







4.6 神经网络模型的计算过程
对于神经网络模型的计算过程,主要分为两个部分:
- 正向传播算法
- 反向传播算法
4.6.1 正向传播
概念: 正向传播就是基于训练好的网络模型,输入目标通过权重、偏置和激活函数计算出隐层,隐层通过下一级的权重、偏置和激活函数得到下一个隐层,经过逐层迭代,将输入的特征向量从低级特征逐步提取为抽象特征,最终输出目标结果。
正向传播的过程: 权重矩阵的转置乘以输入向量,再通过非线性激活函数得到输出。
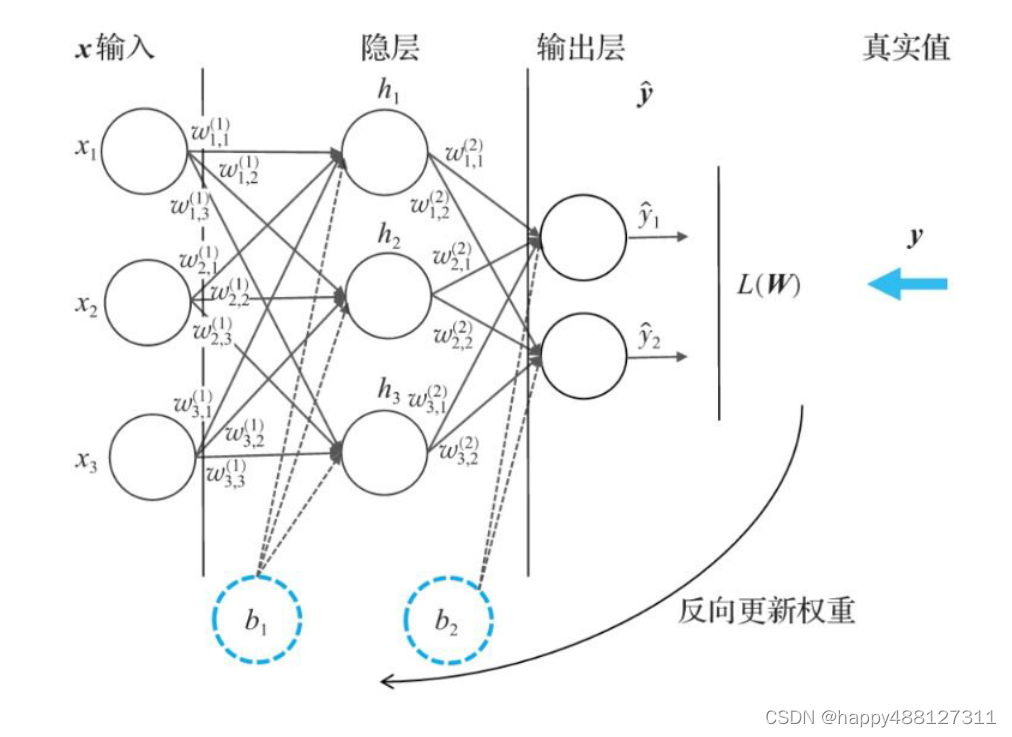
上图中的神经网络的输入为3个神经元, 记为x=[x1;x2;x3];隐层包含3个神经元,记为h=[h1; h2; h3];输出层包含2个输出神经 元,记为y1,y2。输入和隐层之间的连接对应的偏置为b1,权重矩阵为![w(1)=[]](https://i-blog.csdnimg.cn/blog_migrate/a1d311aee595a02c70a6a46284384237.png)
隐层和输出层之间的连接对应的偏置为b2,权重矩阵为
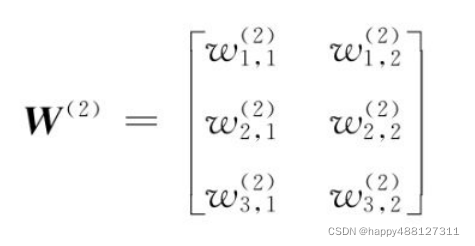
假设该神经网络采用sigmoid函数作为激活函数,
输入到隐层的正向传播过程为:
- 权重矩阵w(1)的转置乘以输入向量x,再加上偏置b1,得到中间变量
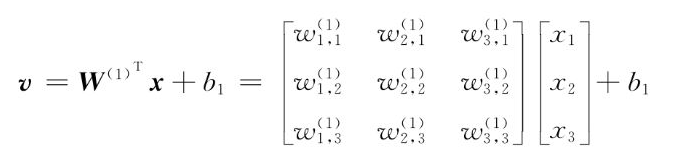
- 经过激活函数sigmoid后,得到隐层的输出
隐层到输出层的正向传播过程与上述过程类似。
4.6.2 反向传播
4.6.2.1 概念:
反向传播(英语:Back propagation,缩写为BP)是“误差反向传播”的简称,其实和线性回归的思想是一样的,是一种与最优化方法(如梯度下降法)结合使用的,逐渐调节参数,用来训练人工神经网络的常见方法。
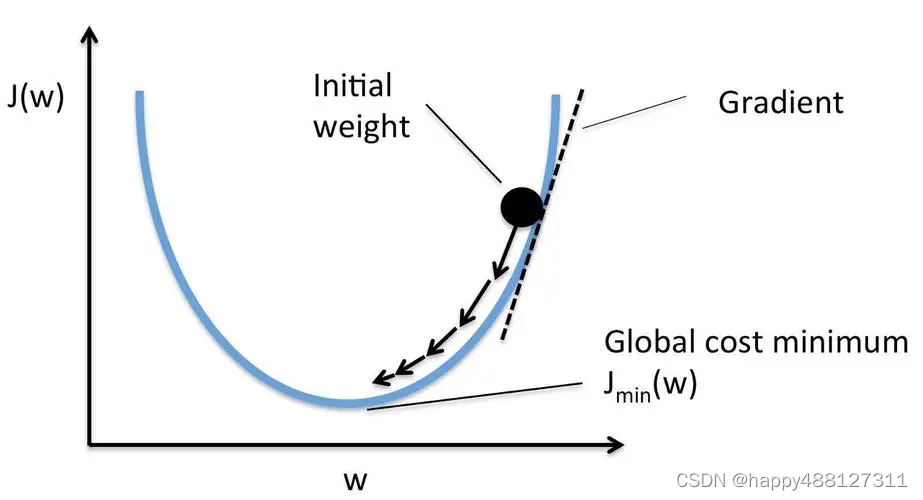
对于反向传播来说,首先要根据神经网络计算出的值和期望值计算损失函数的值,然后采用梯度下降法,通过链式求导法则计算出损失函数对每个权重或偏置的偏导,最后进行参数更新。
该方法对网络中所有权重计算损失函数的梯度。 这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数,使得输出靠近预期结果。(误差的反向传播)
反向传播就是要将神经网络的输出误差,一级一级地传播到神经网络的输入。在该过程中,需要计算每一个w(权重)对总的损失函数的影响, 即损失函数对每个w的偏导。根据w对误差的影响,再乘以步长,就可以更新整个神经网络的权重。 当一次反向传播完成之后,网络的参数模型就可以得到更新。更新一轮之后,接着输入下一个样本, 算出误差后又可以更新一轮,再输入一个样本,又来更新一轮,通过不断地输入新的样本迭代地更新模型参数,就可以缩小计算值与真实值之间的误差,最终完成神经网络的训练。
