








1.贝叶斯公式推理:
A和B是两个事件,在B发生的条件下,A发生的条件概率记为![]()
条件概率![]() :
:![]() (1)
(1)
条件概率![]() :
:![]() (2)
(2)
(2)式得![]() 将其代入(1)得到贝叶斯公式:
将其代入(1)得到贝叶斯公式:

可以写为
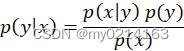
表示没有使用数据来训练分类器之前y的初始概率,称为先验概率。
是样本x相对于类别y的类条件概率,称为似然。
是给定x时y成立的概率,称为后验概率。
是归一化的证据因子。
2.朴素贝叶斯分类实现步骤:
朴素贝叶斯处理:假设x中的特征是条件独立的,各类数据中,各特征的条件概率
① 设
为一个待分类项,而每个x都为特征属性。
② 类别集合
,计算先验概率
③ 根据贝叶斯公式,计算各特征的各条件概率的乘积,
,
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
④ 如果
,则
。也就是结果中的最大值就是该样本所属的类别。
⑤ 使用规范化方法计算
的概率。
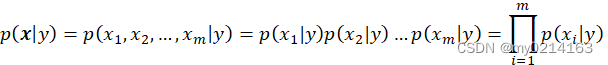

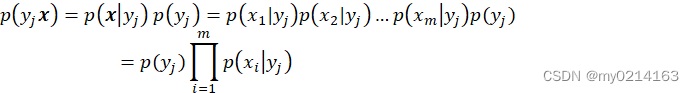

3.例题:
以下是某公司招录人员的信息表,将其作为训练集,运用朴素贝叶斯算法实现预测新样本
![]() 是否被录用。
是否被录用。
| 性别 | 学历 | 学校 | 经验 | 是否录用 |
| 男 | 本科 | 985 | 无 | 是 |
| 女 | 本科 | 211 | 无 | 是 |
| 男 | 研究生 | 普通院校 | 有 | 是 |
| 男 | 大专 | 普通院校 | 有 | 否 |
| 女 | 本科 | 985 | 无 | 是 |
| 男 | 研究生 | 普通院校 | 有 | 是 |
| 男 | 本科 | 211 | 无 | 是 |
| 男 | 大专 | 普通院校 | 有 | 否 |
| 男 | 本科 | 普通院校 | 无 | 否 |
| 女 | 本科 | 普通院校 | 有 | 否 |
| 男 | 本科 | 211 | 无 | 是 |
| 男 | 研究生 | 211 | 无 | 是 |
假设全部属性都对决策有着相同的重要性,且相互条件独立。
① 按照训练样本的类别统计每个属性的取值次数,统计结果如下表所示:
| 性别x1 | 学历x2 | 学校x3 | 经验x4 | 是否录用 | |||||||||
| 是 | 否 | 是 | 否 | 是 | 否 | 是 | 否 | 是 | 否 | ||||
| 男 | 6 | 3 | 大专 | 0 | 2 | 985 | 2 | 0 | 有 | 2 | 3 | 8 | 4 |
| 女 | 2 | 1 | 本科 | 5 | 2 | 211 | 4 | 0 | 无 | 6 | 1 | ||
| 研究生 | 3 | 0 | 普通院校 | 2 | 4 | ||||||||
② 计算先验概率![]() 。
。![]() 有2个取值{是,否}分别为
有2个取值{是,否}分别为![]()
![]()
![]()
③ 根据贝叶斯公式,计算各特征的各条件概率的乘积
![]() 有4个取值{性别,学历,学校,经验}分别为
有4个取值{性别,学历,学校,经验}分别为![]()
![]() 取值分别为
取值分别为![]() =‘男’,
=‘男’, ![]() =‘女’
=‘女’
![]() 取值分别为
取值分别为![]() =‘大专’,
=‘大专’, ![]() =‘本科’,
=‘本科’, ![]() =‘研究生’
=‘研究生’
![]() 取值分别为
取值分别为![]() =‘985’,
=‘985’, ![]() =‘211’,
=‘211’,![]() =‘普通院校’
=‘普通院校’
![]() 取值分别为
取值分别为![]() =‘有’,
=‘有’, ![]() =‘无’
=‘无’
新样本可以表示为![]() ,带球概率分别为
,带球概率分别为
![]()
![]()
计算过程如下:
![]()
![]()
所以
![]()
所以
![]()
④ 由于![]() 可知,样本
可知,样本![]() 被分类为
被分类为![]() ,会被录取
,会被录取
⑤ 规范化方法计算![]() 的概率,就是计算新样本类别分别为
的概率,就是计算新样本类别分别为![]() 和
和![]() 的概率。
的概率。
根据以下公式计算:
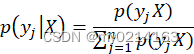
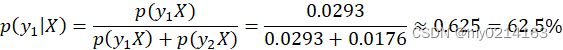
利用朴素贝叶斯算法分类得出该新样本被录取的概率为62.5%,因此可以被录取。
4 .应用:
例如:如下图有12封邮件,其中五封为垃圾邮件Spam 。其中七封为非垃圾邮件NSpam。

① 如上图所示,将所有邮件中出现'free'与'money'的标红。
② 计算先验概率
![]()
③ 各个词汇的条件概率p(x|y):
在垃圾邮件spam 邮件中,
出现'free'的概率为 ![]() 、即;
、即;![]()
根据条件概率,计算垃圾邮件中包含'free'单词的概率,
即![]()
在非垃圾邮件Nspam 邮件中,
出现'free'的概率为 ![]() 、 即
、 即![]()
根据条件概率,计算垃圾邮件中包含‘free’单词的概率,
即
![]()
④ 判断包含某个单词的邮件是否是垃圾邮件及其概率
包含'free'单词的邮件是垃圾邮件的概率:

包含'free'单词的邮件是非垃圾邮件的概率:
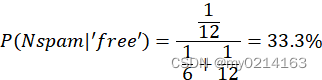
同理
![]()
![]()
![]()
包含'money'单词的邮件是垃圾邮件的概率:

包含'money'单词的邮件是非垃圾邮件的概率:
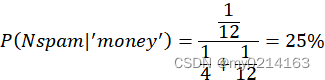
















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









