







总结不易,转载请声明原文地址!!!
文章目录
报文格式
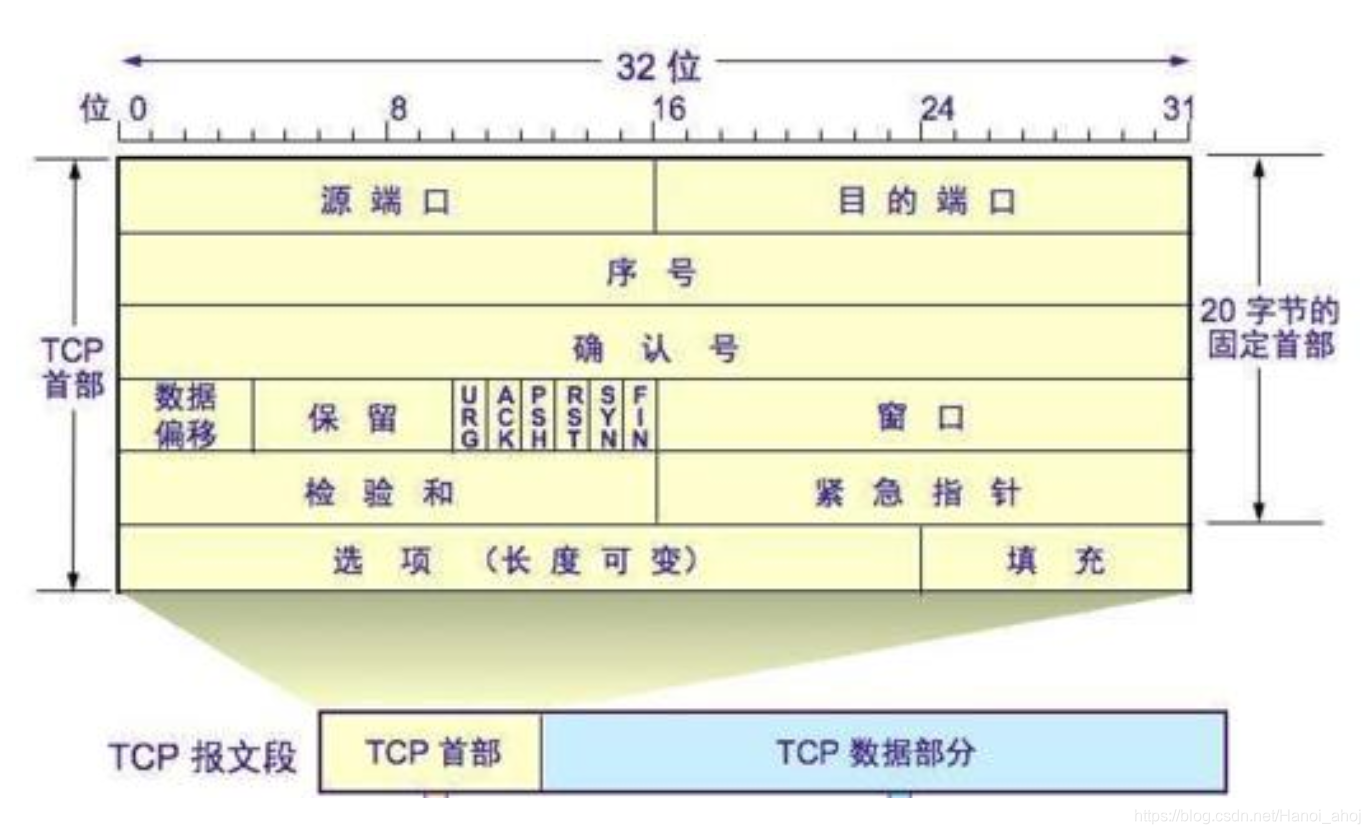
16 位源端口,16 位目的端口:
数据从何而来,去向何方。
32 位序号,32 位确认序号:
和 TCP 的 ACK 机制有关,发送端给数据进行编号,接收端收到数据后确认收到哪些编号的数据。
4 位报头长度:
表示 TCP 的首部占用多少个 4 字节。
6 个标志位:
- URG 紧急指针是否有效;
- ACK 确认号是否有效;
- PSH 提示接收端应用程序立刻从TCP缓冲区把数据读走;
- RST 复位标志,对方要求重新建立连接;
- SYN 同步标志,请求建立连接;
- FIN 结束标志,通知对方, 本端要关闭了。
16 位窗口大小:
和 TCP 滑动窗口相关,在下文。
16 位校验和:
发送端填充,CRC 校验,接收端校验不通过,则认为数据有问题。此处的检验和不光包含TCP首部,也包含TCP数据部分。
16 位紧急指针:
标识哪部分数据是紧急数据。
选项和填充位:
为了对其做相关填充?
一个 TCP 程序
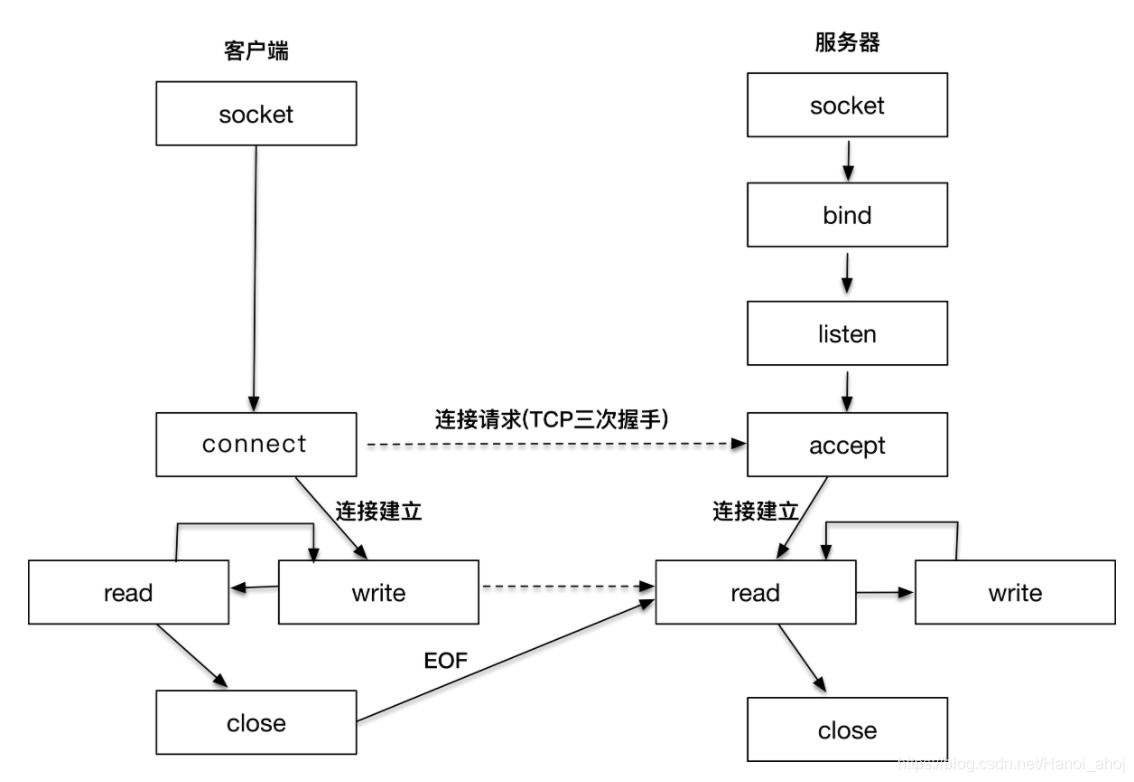
TCP 回显服务器:
#include <stdio.h>
#include <strings.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int main() {
// 1. 创建 socket
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (listen_fd < 0) {
perror("socket");
return -1;
}
int on = 1;
setsockopt(listen_fd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
// 2. bind ip 和 port
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(9090);
server_addr.sin_addr.s_addr = inet_addr("0.0.0.0");
if (bind(listen_fd, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0) {
perror("bind");
return -1;
}
// 3. 进入 listen 监听到来的连接
if (listen(listen_fd, 128) < 0) {
perror("listen");
return -1;
}
while (1) {
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(client_addr);
int connect_fd = accept(listen_fd, (struct sockaddr*)&client_addr, &client_addr_len);
if (connect_fd < 0) {
perror("accept");
continue;
}
printf("%s:%d is connected!\n", inet_ntoa(client_addr.sin_addr), ntohs(client_addr.sin_port));
while (1) {
char req[1024] = {0};
int n = read(connect_fd, req, sizeof(req));
if (n < 0) {
perror("read");
continue;
} else if (n == 0) {
printf("%s:%d is closed!\n", inet_ntoa(client_addr.sin_addr), ntohs(client_addr.sin_port));
close(connect_fd);
break;
} else {
req[n] = '\0';
printf("req from %s:%d is %s!\n", inet_ntoa(client_addr.sin_addr), ntohs(client_addr.sin_port), req);
char* resp = req;
int nw = write(connect_fd, req, strlen(req));
if (nw < 0) {
perror("write");
continue;
}
printf("resp for %s:%d is %s!\n", inet_ntoa(client_addr.sin_addr), ntohs(client_addr.sin_port), req);
}
}
}
close(listen_fd);
return 0;
}
TCP 回显客户端:
#include <stdio.h>
#include <string.h>
#include <strings.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int main() {
int socket_fd = socket(AF_INET, SOCK_STREAM, 0);
if (socket_fd < 0) {
perror("socket");
return -1;
}
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(9090);
server_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
if (connect(socket_fd, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0) {
perror("connect");
return -1;
}
while (1) {
printf("req> ");
char req[1024] = {0};
scanf("%s", req);
int n = write(socket_fd, req, strlen(req));
if (n < 0) {
perror("write");
continue;
}
char resp[1024] = {0};
