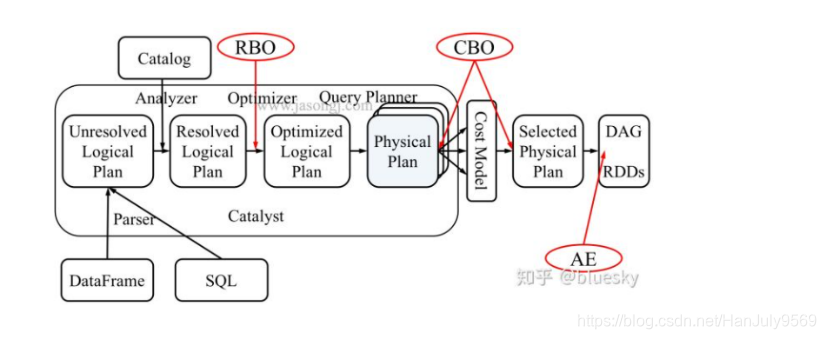
引用:
总结
-
首先用户使用spark.sql 或者 select等api提交sql
-
转化为未解析的逻辑计划
为什么叫为解析的逻辑计划:因为没有考虑数据的
-
转化为已解析的逻辑计划
-
转化为优化后的逻辑计划
-
转化为物理执行计划
-
计算物理执行计划的开销模型,选择一个解析为RDD去执行
例子
以下以这个sql的解析为例:
SELECT sum(v)
FROM (
SELECT score.id,
100+80+ score.math_score + score.english_score AS v
FROM people
JOIN score
ON people.id = score.id AND people.age >10
) tmp
未解析逻辑计划
为什么叫未解析?
因为它完全没考虑sql的数据大小,表结构的元数据。它完全不知道表的大小,表的schema,选取的字段类型也不知道
上面sql解析的图为
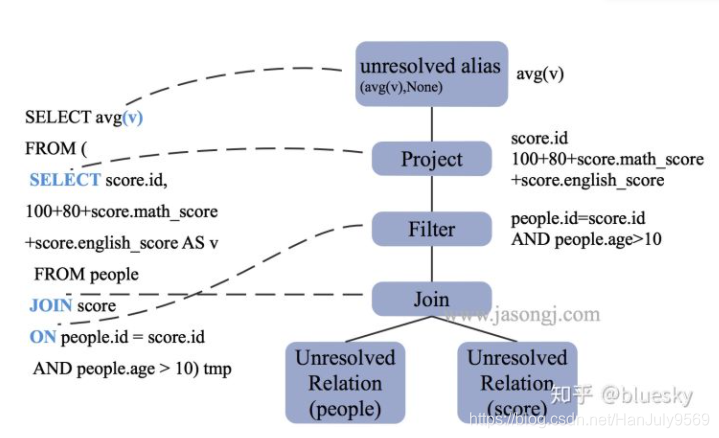
从上图来看,它甚至连别名都没有
==ParsedLogicalPlan==
'Project [unresolvedalias('sum('v), None)]
+- 'SubqueryAlias tmp
+-'Project ['score.id,(((100+80)+'score.math_score) + 'score.english_score) AS v#493]
+-'Filter (('people.id ='score.id) && ('people.age >10))
+-'Join Inner
:- 'UnresolvedRelation`people`
+-'UnresolvedRelation `score`
以上为控制台打出的执行计划
已解析执行计划
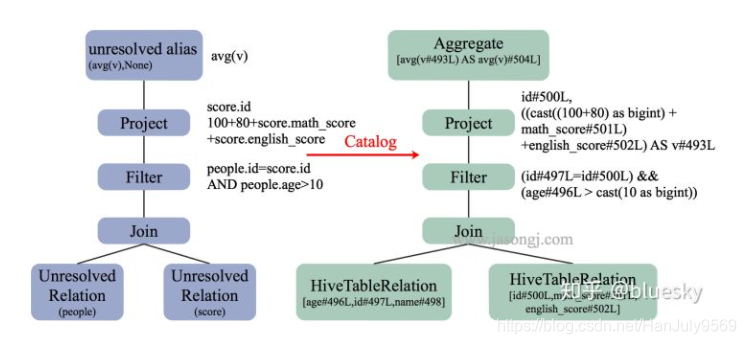
这一步将我们上一步提到的:数据类型,表的schema,表的来源地址,用户未加上的别名
==AnalyzedLogicalPlan==
sum(v): bigint
Aggregate[sum(cast(v#493 as bigint)) AS sum(v)#504L]
