







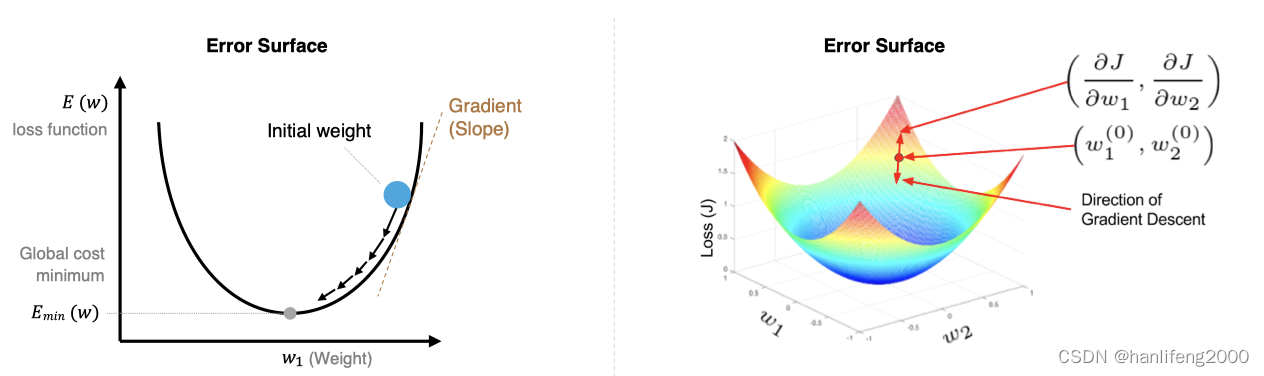
1、梯度下降算法
梯度下降法简单来说就是⼀种寻找使损失函数最⼩化的⽅法。⼤家在机器
学习阶段已经学过该算法,所以我们在这⾥就简单的回顾下,从数学上的
⻆度来看,梯度的⽅向是函数增⻓速度最快的⽅向,那么梯度的反⽅向就
是函数减少最快的⽅向,所以有:
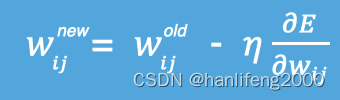
其中,
η
是学习率,如果学习率太⼩,那么每次训练之后得到的效果都太
⼩,增⼤训练的时间成本。如果,学习率太⼤,那就有可能直接跳过最优
解,进⼊⽆限的训练中。解决的⽅法就是,学习率也需要随着训练的进⾏
⽽变化。

#梯度下降算法
import tensorflow as tf
#实例化SGD
opt=tf.keras.optimizers.SGD(learning_rate=0.1)
#定义要更新的参数
var=tf.Variable(1.0)
#定义损失函数
loss=lambda:(var**2)/2.0
#计算梯度,并进行参数更新
opt.minimize(loss=loss,var_list=var).numpy()
#参数更新结果
print(var.numpy())
# loss的导数为var var(new)=var(old)-学习率*损失函数导数
#var(new)=var(old)-学习率*损失函数导数=1.0-0.1*1=0.9
在进⾏模型训练时,有三个基础的概念:

实际上,梯度下降的⼏种⽅式的根本区别就在于
Batch Size
不同
,
,如下
表所示:

假设数据集有
50000
个训练样本,现在选择
Batch Size = 256
对模型进
⾏训练。
每个
Epoch
要训练的图⽚数量:
50000
训练集具有的
Batch
个数:
50000/256+1=196
每个
Epoch
具有的
Iteration
个数:
196
10
个
Epoch
具有的
Iteration
个数:
1960
2.反向传播算法 (BP算法)
利⽤反向传播算法对神经⽹络进⾏训练。该⽅法与梯度下降算法相结合,
对⽹络中所有权重计算损失函数的梯度,并利⽤梯度值来更新权值以最⼩
化损失函数。在介绍
BP
算法前,我们先看下前向传播与链式法则的内
容。
2.1 前向传播与反向传播

在⽹络的训练过程中经过前向传播后得到的最终结果跟训练样本的真实值 总是存在⼀定误差,这个误差便是损失函数。想要减⼩这个误差,就⽤损 失函数ERROR,从后往前,依次求各个参数的偏导,这就是反向传播 (Back Propagation)。
2.2 链式法则
反向传播算法是利⽤链式法则进⾏梯度求解及权重更新的。对于复杂的复
合函数,我们将其拆分为⼀系列的加减乘除或指数,对数,三⻆函数等初
等函数,通过链式法则完成复合函数的求导。为简单起⻅,这⾥以⼀个神
经⽹络中常⻅的复合函数的例⼦来说明 这个过程
.
令复合函数 𝑓
(
𝑥
;
𝑤
,
𝑏
)
为
:
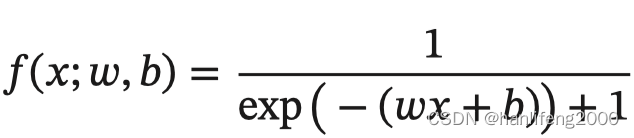