n = read(socket_fd, resp, sizeof(resp));
if (n < 0) {
perror("read");
continue;
}
if (n == 0) {
printf("server closed!\n");
break;
}
printf("resp: %s\n", resp);
}
close(socket_fd);
return 0;
}
测试:

确认应答
主机A ======Data 1~1000======> 主机B
主机A <===收到 再从1001开始发=== 主机B
主机A =====Data 1001~2000=====> 主机B
主机A <===收到 再从2001开始发=== 主机B
TCP将每个字节的数据都进行了编号,即为序列号。
每一个ACK都带有对应的确认序列号,意思是告诉发送者,我已经收到了哪些数据;下一次你从哪里开始发。
超时重传
发送的数据未到达的情况:
主机A ======Data 1~1000======X 主机B
…等待一会,没有收到 主机B 的确认应答…
主机A =====Data 1~1000=====> 主机B
主机A <===收到 再从1001开始发=== 主机B
响应数据未到达的情况:
主机A ======Data 1~1000======> 主机B
主机A X===收到 再从1001开始发=== 主机B
…等待一会,没有收到 主机B 的确认应答…
主机A =====Data 1~1000=====> 主机B
主机A <===收到 再从1001开始发=== 主机B
主机A,主机B 可能因此会接收到多次同一个数据,TCP 会根据这些数据的序列号来去重。
超时时间是多少呢?
最理想的情况下, 找到一个最小的时间, 保证 “确认应答一定能在这个时间内返回”. 但是这个时间的长短, 随着网络环境的不同, 是有差异的;
如果超时时间设的太长, 会影响整体的重传效率;
如果超时时间设的太短, 有可能会频繁发送重复的包,造成计算、网络资源的浪费。
TCP为了保证无论在任何环境下都能比较高性能的通信, 因此会动态计算这个最大超时时间。
Linux 中(BSD Unix和Windows也是如此), 超时以 500ms 为一个单位进行控制, 每次判定超时重发的超时 时间都是500ms的整数倍;
如果重发一次之后, 仍然得不到应答, 等待 2x500ms 后再进行重传.
如果仍然得不到应答, 等待 4x500ms 进行重传. 依次类推, 以指数形式递增.
累计到一定的重传次数, TCP认为网络或者对端主机出现异常, 强制关闭连接。
连接管理
建立连接,三次握手
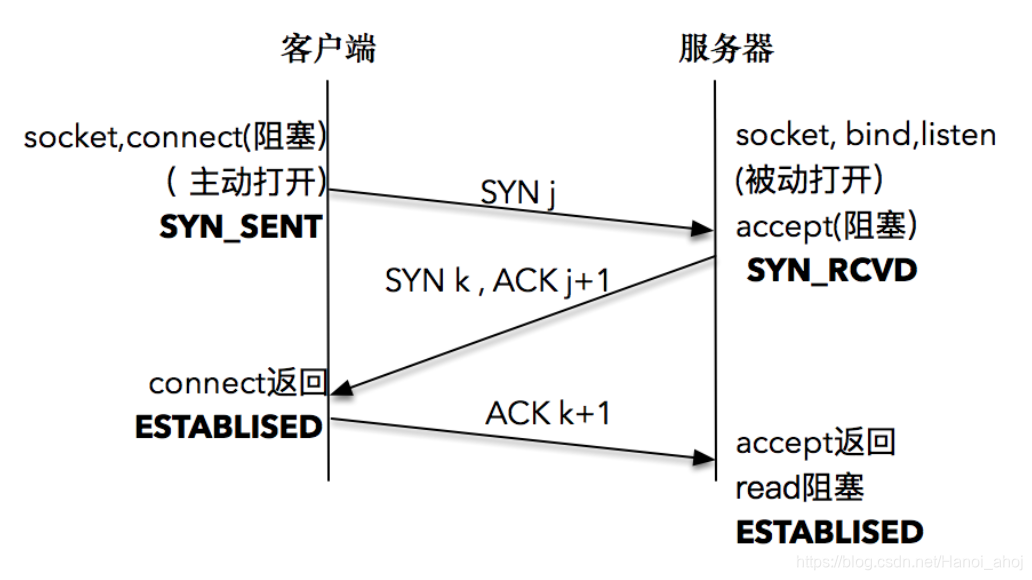
服务器端通过 socket,bind 和 listen 完成了被动套接字的准备工作,被动的意思就是等着别人来连接,然后调用 accept,就会阻塞在这里,等待客户端的连接来临;
客户端通过调用 socket 和 connect 函数之后,也会阻塞。接下来的事情是由操作系统内核完成的,更具体一点的说,是操作系统内核网络协议栈在工作。
三次握手流程:
- 客户端的协议栈向服务器端发送了 SYN 包,并告诉服务器端当前发送序列号 j,客户端进入 SYNC_SENT 状态;
- 服务器端的协议栈收到这个包之后,和客户端进行 ACK 应答,应答的值为 j+1,表示对 SYN 包 j 的确认,同时服务器也发送一个 SYN 包,告诉客户端当前我的发送序列号为 k,服务器端进入 SYNC_RCVD 状态;
- 客户端协议栈收到 ACK 之后,使得应用程序从 connect 调用返回,表示客户端到服务器端的单向连接建立成功,客户端的状态为 ESTABLISHED,同时客户端协议栈也会对服务器端的 SYN 包进行应答,应答数据为 k+1;
- 应答包到达服务器端后,服务器端协议栈使得 accept 阻塞调用返回,这个时候服务器端到客户端的单向连接也建立成功,服务器端也进入 ESTABLISHED 状态。
客户端状态变化:
客户端调用 socket() 后,进入 CLOSED 状态。
客户端调用 connect(),发送 SYN 报文,进入 SYN_SENT 状态。
客户端在收到刚刚 SYN 报文的 ACK 后,进入 ESTABLISHED 状态,从 connect()`返回。
服务端状态变化:
服务器调用 socket() 后,进入 CLOSED 状态。
服务器调用 bind(), listen() 后进入 LISTEN 状态,等待客户端连接,阻塞在 accept()。
收到 SYN 报文后进入 SYN_RCVD 状态,就将该连接放入内核等待队列中,返回 SYN + ACK 报文。
在客户端收到后,发送 ACK 报文,服务器从 accept() 返回,进入 ESTABLISHED 状态。
至此连接建立完成,客户端、服务端都进入了 已连接 状态,即 ESTABLISHED。
使用 tcpdump 和 telnet 查看三次握手:
启动服务端:./server
打开 tcpdump 监听指定网卡:sudo tcpdump -i lo
启动客户端:./client,因为我们代码写的是启动后建立连接。
22:42:38.807167 IP localhost.56812 > localhost.websm: Flags [S], seq 392207921, win 43690, options [mss 65495,sackOK,TS val 1925178850 ecr 0,nop,wscale 7], length 0
05:21:45.034393 IP localhost.websm > localhost.56812: Flags [S.], seq 3840980020, ack 392207922, win 43690, options [mss 65495,sackOK,TS val 1925178850 ecr 1925178850,nop,wscale 7], length 0
22:42:38.807193 IP localhost.56812 > localhost.websm: Flags [.], ack 1, win 342, options [nop,nop,TS val 1925178850 ecr 1925178850], length 0
注意到了没得,第三次 ack = 1,为什么呢?为啥不和第二次的 ack 一样是上一次的 seq + 1 呢?