+-SubqueryAlias tmp
+-Project[id#500, (((100 + 80) + math_score#501) + english_score#502) AS v#493]
+-Filter((id#496 = id#500) && (age#497 > 10))
+-JoinInner
:-SubqueryAlias people
:+-HiveTableRelation`jason`.`people`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe,[id#496, age#497, name#498]
+-SubqueryAlias score
+-HiveTableRelation`jason`.`score`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe,[id#500, math_score#501, english_score#502]
虽然以上的执行计划已经可以解析为物理执行计划了,但是由于sql的水平不一样,并且也不希望程序员把精力放在这些基本的优化项上,,所以还有一步优化的过程。减少低效率sql带来的性能消耗。
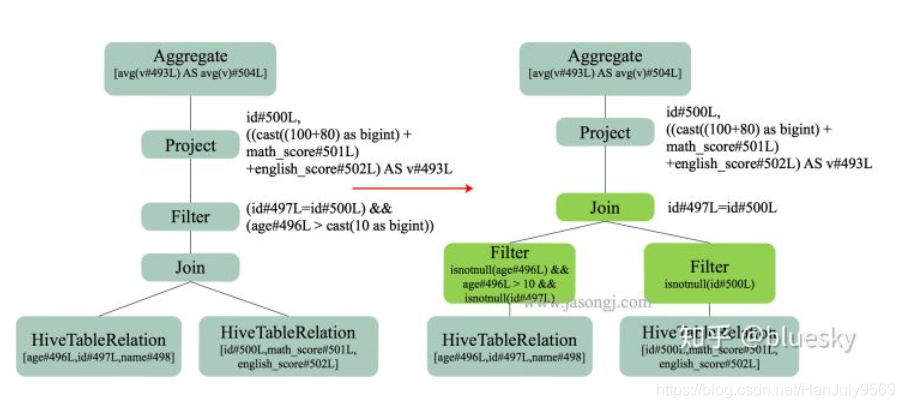
优化执行计划
常见的优化策略
-
谓词下推(图的解析是从下到上的,所以叫下推)
比如以上sql是先join再过滤,那么需要将过滤放到join前面。注意以上的图中过滤都在join的前面
如果另一张表没有过滤条件,默认过滤不为空的数据。
Tips:写sql的时候注意处理null值得关联,可以使用COALESCE给nul值改一个特殊得内容
-
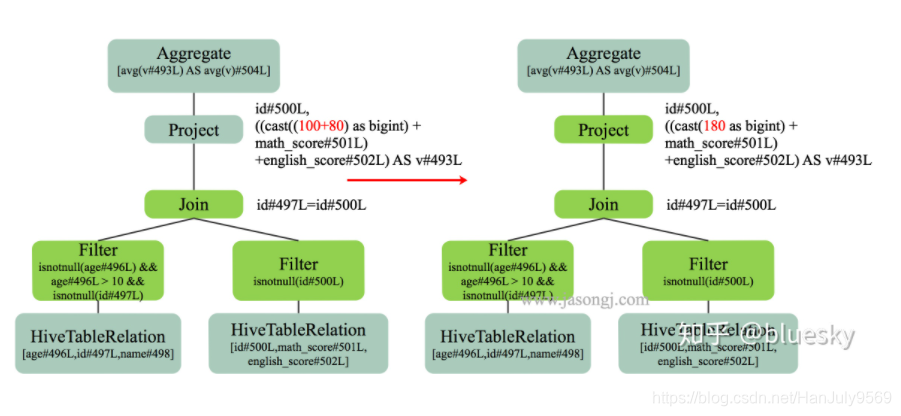
常量合并
比如上图中100+80这个运算,如果一直不合并得话,每次都要计算消耗cpu资源,所以提前计算为180
如果有一亿条记录,就会计算一亿次 100 + 80
-
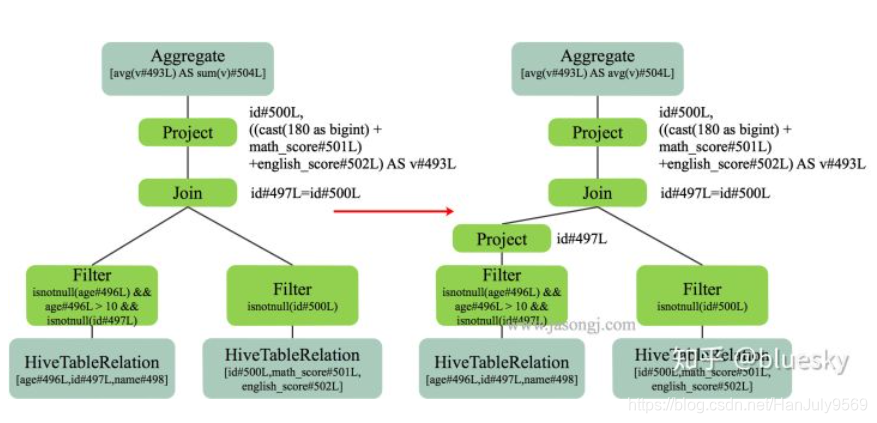
列裁剪
比如上图,连接条件只有people.id = score.id和pepolple.age > 10,如果不处理,就需要将所有的字段加载入内存,那就太浪费内存了。
