






Apache Kafka 可视化工具调研
背景
随着流式计算和消息解耦的需求越来越多,消息队列(Apache Kafka)也成为了中台架构中的一个重要组件,Apache Kafka 的可观察性已经是一个很迫切的需求。基于我们当前的技术栈,和现有的解决方案,对 Apache Kafka 的可观察性需求描述如下:
- Kafka 官方 cli 工具命令参数较长,命令有限,都是基于后台,使用起来不方便
- 需要可以查询 topic 列表,以及 topic 内部的数据
- 需要可以通过容器进行云原生部署
- 最好可以支持 SSO 和基于角色的权限控制(下文简称 RBAC)
- 已经通过 Prometheus + Grafana 实现了运维侧的监控和告警
方案
针对以上的问题,社区也提供了很多优秀的方案和工具:
AKHQ 是一款轻量级的 Apache Kafka 观察工具,具有 topic 消息管理、查询,支持多种鉴权方式。
- UI for Apache Kafka(Kafka UI)[GITHUB] Star:3.2K
Kafka UI 作为 Provectus NextGen 数据平台的一部分,是一款轻量级的 Apache Kafka 观察工具。支持 KSQL DB 作为插件集成,同时支持通过多种 Connector 连接不同的数据源。
- Kafka Eagle(EFAK)[GITHUB] Star:2.5K
EFAK 是一款功能丰富的开源 Apache Kafka 观察工具,结合了运维管理、指标统计以及可观察性等功能,告警模块集成了 IM。自带 KSQL 能力,可以让开发者像操作表数据一样操作 DataSream。
- kafka-console-ui [GITHUB] Star:98
Kafka-console-ui 是一款轻量级比较小众的工具。
- Kafka Manager(CMAK)[GITHUB] Star:10.9K
Yahoo 推出的老牌开源 Apache Kafka 管理工具,已经很久没有维护了。
滴滴开源的 Apache Kafka 管理平台,比较重度,且和滴滴云有较强的绑定。
kafka tools 是 一个基于 Java GUI 开发的闭源工具,只适合在 windows 上使用。
功能对比
经过筛选,去掉了较为重度的 LogiKM 和闭源的 kafka tools 后,对剩下的 5 款工具进行功能对比。
| AKHQ | UI for Apache Kafka | Kafka Eagle(EFAK) | kafka-console-ui | |
| 多集群管理 | 支持 | 支持 | 支持 | 支持 |
| topic 和消息查看 | 支持 | 支持 | 支持 | 不支持 |
| SSO 接入 | LDAP | OAuth 2.0/LDAP | 不支持 | 不支持 |
| RBAC | 支持 | 不支持* | 支持(内部) | 不支持 |
| 官方容器镜像 | 支持 | 支持 | 自行构建镜像 | 不支持 |
| 开发语言 | Java + JavaScript | Java + TypeScript | Java | Java + vue |
| 外部数据库 | 无 | 无 | mysql5 以上 | 无 |
| 连接方式 | broker | broker/zookeeper | zookeeper | broker |
| 文档 | 少 | 少 | 丰富 | 少 |
注:UI for Apache Kafka 有支持 RBAC 的计划,在社区的路线图里,但当前版本还不够成熟
基于以上表格信息,我们排除掉有较多 feature 不支持的 kafka-console-ui。接下来,将对 AKHQ 、Kafka UI 以及 EFAK 这三款工具进行横向对比。
数据可观察性
-
AKHQ
-
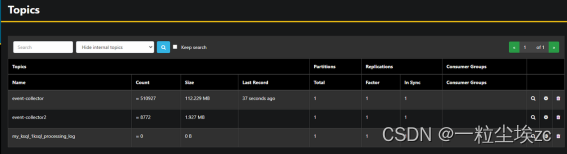
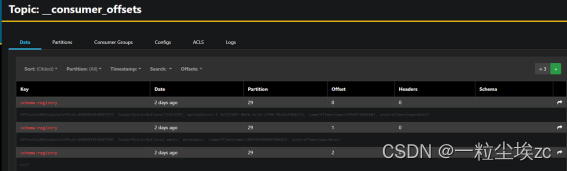
支持通过 UI 显示 topic 列表和 topic 内部的消息
-
支持时间、offset 进行范围数据过滤,支持简单表达式过滤,支持关键字模糊搜索,支持分区过滤
-
支持 live tail(实时读取)模式
-
AKHQ 截图
-
-
Kafka UI
-
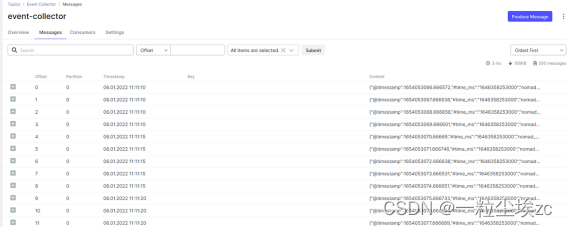
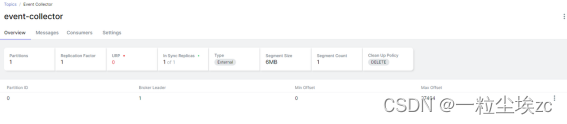
支持通过 UI 显示 topic 列表和 topic 内部的消息
-
支持时间、offset 进行范围数据过滤,支持简单表达式过滤,支持关键字模糊搜索
-
支持 live tail(实时读取)模式
-
Kafka UI 截图
-