特点:
正向传播需要的内存较大,因为需要按输入层到输出层的顺序依次计算,并将计算所得中间变量进行存储,这是导致神经网络需要较大内存的原因。
反方向传播从输出层到输入层顺序依次计算,利用了链式法则。所求梯度与中间变量当前值有关,因此需要保存中间变量及其梯度的值。
4.6.3 优化函数
4.6.3.1 优化函数的作用
在利用损失函数(Loss Function)计算出模型的损失值之后,接下来需要利用损失值进行模型参数的优化。在实践操作最常用到的是一阶优化函数。包括GD,SGD,BGD,Adam等。一阶优化函数在优化过程中求解的是参数的一阶导数,这些一阶导数的值就是模型中参数的微调值。
4.6.3.2 几种优化函数
1.BGD 批量梯度下降
所谓的梯度下降方法是无约束条件中最常用的方法。假设f(x)是具有一阶连续偏导的函数,现在的目标是要求取最小的f(x) : min f(x)
核心思想:负梯度方向是使函数值下降最快的方向,在迭代的每一步根据负梯度的方向更新x的值,从而求得最小的f(x)。因此我们的目标就转变为求取f(x)的梯度。
当f(x)是凸函数的时候,用梯度下降的方法取得的最小值是全局最优解,但是在计算的时候,需要在每一步(xk处)计算梯度,它每更新一个参数都要遍历完整的训练集,不仅很慢,还会造成训练集太大无法加载到内存的问题,此外该方法还不支持在线更新模型。其代码表示如下:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
优点:
- 一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
- 由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得到全局最优。
缺点:
- 当样本数目 m 很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。
- 从迭代的次数上来看,BGD迭代的次数相对较少。
2.SGD随机梯度下降
随机梯度下降算法的梯度是根据随机选取的训练集样本来决定的,其每次对θ的更新,都是针对单个样本数据,并没有遍历完整的参数。当样本数据很大时,可能到迭代完成,也只不过遍历了样本中的一小部分。因此,其速度较快,但是其每次的优化方向不一定是全局最优的,但最终的结果是在全局最优解的附近。
需要:
- 学习速率 ϵ,
- 初始参数 θ
每步迭代过程:
- 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
- 计算梯度和误差并更新参数
在pytorch中的使用:
包:torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False, *, maximize=False)
参数:
-
params (iterable) – 要优化的参数的iterable或定义参数组的dicts
-
lr (float) – 学习率
-
momentum (float, optional) –动量因子(默认值:0)
-
weight_decay (float, optional)–权重衰减(L2惩罚)(默认值:0)
-
dampening (float, optional))–动量阻尼(默认值:0)
-
nesterov (bool, optional)–启用内斯特罗夫动量(默认值:False)
-
maximize (bool, optional)–根据目标最大化参数,而不是最小化(默认值:False)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
for input, target in dataset:
# 梯度清零
optimizer.zero_grad()
# 反向传播,model是一个神经网络
loss_fn(model(input), target).backward()
# 执行单个优化步骤
optimizer.step()
优点:
- 训练速度快,避免了批量梯度更新过程中的计算冗余问题
- 对于很大的数据集,也能够以较快的速度收敛
缺点:
- 由于是抽取,因此不可避免的,得到的梯度肯定有误差
- 学习速率需要逐渐减小,否则模型无法收敛
- 因为误差,所以每一次迭代的梯度受抽样的影响比较大,也就是说梯度含有比较大的噪声,不能很好的反映真实梯度
- 并且SGD有较高的方差,其波动较大
虽然BGD可以让参数达到全局最低点并且停止,而SGD可能会让参数达到局部最优,但是仍然会波动,甚至在训练过程中让参数会朝一个更好的更有潜力的方向更新。但是众多的实验表明,当我们逐渐减少学习速率时,SGD和BGD会达到一样的全局最优点。
注:本博客内容来教材和自网络整理,仅作为学习笔记记录,不用做其他用途。
参考博客
https://blog.csdn.net/qq_21460525/article/details/70146665?spm=1001.2014.3001.5506
https://blog.csdn.net/shanglianlm/article/details/85019633
https://www.cnblogs.com/lliuye/p/9451903.html



















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