答案在此:https://segmentfault.com/a/1190000019590737
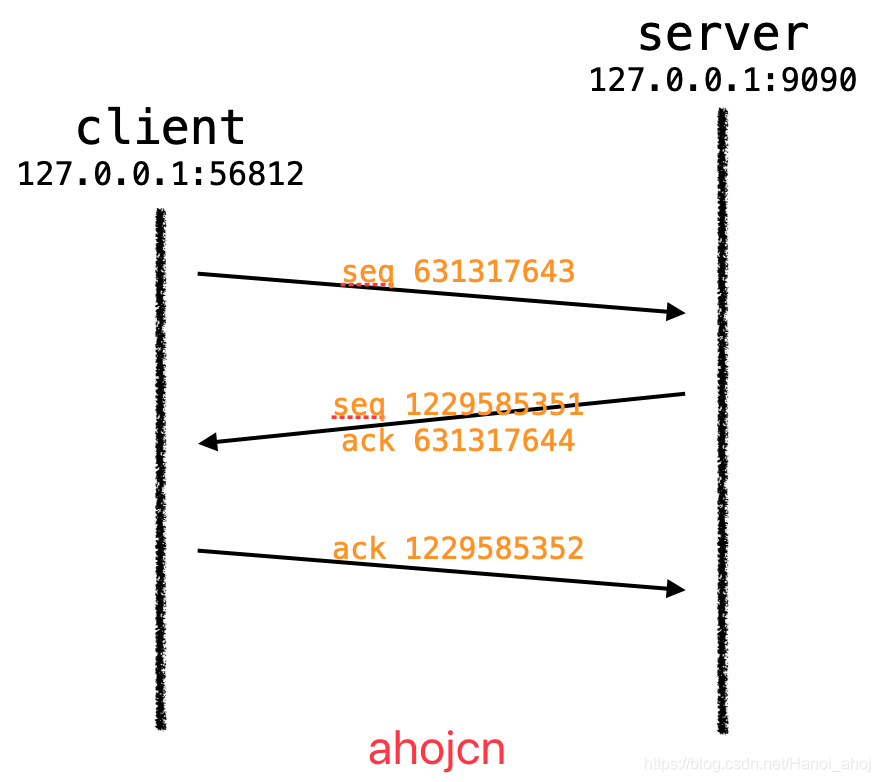
重新开启,得到数据如下:
23:01:43.908508 IP localhost.56816 > localhost.websm: Flags [S], seq 631317643, win 43690, options [mss 65495,sackOK,TS val 1926323951 ecr 0,nop,wscale 7], length 0
03:31:17.525111 IP localhost.websm > localhost.56816: Flags [S.], seq 1229585351, ack 631317644, win 43690, options [mss 65495,sackOK,TS val 1926323951 ecr 1926323951,nop,wscale 7], length 0
23:01:43.908539 IP localhost.56816 > localhost.websm: Flags [.], ack 1229585352, win 342, options [nop,nop,TS val 1926323951 ecr 1926323951], length 0
因为整个过程并没有发生应用层数据交换,所以 length = 0。
关闭连接,四次挥手
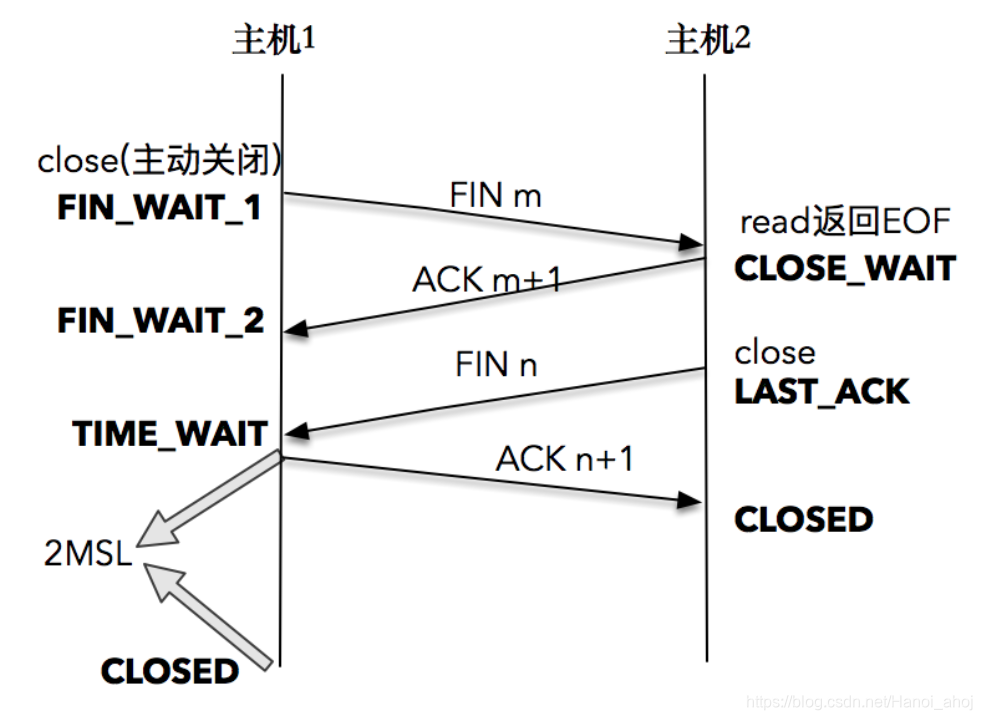
TCP 连接终止时,主机 1 先发送 FIN 报文,主机 2 进入 CLOSE_WAIT 状态,并发送一个 ACK 应答,同时,主机 2 通过 read 调用获得 EOF,并将此结果通知应用程序进行主动关闭操作,发送 FIN 报文。主机 1 在接收到 FIN 报文后发送 ACK 应答,此时主机 1 进入 TIME_WAIT 状态。
假设 主机1 为客户端,主机2 为服务端。
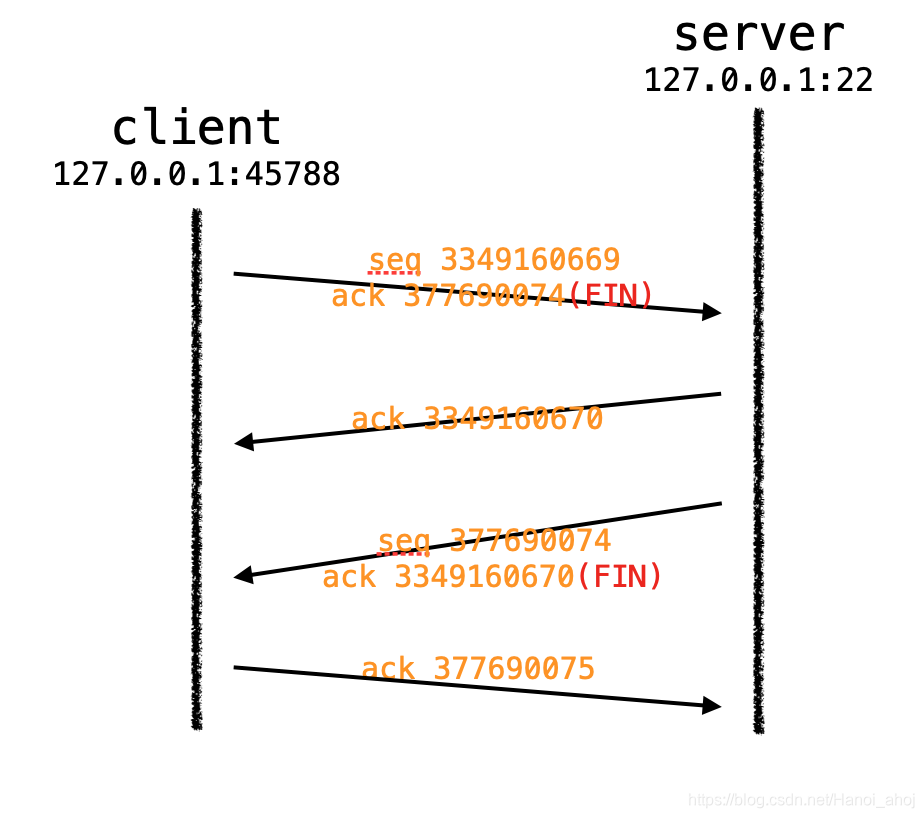
tcpdump、telnet 查看四次挥手:
23:13:14.956630 IP localhost.45788 > localhost.ssh: Flags [F.], seq 3349160669, ack 377690074, win 342, options [nop,nop,TS val 1927014999 ecr 1927003705], length 0
23:13:14.956738 IP localhost.ssh > localhost.45788: Flags [.], ack 3349160670, win 342, options [nop,nop,TS val 1927015000 ecr 1927014999], length 0
23:13:14.959316 IP localhost.ssh > localhost.45788: Flags [F.], seq 377690074, ack 3349160670, win 342, options [nop,nop,TS val 1927015002 ecr 1927014999], length 0