甚至有些表是50到上百的字段,每个字段都特别大。
以上优化后的执行计划
==OptimizedLogicalPlan==
Aggregate[sum(cast(v#493 as bigint)) AS sum(v)#504L]
+-Project[((180+ math_score#501) + english_score#502) AS v#493]
+-JoinInner,(id#496 = id#500)
:-Project[id#496]
:+-Filter((isnotnull(age#497) && (age#497 > 10)) && isnotnull(id#496))
:+-HiveTableRelation`jason`.`people`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe,[id#496, age#497, name#498]
+-Filter isnotnull(id#500)
+-HiveTableRelation`jason`.`score`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe,[id#500, math_score#501, english_score#502]
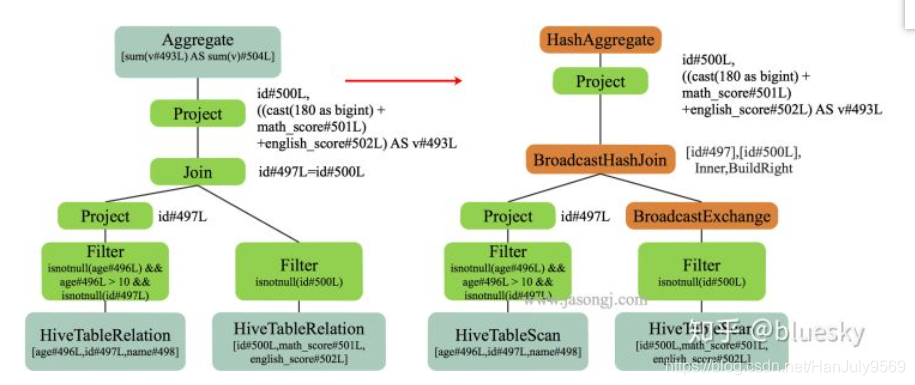
物理执行计划
逻辑执行计划是不能再机器上执行,比如程序员写的代码最终是要解释为0,1,机器才能执行的。
这一步主要告诉机器用什么方式执行逻辑图,比如:
JOIN: 广播join,hash join ,shuffle join
Aggreate: 基于排序的聚合,基于hash的聚合,预聚合
本文的优化是基于RBO的优化,即基于规则的优化。spark高版本中还有CBO优化,写到这里休息一会。由于上面提高物理执行计划join的分类,聚合的分类。
所以把它们一起总结了,方便查看。我只是伸手党,要理解还是要去看源码的。
物理执行计划基于CBO的优化
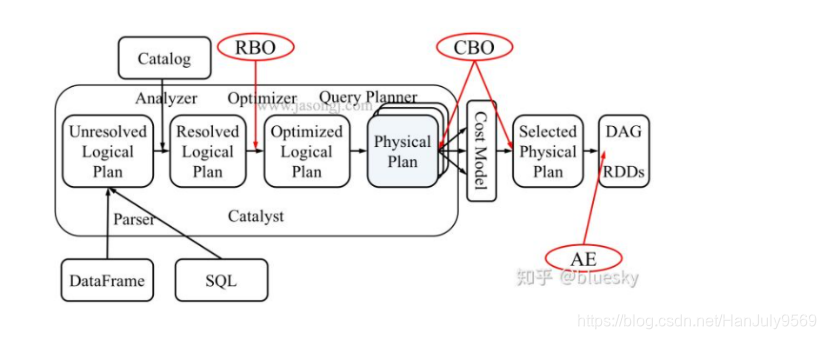
我重新把架构图放下来方便查看,接下来我们要阐述上图中CBO的部分
CBO会计算执行计划树,转化为代价树,汇总计算总代价。会产生多个模型,从中选取一个最好的
