







大家读完觉得有帮助记得关注和点赞!!!
目录
1.2 解决方案:OpenStack Provider Network 模型
3.1.2 解决方案:扩展现有 SDN 方案,接入 Mesos/K8S
4.2 宿主机内部网络通信(Host Networking)
4.3 跨宿主机网络通信(Multi-Host Networking)
本文介绍云计算时代以来携程在私有云和公有云上的几代网络解决方案。希望这些内容可以 给业内同行,尤其是那些设计和维护同等规模网络的团队提供一些参考。
本文将首先简单介绍携程的云平台,然后依次介绍我们经历过的几代网络模型:从传统的基 于 VLAN 的二层网络,到基于 SDN 的大二层网络,再到容器和混合云场景下的网络,最后是 cloud native 时代的一些探索。
0 携程云平台简介
携程 Cloud 团队成立于 2013 年左右,最初是基于 OpenStack 做私有云,后来又开发了自 己的 baremetal(BM)系统,集成到 OpenStack,最近几年又陆续落地了 Mesos 和 K8S 平 台,并接入了公有云。目前,我们已经将所有 cloud 服务打造成一个 CDOS — 携程数据中心操作系统的混合云平台,统一管理我们在私有云和公有云上的计算、网络 、存储资源。

Fig 1. Ctrip Datacenter Operation System (CDOS)
在私有云上,我们有虚拟机、应用物理机和容器。在公有云上,接入了亚马逊、腾讯云、 UCloud 等供应商,给应用部门提供虚拟机和容器。所有这些资源都通过 CDOS API 统一管 理。
网络演进时间线
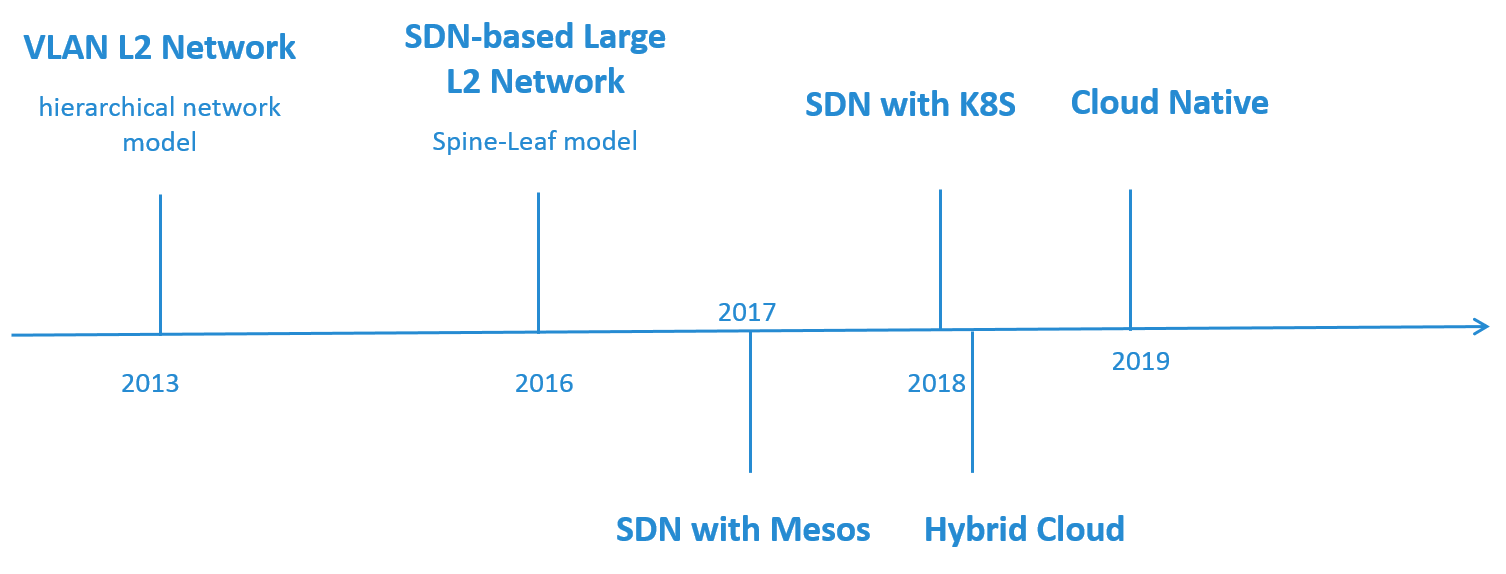
Fig 2. Timeline of the Network Architecture Evolution
图 2 我们网络架构演进的大致时间线。