23:13:14.959328 IP localhost.45788 > localhost.ssh: Flags [.], ack 377690075, win 342, options [nop,nop,TS val 1927015002 ecr 1927015002], length 0
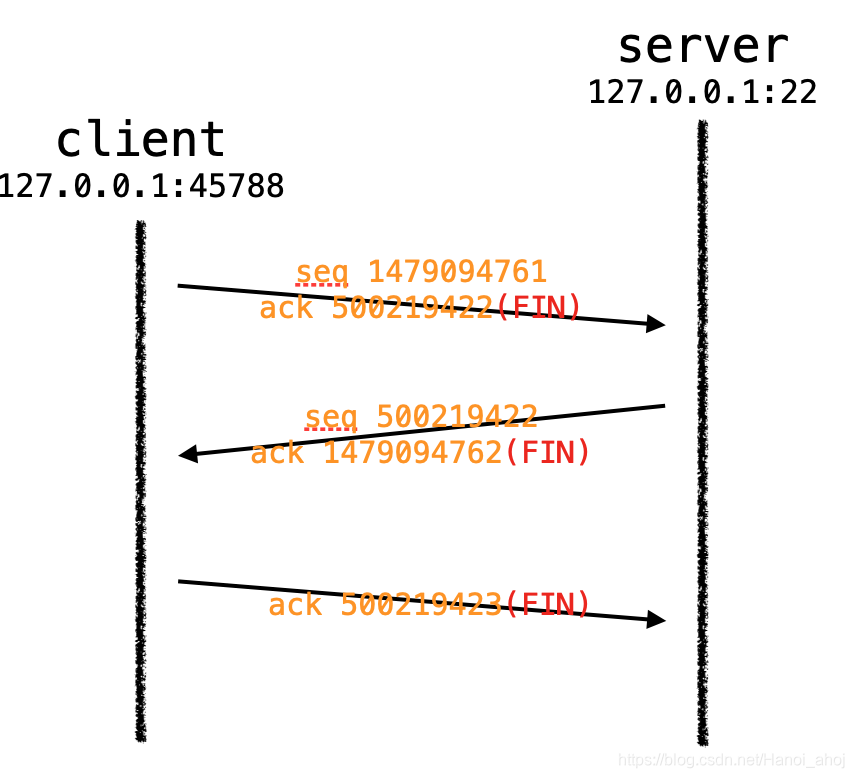
注意一点:有的时候 tcpdump 抓取的挥手包只有 3 条,像下面这样:
09:52:33.611679 IP localhost.56920 > localhost.websm: Flags [F.], seq 1479094761, ack 500219422, win 342, options [nop,nop,TS val 1937833183 ecr 1937829520], length 0
09:52:33.611737 IP localhost.websm > localhost.56920: Flags [F.], seq 500219422, ack 1479094762, win 342, options [nop,nop,TS val 1937833183 ecr 1937833183], length 0
09:52:33.611744 IP localhost.56920 > localhost.websm: Flags [.], ack 500219423, win 342, options [nop,nop,TS val 1937833183 ecr 1937833183], length 0
这是 TCP 的捎带 ACK 机制。
被动关闭端将 FIN 的 ACK 和自己的 FIN 包一起发给了主动发送端。
客户端、服务端状态变化:
客户端调用 close(),发送一个 FIN 报文给服务端,客户端进入 FIN_WAIT_1 状态。
服务端收到 FIN 报文,响应一个 ACK,也进入 CLOSE_WAIT 状态。服务器 read() 获取到了 EOF,并执行 close(),发送 FIN 报文,此时进入 LAST_ACK 状态。
客户端收到服务器关于 FIN 的 ACK 报文,进入 FIN_WAIT_2 状态。
客户端收到服务器的 FIN 报文,进入 TIME_WAIT 状态,发送 FIN 的响应 ACK 给服务端。
客户端会在 TIME_WAIT 状态等待 2MSL,然后进入 CLOSED 状态。
MSL(maximum segment lifetime)最长分节生命期。
Linux 系统里有一个硬编码的字段,名称为TCP_TIMEWAIT_LEN,其值为 60 秒。也就是说,Linux 系统停留在 TIME_WAIT 的时间为固定的 60 秒。
查看 MSL:cat /proc/sys/net/ipv4/tcp_fin_timeout
TIME_WAIT 状态
只有发起连接终止的一方会进入 TIME_WAIT 状态!