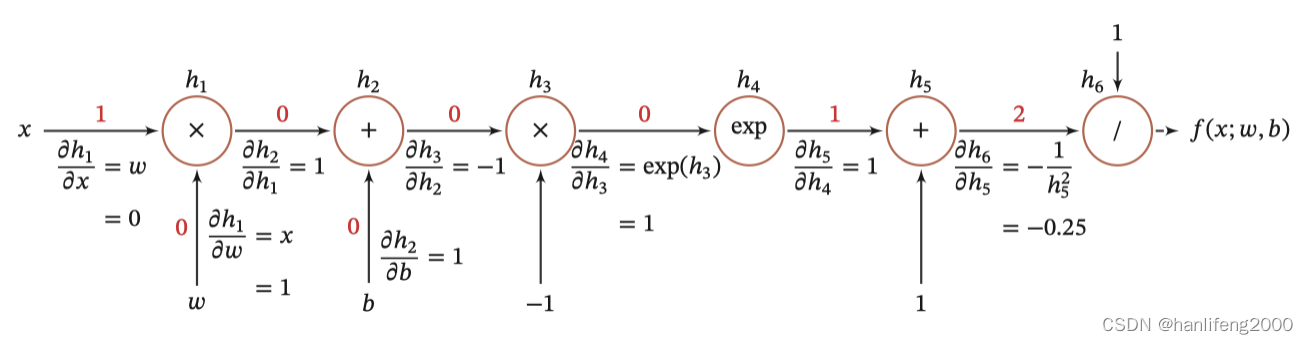
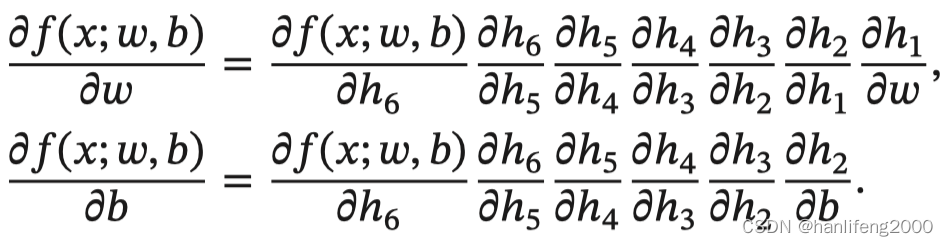