最开始做 OpenStack 时采用的是简单的 VLAN 二层网络,硬件网络基于传统的三层网络模 型。
随着网络规模的扩大,这种架构的不足逐渐显现出来。因此,在 2016 年自研了基于 SDN 的大二层网络来解决面临的问题,其中硬件架构换成了 Spine-Leaf。
2017 年,我们开始在私有云和公有云上落地容器平台。在私有云上,对 SDN 方案进行了扩 展和优化,接入了 Mesos 和 K8S 平台,单套网络方案同时管理了虚拟机、应用物理机和容 器网络。公有云上也设计了自己的网络方案,打通了混合云。
最后是 2019 年,针对 Cloud Native 时代面临的一些新挑战,我们在调研一些新方案。
1 基于 VLAN 的二层网络
2013 年我们开始基于 OpenStack 做私有云,给公司的业务部门提供虚拟机和应用物理机资 源。
1.1 需求
网络方面的需求有:
首先,性能不能太差,衡量指标包括 instance-to-instance 延迟、吞吐量等等。
第二,二层要有必要的隔离,防止二层网络的一些常见问题,例如广播泛洪。
第三,实例的 IP 要可路由,这点比较重要。这也决定了在宿主机内部不能使用隧道 技术。
第四,安全的优先级可以稍微放低一点。如果可以通过牺牲一点安全性带来比较大的性能提 升,在当时也是可以接受的。而且在私有云上,还是有其他方式可以弥补安全性的不足。
1.2 解决方案:OpenStack Provider Network 模型
经过一些调研,我们最后选择了 OpenStack provider network 模型 [1]。
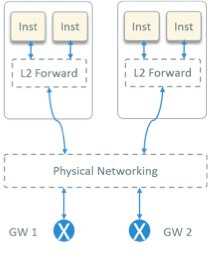
Fig 3. OpenStack Provider Network Model
如图 3 所示。宿主机内部走二层软交换,可以是 OVS、Linux Bridge、或者特定厂商的方案 ;宿主机外面,二层走交换,三层走路由,没有 overlay 封装。
这种方案有如下特点:
首先,租户网络的网关要配置在硬件设备上,因此需要硬件网络的配合,而并不是一个纯软 件的方案;
第二,实例的 IP 是可路由的,不需要走隧道;
第三,和纯软件的方案相比,性能更好,因为不需要隧道的封装和解封装,而且跨网段的路 由都是由硬件交换机完成的。
方案的一些其他方面:
- 二层使用 VLAN 做隔离
- ML2 选用 OVS,相应的 L2 agent 就是 neutron ovs agent
- 因为网关在硬件交换机上,所以我们不需要 L3 agent(OpenStack 软件实现的虚拟路由器)来做路由转发
- 不用 DHCP
- 没有 floating ip 的需求
- 出于性能考虑,我们去掉了 security group
1.3 硬件网络拓扑
图 4 是我们的物理网络拓扑,最下面是服务器机柜,上面的网络是典型的接入-汇聚-核 心三层架构。
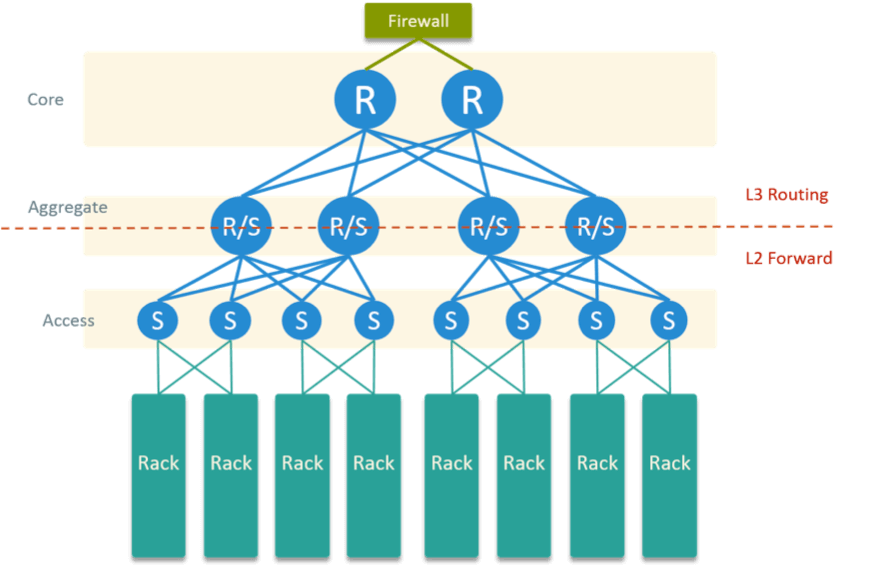
Fig 4. Physical Network Topology in the Datacenter
特点:
- 每个服务器两个物理网卡,直连到两个置顶交换机做物理高可用
- 汇聚层和接入层走二层交换,和核心层走三层路由
- 所有 OpenStack 网关配置在核心层路由器
- 防火墙和核心路由器直连,做一些安全策略
1.4 宿主机内部网络拓扑
再来看宿主机内部的网络拓扑。图 5 是一个计算节点内部的拓扑。
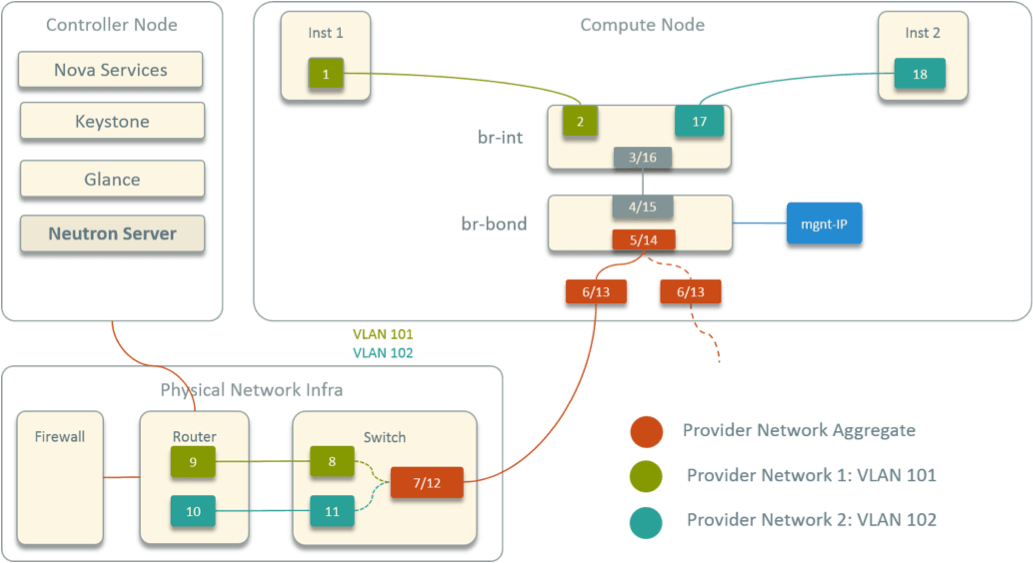
Fig 5. Designed Virtual Network Topology within A Compute Node
特点:
- 首先,在宿主机内有两个 OVS bridge:
br-int和br-bond,两个 bridge 直连 - 有两个物理网卡,通过 OVS 做 bond。宿主机的 IP 配置在
br-bond上作为管理 IP - 所有实例连接到
br-int