TIME_WAIT 的状态可能会超出进程的生命周期!
TIME_WAIT 的引入是为了让 TCP 报文得以自然消失,同时为了让被动关闭方能够正常关闭。
将上面的 TCP 回显服务器、客户端启动后,ctrl + c 结束,再次启动 server 就会出现这样的情况:

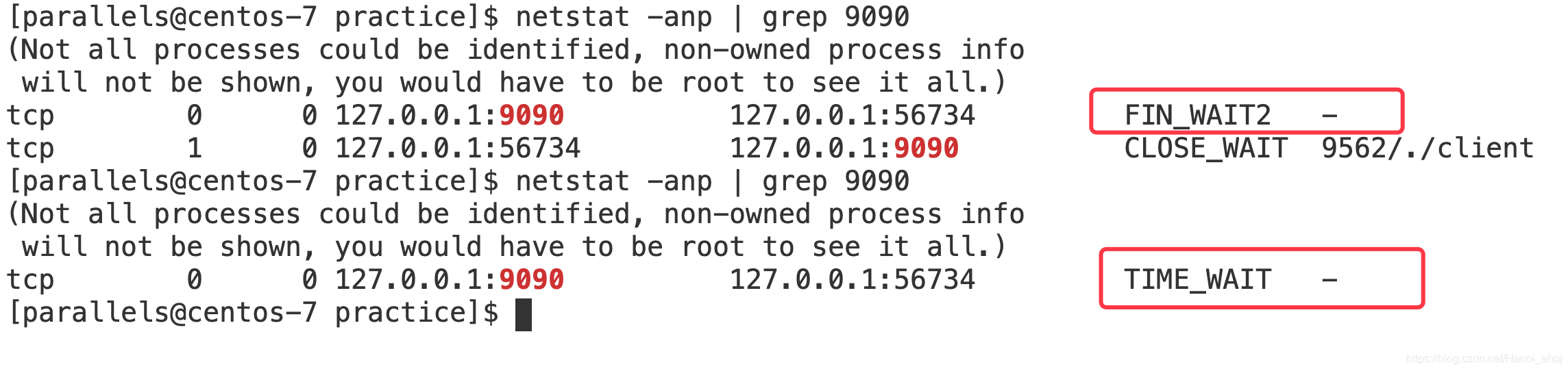
为什么要有这个 TIME_WAIT 状态,而不直接进入 CLOSED?
1、为了确保最后的 ACK 能让被动关闭方接收,从而帮助其正常关闭。
TCP 假设报文会出错,需要重传。
如果主机1给主机2回的 ACK 报文丢了,那主机2就当主机1没有收到,触发主机2的超时重传,重新发送 FIN 报文。这样处在 TIME_WAIT 状态的主机1还是可以收到这个 FIN 报文并且回复 ACK n+1 的,这样就可以确保对端也可以正常关闭。
如果主机 1 没有维护 TIME_WAIT 状态,而直接进入 CLOSED 状态,它就失去了当前状态的上下文,只能回复一个 RST 操作,从而导致被动关闭方出现错误。
如果在 TIME_WAIT 时间内,因为主机 1 的 ACK 没有传输到主机 2,主机 1 又接收到了主机 2 重发的 FIN 报文,那么 2MSL 时间将重新计时。
2MSL 的时间是从主机 1 接收到 FIN 后发送 ACK 开始计时的!
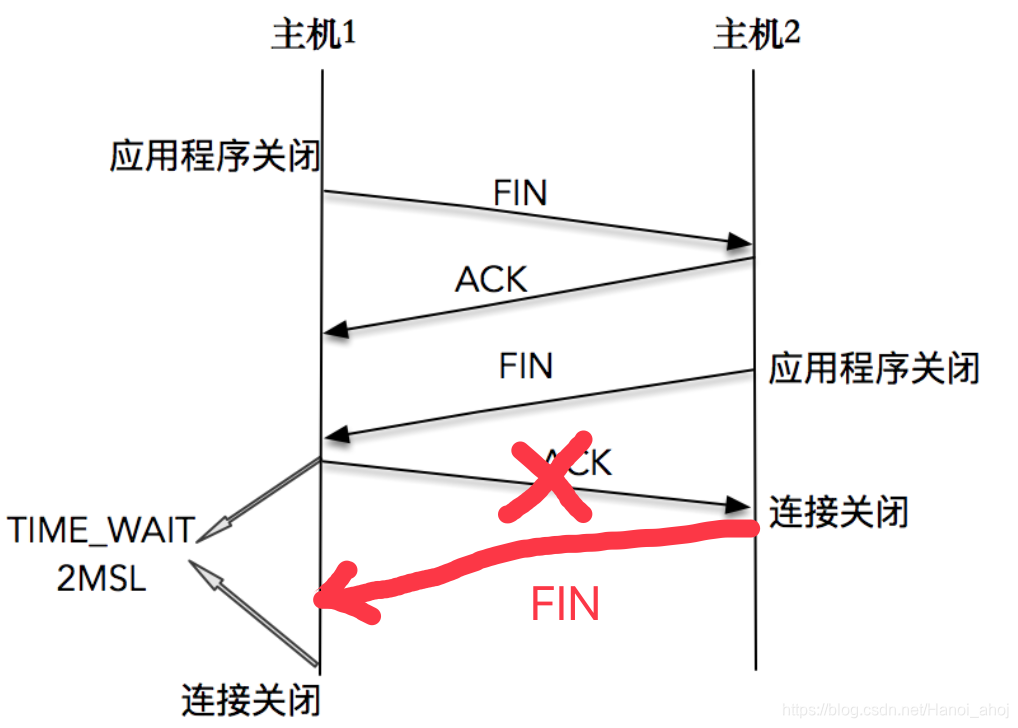
2、和连接“化身”和报文迷走有关系,为了让旧连接的重复分节在网络中自然消失。
在网络中,经常会发生报文经过一段时间才能到达目的地的情况,产生的原因是多种多样的,如路由器重启,链路突然出现故障等。如果迷走报文到达时,发现 TCP 连接四元组(源 IP,源端口,目的 IP,目的端口)所代表的连接不复存在,那么很简单,这个报文自然丢弃。我们考虑这样一个场景,在原连接中断后,又重新创建了一个原连接的“化身”,说是化身其实是因为这个连接和原先的连接四元组完全相同,如果迷失报文经过一段时间也到达,那么这个报文会被误认为是连接“化身”的一个 TCP 分节,这样就会对 TCP 通信产生影响。
所以,TCP 就设计出了这么一个机制,经过 2MSL 这个时间,足以让两个方向上的分组都被丢弃,使得原来连接的分组在网络中都自然消失,再出现的分组一定都是新化身所产生的。
为甚是 2MSL?不是 1MSL 或 3MSL?
保证在两个传输方向 上的尚未被接收或迟到的报文段都已经消失(否则服务器立刻重启, 可能会收到 来自上一个进程的迟到的数据, 但是这种数据很可能是错误的)。
因为客户端—ACK—> 服务端 需要 MSL
服务端 —FIN—> 客户端 也需要 MSL,所以需要 2MSL。
TIME_WAIT 的危害?
- 内存资源占用,进程以及关闭,操作系统还在维护着一个 TIME_WAIT 状态处理一些迟到的响应。
- 对端口资源的占用,一个 TCP 连接至少消耗一个本地端口。如果 TIME_WAIT 状态过多,会导致无法创建新连接。就是上面的栗子,服务器再次启动会出现 address already in used。
如何优化 TIME_WAIT?