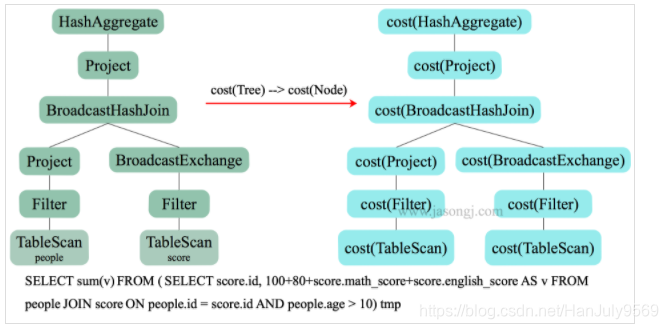
常见的代价计算
- 由于源头输入数据的分布情况与大小带来的处理代价
- 算子本身的执行代价
- 中间算子输出数据对下一步的影响
选择
- join方式的选择
- Build侧选择
- join顺序
所以总结以下,主要从数据分布和算子本身去考虑
- 怎么知道数据的分布呢?
在sparkshell控制台,当然我认为我们也是可以使用其他工具去处理
spark-sql> ANALYZE TABLE customer COMPUTE STATISTICS FOR COLUMNS c_customer_sk,c_customer_id,c_current_cdemo_sk,c_current_hdemo_sk,c_current_addr_sk,c_first_shipto_date_sk,c_first_sales_date_sk,c_salutation,c_first_name,c_last_name,c_preferred_cust_flag,c_birth_day,c_birth_month,c_birth_year,c_birth_country,c_login,c_email_address,c_last_review_date;
Time taken: 125.624 seconds
spark-sql> desc extended customer c_customer_sk;
col_name c_customer_sk
data_type bigint
comment NULL
min 1
max 280000
num_nulls 0
distinct_count 274368
avg_col_len 8
max_col_len 8
histogram height: 1102.3622047244094, num_of_bins: 254
bin_0 lower_bound: 1.0, upper_bound: 1090.0, distinct_count: 1089
bin_1 lower_bound: 1090.0, upper_bound: 2206.0, distinct_count: 1161
bin_2 lower_bound: 2206.0, upper_bound: 3286.0, distinct_count: 1124
...
