







这是一个完整的利用Suft快速近邻匹配的程序
#include <opencv2/nonfree/nonfree.hpp>
#include <opencv2/nonfree/features2d.hpp>
#include <opencv.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <iostream>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/core/core.hpp>
#include <vector>
#include <math.h>
#include <opencv2/legacy/legacy.hpp>
using namespace std;
using namespace cv;
double Calcoefficient(const Mat &src1 , const Point2f key1 , const Mat &src2 , const Point2f key2) ;//用于计算匹配点之间的相关系数
Mat src1 ; Mat src2 ;
src1 = imread("zhugeleft.jpg") ;
src2 = imread("zhugeright.jpg") ;
if (!src1.data || !src2.data)
{
cout<<"读取图片失败!\n" ;
return ;
}
SurfFeatureDetector dector(400) ;
vector<KeyPoint> keypoints_1 , keypoints_2 ; //保存特征点向量
dector.detect(src1 , keypoints_1) ; //检测SURF特征
dector.detect(src2 , keypoints_2) ;
//计算描述子
SurfDescriptorExtractor extractor ;
Mat descriptors_1 , descriptors_2 ;
extractor.compute(src1 , keypoints_1 , descriptors_1) ;
extractor.compute(src2 , keypoints_2 , descriptors_2) ;
//Flan特征匹配算法
FlannBasedMatcher matcher ;
vector<DMatch> matches ;
matcher.match(descriptors_1 , descriptors_2 , matches) ;
cout<<"快速最近邻搜索匹配获得的匹配点数为:"<<matches.size()<<endl ;
double max_dist = 0 ; double min_dist = 100 ;
//计算关键点之间最大最小欧式距离
for (int i = 0 ; i < descriptors_1.rows ; i++)
{
double dist = matches[i].distance ;
if (dist < min_dist)
{
min_dist = dist ;
}
if (dist > max_dist)
{
max_dist = dist ;
}
}
cout<<"关键点之间欧式距离最小最大值分别为:max_dist = "<<max_dist<<"\tmin_dist = "<<min_dist<<endl ;
//选择欧式距离小于2倍最小距离的匹配作为优良匹配
vector<DMatch> good_matches ;
for (int i = 0 ; i < descriptors_1.rows ; i++)
{
if (matches[i].distance < 2 * min_dist)
{
good_matches.push_back(matches[i]) ;
}
}
Mat m_matches ;
m_matches.create(src1.rows , 2 * src1.cols , src1.type()) ;
Mat imageROI ;
imageROI = m_matches(Rect(0 , 0 , src1.cols , src1.rows)) ;
Mat imageROI2 ;
imageROI2 = m_matches(Rect(src1.cols , 0 , src2.cols , src2.rows)) ;
addWeighted(imageROI , 0.0 , src1 , 1.0 , 0 , imageROI) ;
addWeighted(imageROI2 , 0.0 , src2 , 1.0 , 0 , imageROI2) ;
cout<<"输出匹配点坐标:\n" ;
for (int i = 0 ; i < good_matches.size() ; ++i)
{
int index1 = good_matches[i].queryIdx ;
int index2 = good_matches[i].trainIdx ;
circle(m_matches , keypoints_1[index1].pt , 10 , Scalar(0 , 0 , 255) , 5) ;
circle(m_matches , Point(src1.cols + keypoints_2[index2].pt.x , keypoints_2[index2].pt.y) , 10 , Scalar(0 , 0 , 255) , 5) ;
line(m_matches , keypoints_1[index1].pt , Point(keypoints_2[index2].pt.x + src1.cols , keypoints_2[index2].pt.y) , Scalar::all(-1) , 10 , 8) ;
double coefficent = Calcoefficient(src1 , keypoints_1[index1].pt , src2 , keypoints_2[index2].pt) ;
cout<<keypoints_1[index1].pt<<"\t"<<keypoints_2[index2].pt<<"\t匹配系数为:"<<coefficent ;
cout<<endl ;
}
int good_count = good_matches.size() ;
cout<<"优良匹配数量为:"<<good_count<<endl ;
namedWindow("m_matches" , 0) ;
imshow("m_matches" , m_matches) ;
waitKey(0) ;程序运行结果;
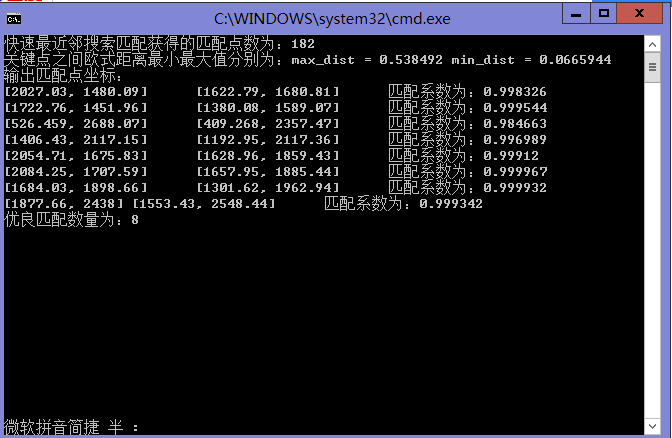

结果是不是很好啊!















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