-
通过 sysctl 命令,将系统值调小。这个值默认为 18000,当系统中处于 TIME_WAIT 的连接一旦超过这个值时,系统就会将所有的 TIME_WAIT 连接状态重置,并且只打印出警告信息。
-
调低 TCP_TIMEWAIT_LEN,重新编译系统。
-
设置 SO_LINGER。linger,停留。
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen); struct linger { int l_onoff; /* 0=off, nonzero=on */ int l_linger; /* linger time, POSIX specifies units as seconds */ }; struct linger so_linger; so_linger.l_onoff = 1; so_linger.l_linger = 0; setsockopt(s,SOL_SOCKET,SO_LINGER, &so_linger,sizeof(so_linger));如果 l_onoff 为 0,那么关闭本选项。l_linger 的值被忽略,这对应了默认行为,close 或 shutdown 立即返回。如果在套接字发送缓冲区中有数据残留,系统会将试着把这些数据发送出去。
如果 l_onoff 为非 0, 且 l_linger 值也为 0,那么调用 close 后,会立该发送一个 RST 标志给对端,该 TCP 连接将跳过四次挥手,也就跳过了 TIME_WAIT 状态,直接关闭。这种关闭的方式称为“强行关闭”。 在这种情况下,排队数据不会被发送,被动关闭方也不知道对端已经彻底断开。只有当被动关闭方正阻塞在recv()调用上时,接受到 RST 时,会立刻得到一个“connet reset by peer”的异常。
如果 l_onoff 为非 0, 且 l_linger 的值也非 0,那么调用 close 后,调用 close 的线程就将阻塞,直到数据被发送出去,或者设置的l_linger计时时间到。
-
设置 net.ipv4.tcp_tw_reuse
从协议角度理解如果是安全可控的,可以复用处于 TIME_WAIT 的套接字为新的连接所用。
不要试图使用SO_LINGER设置套接字选项,跳过 TIME_WAIT;
CLOSE_WAIT 状态
比如主机2是服务器,主机1是客户端。
如果在服务器上出现大量的 CLOSE_WAIT 状态,如何解决?
对于服务器上出现大量的 CLOSE_WAIT 状态, 原因就是服务器没有正确的关闭 socket, 导致四次挥手没有正确完成. 这是一个 BUG. 只需要加上对应的 close 即可解决问题。
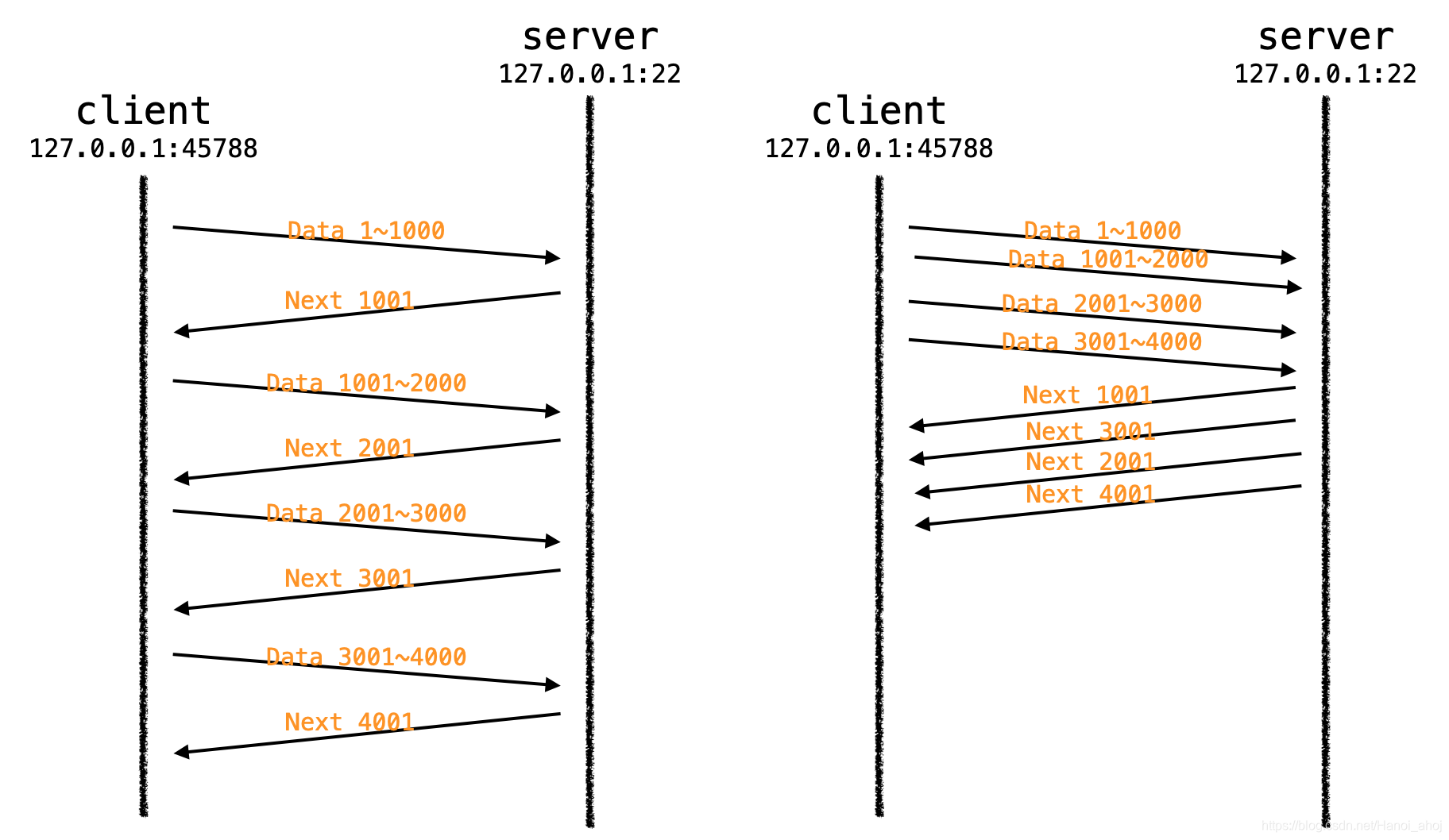
滑动窗口
对于 ACK 机制,如果每次发送完一条信息,等待对方回应再发第二条,接着等第二条回应……
这样做有一个比较大的缺点,就是性能较差,尤其是数据往返的时间较长的时候。
为了让效率更高,TCP 设计了滑动窗口这个东西。
在上文中使用 tcpdump 抓的包中可以看到 win 字段,对应 TCP 报头中的窗口大小。
需要注意的是,TCP 报文的窗口字段只有 2 个字节,可以表示的范围是 0-65535,那么TCP窗口最大就是65535字节么?