2.3 反向传播算法
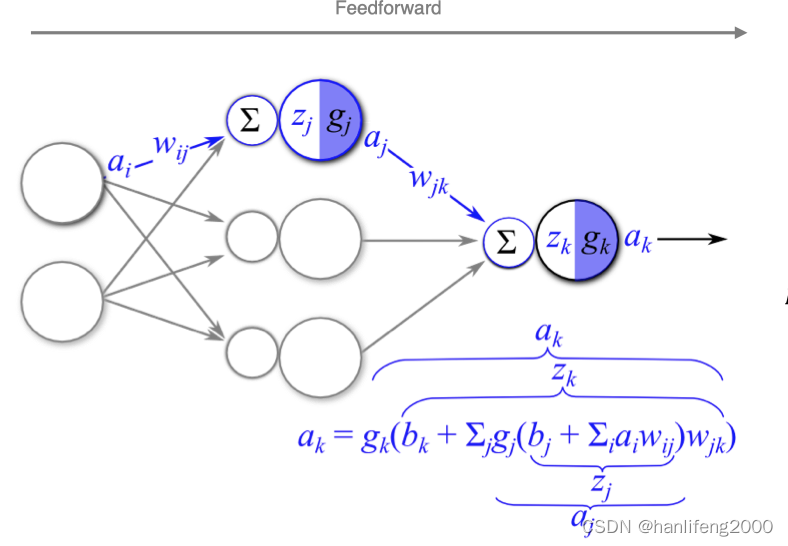
3.梯度下降优化方法

3.1 动量梯度下降
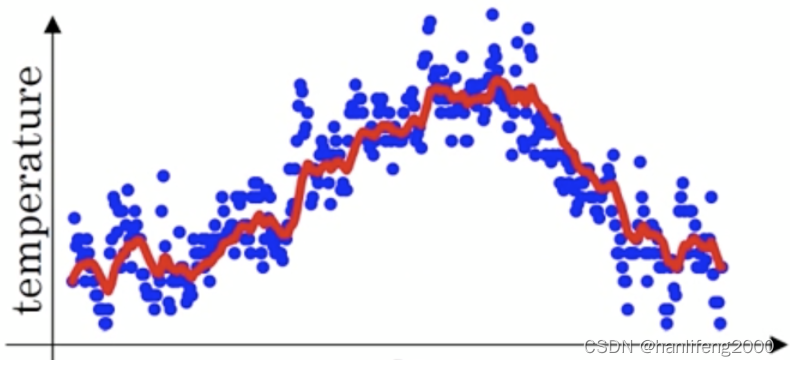
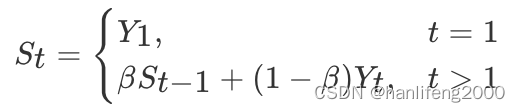

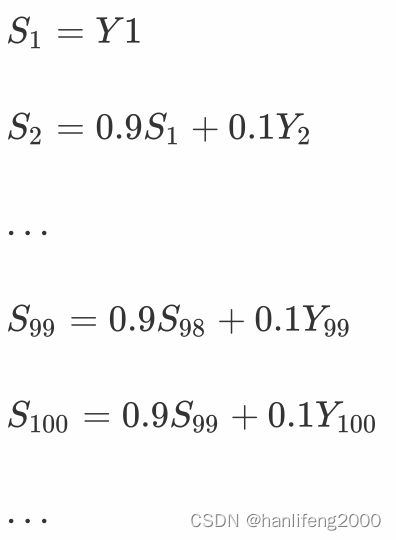
那么第
100
天的结果就可以表示为:
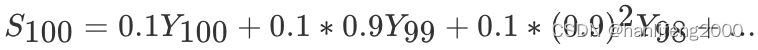
动量梯度下降(
Gradient Descent with Momentum
)计算梯度的指数加权
平均数,并利⽤该值来更新参数值。动量梯度下降法的整个过程为,其中
β
通常设置为
0.9
:
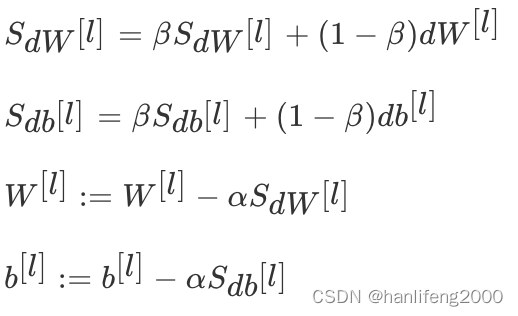
import tensorflow as tf
#实例化
opt=tf.keras.optimizers.SGD(learning_rate=0.1,momentum=0.9)
var=tf.Variable(1.0)
var0=var.value()
#定义损失函数
loss=lambda:(var**2)/2.0
#第一次更新
opt.minimize(loss,var_list=var)
var1=var.value()
#第二次更新
opt.minimize(loss,var_list=var)
var2=var.value()
print(var0)
print(var1)
print(var2)
#运行结果
#tf.Tensor(1.0, shape=(), dtype=float32)
#tf.Tensor(0.9, shape=(), dtype=float32)
#tf.Tensor(0.71999997, shape=(), dtype=float32)
#运行结果3.2 AdaGrad
AdaGrad:全称Adaptive Gradient,自适应梯度,是梯度下降优化算法的扩展。AdaGrad是一种具有自适应学习率的梯度下降优化方法。它非常适合处理稀疏数据。AdaGrad可大大提高SGD的鲁棒性。
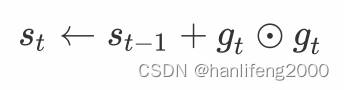
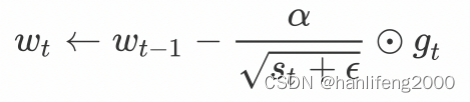
# 导⼊相应的⼯具包
import tensorflow as tf
# 实例化优化⽅法:SGD
opt = tf.keras.optimizers.Adagrad(
learning_rate=0.1,
initial_accumulator_value=0.1,
epsilon=1e-06
)
# 定义要调整的参数
var = tf.Variable(1.0)
# 定义损失函数:⽆参但有返回值
def loss(): return (var ** 2)/2.0
# 计算梯度,并对参数进⾏更新,
opt.minimize(loss, [var]).numpy()
# 展示参数更新结果
var.numpy()














 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