-
EFAK
-
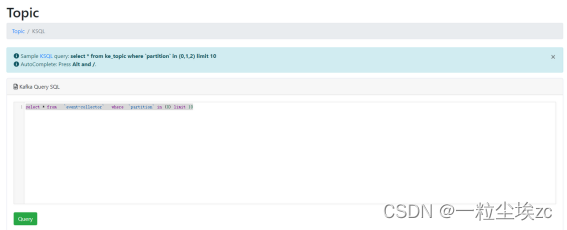
支持通过 UI 显示 topic 列表,但只能通过 SQL 查看 topic 内部的消息
-
使用 SQL 方式实现 topic 中的数据进行可视化查询,几乎支持 SQL 的所有语法,包括精准、模糊、范围查询,指定 topic 分区查询,支持查看历史查询的结果
-
不支持 live tail(实时读取)模式
-
EFAK 截图
-
总结
在数据可观察性上三款工具提供的能力都基本满足使用,Kafka UI 和 AKHQ 的功能几乎是一样,UI 也更直观,EFAK 通过 KSQL 的方式操作相对来说繁琐,但也提供了更多可能性。
运维 & 部署
-
AKHQ
-
官方有提供镜像,版本更新频率正常
-
支持 LDAP 方式,有原生登录界面
-
支持 RBAC 功能,通过配置文件管理用户权限,可以实现 topic 级别的控制
-
不需要依赖外部组件
-
-
Kafka UI
-
官方有提供镜像,版本更新频率正常
-
支持 LDAP 方式,但是没有原生登录界面,关闭浏览器需要重新登录
-
支持 OAuth2 方式,当前世游 SSO 系统不符合指定标准,无法对接
-
暂不支持 RBAC 功能,只支持 readonly 开关,作者计划在近几个月发布 RBAC 功能 [ISSUE]
-
不需要依赖外部组件
-
-
EFAK
- 官方没有提供镜像,需要自己构建镜像,升级版本需要重新构建
-
不支持 SSO 接入
-
仅支持基于内部系统的 RBAC
-
需要依赖 mysql5.7+,存储相关元数据
总结
AKHQ 功能最全面,最符合我们对 Apache Kafka 观察工具的想象。Kafka UI 还在持续的发展和迭代中,仍不够成熟,后续可以继续关注。EFAK 不支持 SSO 接入,还需要外部依赖,相对来说比较复杂。
Kafka 特性
-
AKHQ
-
只支持配置 broker 地址
-
-
Kafka UI
-
同时支持配置 broker 和 zookeeper 地址
-
-
EFAK
-
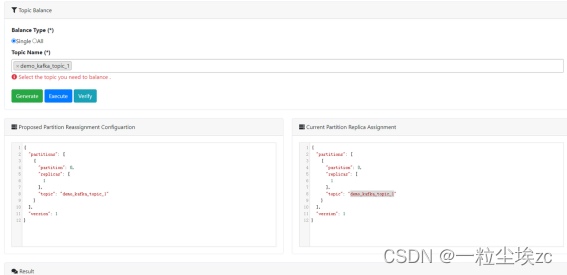
只支持配置 zookeeper 地址
-
我们知道当前 Kafka 无法支持数据倾斜之后进行自平衡,所以 EFAK 提供了手动方式的数据迁移能力
-
EFAK 截图
-
总结
Apache Kafka 3.1+ 引入了 Kafka Raft。Raft 是一种共识协议,它的引入是为了消除 Kafka 对 ZooKeeper 的依赖。如果后续 Kafka 升级到了 3.x 版本,EFAK 将无法对接。
结论
通过横向对比 Apache Kafka 观察工具,我们得出以下结论:
- AKHQ 是当前最符合要求的组件,建议使用
- Kafka UI 的发展值得关注
- EFAK 功能丰富,但是无法满足我们的需求(部署、SSO接入、Kafka 连接)

















 944
944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