不是咯,TCP首部40字节选项中还包含了一个窗口扩大因子M, 实际窗口大小是窗口字段的值左移 M 位。
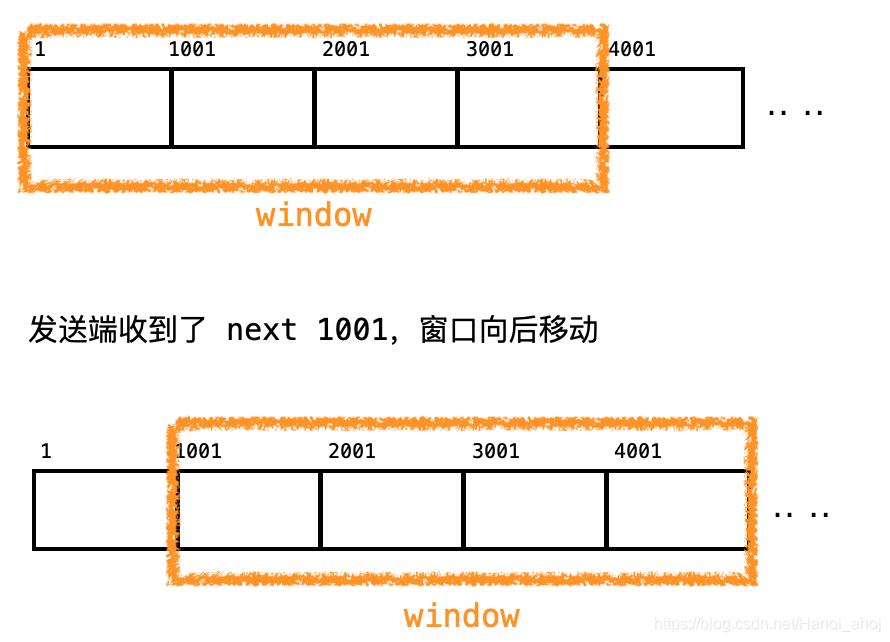
窗口大小指的是无需等待确认应答而可以继续发送数据的最大值,上图的窗口大小就是4000个字节(四个 段)。
发送前四个段的时候, 不需要等待任何ACK, 直接发送。
收到第一个ACK后, 滑动窗口向后移动, 继续发送第五个段的数据,依次类推。
操作系统内核为了维护这个滑动窗口, 有一个发送缓冲区 来记录当前还有哪些数据没有应答; 只有确认应答过的数据, 才能从缓冲区删掉。
窗口越大, 则网络的吞吐率就越高。
但是!窗口不能无限大,发送方发的太快,接收方可能处理不过来:
- 接收方的缓冲区满了,发送方发的数据就会被丢弃,发送方没有收到 ACK 会继续重发,导致资源浪费,这个就 TCP 也做了约定,就是下文的 流量控制。
- 当前网络状态不好,发送方发太快,很多数据都丢了,发送方会重发,这个也有解决方法,下文的 拥塞控制。
发送端需要合理的设置窗口大小,如果过小,引起明显的网络延迟;如果多大,容易造成网络拥塞。
流量控制
接收端处理数据的速度是有限的. 如果发送端发的太快, 导致接收端的缓冲区被打满, 这个时候如果发送端继续发送, 就会造成丢包, 继而引起丢包重传等等一系列连锁反应.
因此TCP支持根据接收端的处理能力, 来决定发送端的发送速度. 这个机制就叫做流量控制(Flow Control)。
接收端将自己可以接收的缓冲区大小放入 TCP 首部中的 “窗口大小” 字段, 通过ACK端通知发送端; 窗口大小字段越大, 说明网络的吞吐量越高;
接收端一旦发现自己的缓冲区快满了, 就会将窗口大小设置成一个更小的值通知给发送端;
发送端接受到这个窗口之后, 就会减慢自己的发送速度;
如果接收端缓冲区满了, 就会将窗口置为0; 这时发送方不再发送数据, 但是需要定期发送一个窗口探测数 据段, 使接收端把窗口大小告诉发送端.

拥塞控制
Linux 下拥塞控制有多种算法实现:reno 算法、vegas 算法、cubic 算法。
查看当前机器的拥塞控制算法:cat /proc/sys/net/ipv4/tcp_congestion_control
cubic
拥塞控制的最终受控变量就是发送端向网络一次连续写入的数据量(收到其中第一个数据的确认之前),也就是发送窗口SendWindow,简称 SWND。
RWND,接收端窗口大小。CWND,拥塞窗口(Congestion Window)。
实际的 SWND 值是 RWND 和 CWND 中的较小值。
慢启动和拥塞避免
虽然TCP有了滑动窗口这个大杀器, 能够高效可靠的发送大量的数据。但是如果在刚开始阶段就发送大量的数据, 仍然可能引发问题。网络上有很多的计算机, 可能当前的网络状态就已经比较拥堵. 在不清楚当前网络状态下, 贸然发送大量的数据, 是很有可能引起雪上加霜的。
TCP引入慢启动机制, 先发少量的数据, 探探路, 摸清当前的网络拥堵状态, 再决定按照多大的速度传输数据。
慢启动是一种发送端在未检测到拥塞时所采用的积极的避免拥塞的方法。
慢启动的思想是:TCP 模块刚开始发送数据并不知道网络的实际情况,需要用一种试探的方式平滑的增加 CWND 的大小。
慢启动不加控制的话必然使得 CWND 很快膨胀,并最终导致网络拥塞。