bin_251 lower_bound: 276665.0, upper_bound: 277768.0, distinct_count: 1041
bin_252 lower_bound: 277768.0, upper_bound: 278870.0, distinct_count: 1098
bin_253 lower_bound: 278870.0, upper_bound: 280000.0, distinct_count: 1106
- 算子的代价估算
Cost = rows * weight + size * (1 - weight)
Cost = CostCPU * weight + CostIO * (1 - weight)
其中 rows 即记录行数代表了 CPU 代价,size 代表了 IO 代价。weight 由 spark.sql.cbo.joinReorder.card.weight 决定,其默认值为 0.7。
Build侧选择
join的实现方式大致分为两种:
-
使用hash去join,相同的字符串的hash值一定是相同的,所以就可以将一张表做hash表,另一张表去执行hash函数查找对应的行进行合并
-
使用排序去join,两张表排序,然后按顺序去扫描连接,左表使用过的就可以丢掉
从第一点提到hash表,那么从那一张表中去生成hash表呢?第一反应就是小表,但是大表也可能会经过一些操作后再连接。
在这种情况下,反而初始的大表变成了小表。这节的标题就是这个意思。
如图:

经过检测后处理为下面的情况
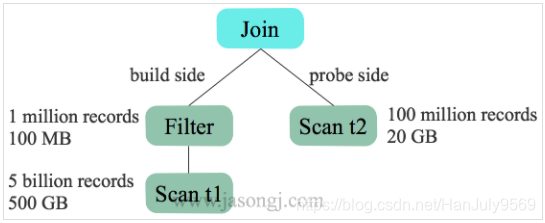
Join的顺序
一些sql由于业务逻辑和思维习惯的问题,会形成一个左深树,不能并行的sql.但是其实它是可以并行关联后再进行合并的如下图:

优化后
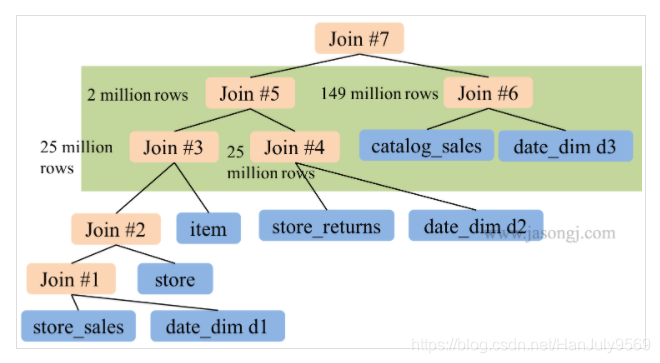
简单的举一个列子:
A 1000 W JOIN B 1000W JOIN C 100W
其实可以先连接A 和 C 减少数据
优化join类型
SparkSQL的执行流程从提交到计算代价模型就差不多阐述完了,其实还有几点没有说。
1.怎么从物理计划中选择
2.物理计划怎么转化为RDD的
以上我都没找到,希望大家在下面留言告诉我谢谢
最后补充下Join的类型与 聚合的类型,这个也是在优化中spark选择的。
JOIN类型
主要分为两大类,三小类。
Hash Join
将其中一张表构建为hash表,然后另一张表使用同样的hash函数去寻找相同的行合并
至于那一张去做hash表,参考上面。原则上是小表,但是也可能会出现大表在经历一系列的操作时反而变成了小表
-
Broadcast Hash join
顾名思义,即把小表构建成hash表广播出去
-
Shuffle Hash join
通过shuffle的方式重新分区数据,保证相同的key都在一个分区(这里的意思不是一个分区只有一个key,是多个key),然后在相同的分区上进行Hash join
以上两种方式,第一种适用于小表join大表,第二种适用于普通表join大表
Sort Join
基于排序join,首先shuffle将相同的key放到相同的分区下,然后排序。开始扫描,相同合并,不相同考虑保留那一边,即用即丢。
聚合类型
其实也是类似的
-
基于排序的
-
基于Hashmap的
注意这里Map是spark自己实现的,不是java的,它裁剪了一些没有用的功能
-
预聚合
在map端聚合,比如:reducebykey














 1792
1792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