图中的两个实例属于不同网段,这些标数字的(虚拟和物理)设备连接起来,就是两个跨 网段的实例之间通信的路径:inst1 出来的包经 br-int 到达 br-bond,再经物理 网卡出宿主机,然后到达交换机,最后到达路由器(网关);路由转发之后,包再经类似路 径回到 inst2,总共是 18 跳。
作为对比,图 6 是原生的 OpenStack provider network 模型。
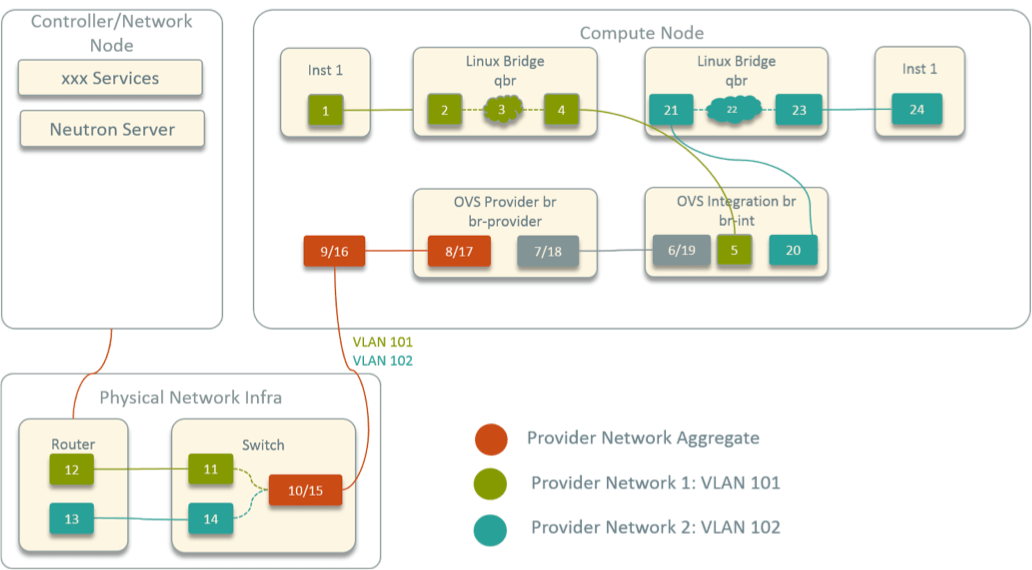
Fig 6. Virtual Network Topology within A Compute Node in Legacy OpenStack
这里最大的区别就是每个实例和 br-int 之间都多出一个 Linux bridge。这是因为原生的 OpenStack 支持通过 security group 对实例做安全策略,而 security group 底层是基于 iptables 的。OVS port 不支持 iptables 规则,而 Linux bridge port 支持,因此 OpenStack 在每个实例和 OVS 之间都插入了一个 Linux Bridge。在这种情况下,inst1 -> inst2 总共是 24 跳,比刚才多出 6 跳。
1.5 小结
最后总结一下我们第一代网络方案。
优点
首先,我们去掉了一些不用的 OpenStack 组件,例如 L3 agent、HDCP agent, Neutron meta agent 等等,简化了系统架构。对于一个刚开始做 OpenStack、经验还不是很丰 富的团队来说,开发和运维成本比较低。
第二,上面已经看到,我们去掉了 Linux Bridge,简化了宿主机内部的网络拓扑,这使得 转发路径更短,实例的网络延迟更低。
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