因此 TCP 拥塞控制中定义了一种重要的状态变量:慢启动门限(slow start threshold size,ssthresh)。当 CWND 的大小超过该值时,TCP 拥塞控制进入拥塞避免阶段。
拥塞避免算法使得 CWND 按照线性方式增加,从而减缓其扩大。
TCP 拥塞控制这样的过程, 就好像热恋的感觉。
在拥塞发生前使用慢启动来积极的避免拥塞,那么当拥塞发生的时候,发送端如何判断拥塞已经发生呢?
发送端判断拥塞发生时的依据有如下两个:
- 传输超时,或者说 TCP 重传定时器溢出。
- 接收到重复的确认报文段。
如果发送端检测到传输超时的时候,那么它将执行重传并将慢启动门限进行调整。
慢启动阈值 (ssthresh) 会变成原来的一半, 同时拥塞窗口置回1。
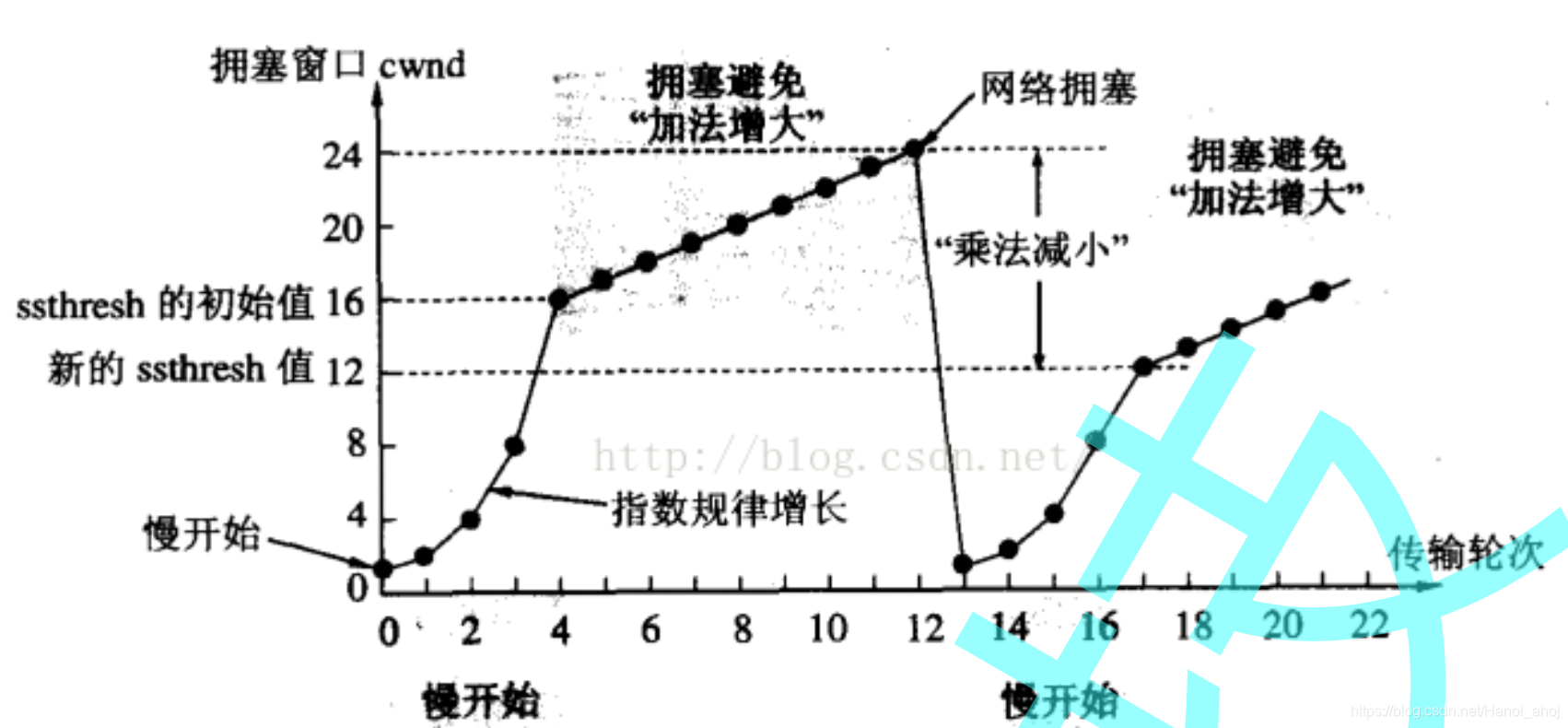
快速重传和快速恢复
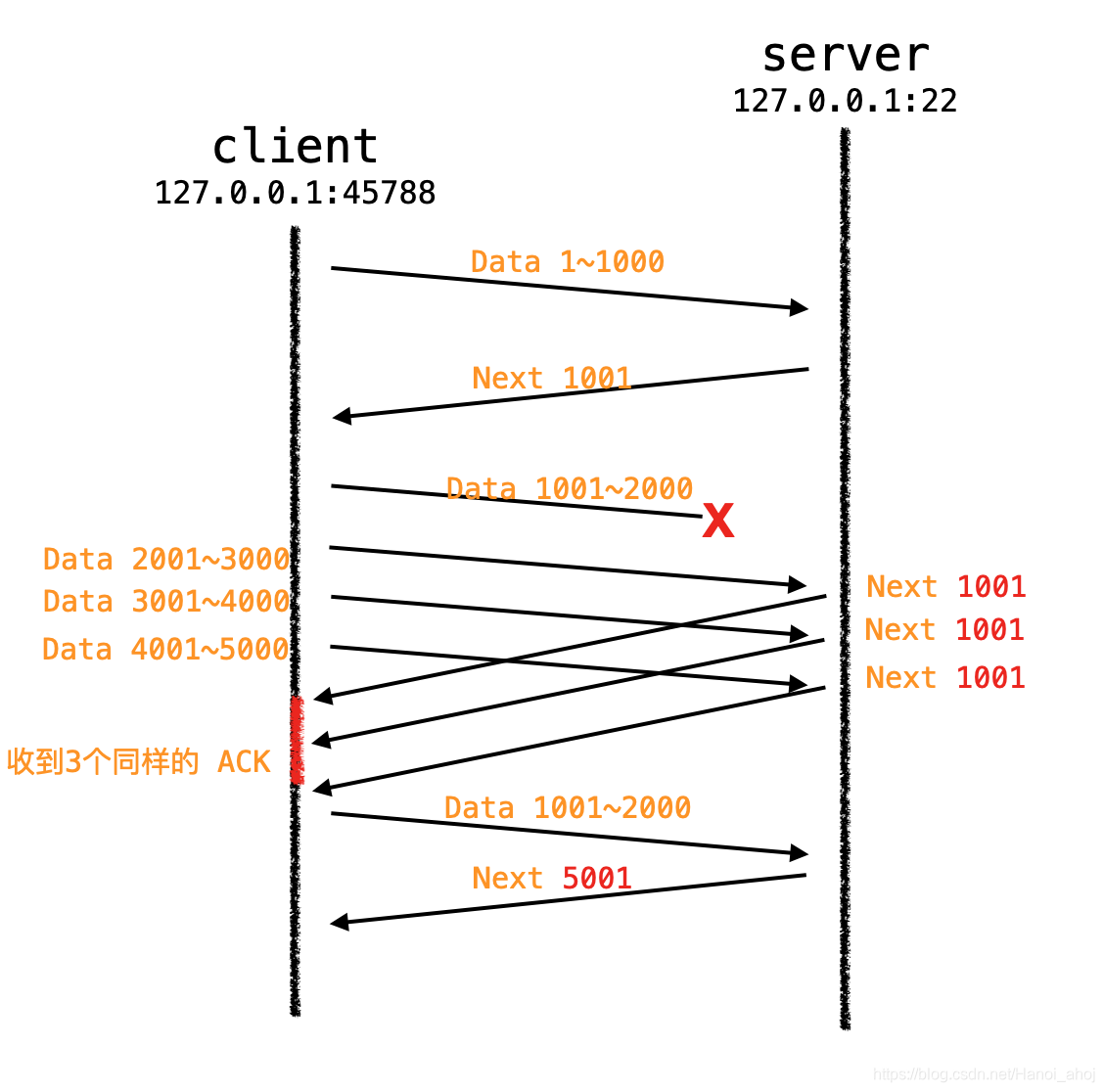
很多情况下,发送端都可能收到重复的 ACK 报文,比如 TCP 报文丢失,或者接收端收到乱序的 TCP 报文段并重排等。
拥塞控制算法需要判断当收到重复的确认报文段时,是否真的发生了拥塞,或者说 TCP 报文是否真的丢失了。具体的做法就是:发送端如果连续收到 3 个重复的确认报文段,就认为拥塞发生了。
然后发送端启用快速重传、快速恢复算法来处理拥塞。当快速重传和快速恢复完成之后,拥塞控制将恢复到拥塞避免阶段。
延时应答和捎带应答
延时应答举例:
每次叫了一辆大货车,只送了一个小水壶。每次只发 3 个字节的数据,却有一个 40 字节的头部。
这种情况需要在发送端进行优化。这个优化的算法叫做 Nagle 算法,Nagle 算法的本质其实就是限制大批量的小数据包同时发送,为此,它提出,在任何一个时刻,未被确认的小数据包不能超过一个。这里的小数据包,指的是长度小于最大报文段长度 MSS 的 TCP 分组。这样,发送端就可以把接下来连续的几个小数据包存储起来,等待接收到前一个小数据包的 ACK 分组之后,再将数据一次性发送出去。
捎带应答举例:
接收端需要对每个接收到的 TCP 分组进行确认,也就是发送 ACK 报文,但是 ACK 报文本身是不带数据的分段,如果一直这样发送大量的 ACK 报文,就会消耗大量的带宽。之所以会这样,是因为 TCP 报文、IP 报文固有的消息头是不可或缺的,比如两端的地址、端口号、时间戳、序列号等信息。
需要在接收端进行优化,这个优化的算法叫做延时 ACK。延时 ACK 在收到数据后并不马上回复,而是累计需要发送的 ACK 报文,等到有数据需要发送给对端时,将累计的 ACK捎带一并发送出去。当然,延时 ACK 机制,不能无限地延时下去,否则发送端误认为数据包没有发送成功,引起重传,反而会占用额外的网络带宽。
除非我们对此有十足的把握,否则不要轻易改变默认的 TCP Nagle 算法。因为在现代操作系统中,针对 Nagle 算法和延时 ACK 的优化已经非常成熟了,有可能在禁用 Nagle 算法之后,性能问题反而更加严重。
EOF
参考:《Linux 高性能服务器编程》《网络编程实战》














 484
484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









