



一、xpath
简介:XPath即XML路径语言(全称Xml Path Language),是一种用于确定XML文档中部分节点位置的语言,它起初只支持搜索XML文档更新后也支持搜索HTML文档,更新后也支持搜索HTML文档。
而安卓系统的App界面也是用的XML语言开发的。
1. xml结构如下所示
2. 用一张示意图来描述XML文档、XML节点树和路径表达式的关系
从左到右依次为XML文档、XML节点树和路径表达式,其中路径表达式为 "/bookstore/book/price",它对应的路径为图中加粗的线条,用于选取节点<price>对应的文本39.95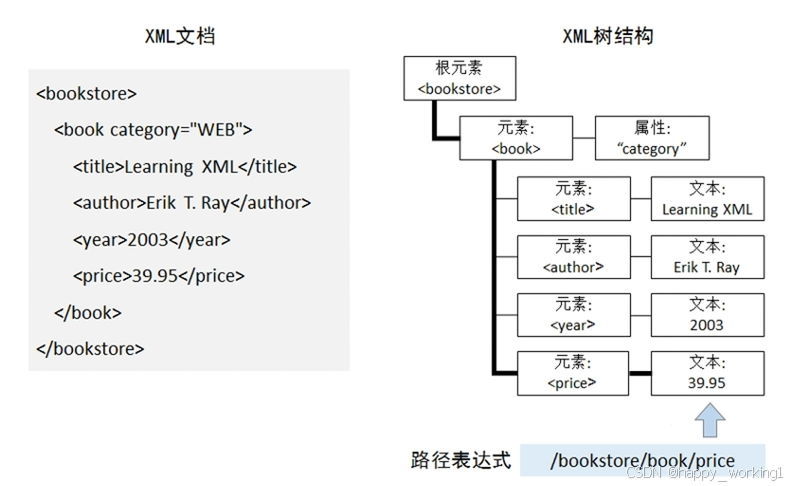
3. xpath语法
下面将从 选取节点、谓语、选取未知节点、选取若干路径 这4个方面介绍其语法。
①选取节点
选取节点是最基础的操作,节点所在的路径既可以是从根节点开始的,也可以从任意位置开始的。

以下面的xml文档为例,进行演示
<?xml version="1.0"encoding="lSO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
xpath语法
bookstore # 选取bookstore的所有子节点
/bookstore # 选取根节点bookstore
bookstore/book # 从根节点bookstore开始向下选取名为book的所有子节点
//book # 从任意节点开始,选取名为book的所有子节点
bookstore//book # 从bookstore的后代节点中选取名为book的所有子节点
//@lang # 选取所有名为lang的属性节点
②谓语
谓语是为路径表达式附加的条件,主要用于筛选当前被处理的节点集,选取出满足某个特定的节点,或者包含了指定属性或基本值的节点。谓语会嵌入到方括号中,位于要补充说明的节点的后面。
公式为——> 节点[谓语1]
方括号中的谓语可以是整数、属性、函数,也可以是整数、属性、函数与运算符组合的表达式。如果谓语是整数(从1开始),则这个数值将作为位置,用于从节点集中选取与该位置对应的节点;如果为属性,则会从节点集中选取包含该属性的节点;如果为函数则会将该函数的返回值作为条件,从节点集中选取满足条件的节点。
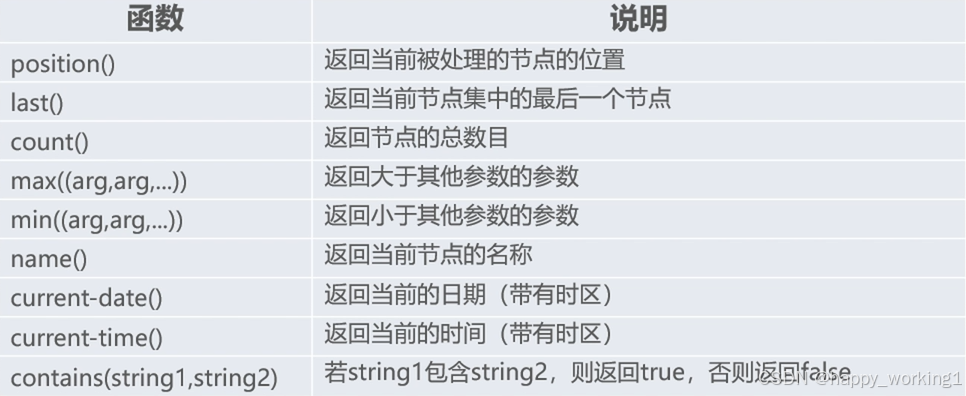
其中,常见的xpath函数如下
还是以前面的xml文件为例
/bookstore/book[1] # 选取属于bookstore子节点的第1个book节点
/bookstore/book[last()] # 选取属于bookstore子节点的最后一个book节点
/bookstore/book[last()-1] #选取属于bookstore子节点的倒数第2个book节点
/bookstore/book[position()<3] # 选取属于bookstore子节点的前两个book节点
//title[@lang] # 选取所有的属性名称为lang的title节点
//title[@lang='eng'] # 选取所有的属性名称为lang且属性值为eng的title节点
# 选取子节点price的值大于35.00,且父节点为bookstore的所有book节点
/bookstore/book[price>35.00]
# 选取属于book的所有子节点title,且节点book的子节点price的值必须大于35.00/bookstore/book[price>35.00]/title
③选取未知节点
XPath中提供了选取未知节点的通配符和函数。

还是以前面的xml文件为例
/bookstore/* # 选取属于bookstore的所有子节点
//* # 选取文档中的所有节点
//title[@*] # 选取所有带有属性的节点title
④选取若干路径
在XPath中,我们可以使用 “|” 运算符连接多个路径表达式,以根据多个路径选取对应的节点。以前面的bookstore.xml为例,演示“|”的用法。
//book/title|//book/price #选取属于book的子节点title和price
//title|//price # 选取所有的title和price节点
# 选取属于/bookstore/book/的所有title节点,以及文档中所有的节点price
/bookstore/book/title|//price
二、lxml库
简介:它提供了对XML和HTML文档的解析和操作功能。它是Python中处理XML和HTML的强大工具,因为它结合了libxml2和libxslt库,这两个库是C语言编写的,因此lxml在性能上非常出色,尤其是在处理大型文件时。
安装:终端执行 pip install lxml 就好
1. etree模块
在lxml库中,大多数有关解析的功能都封装到 etree模块中,etree模块中包含了两个比较重要的类,分别是ElementTree类和Element类。
①ElementTree类
ElementTree类的对象可以理解为一个HTML或XML文档的节点树。为方便开发者将HTML或XML文档转换为ElementTree类的对象,etree模块中提供了一个parse()函数。
# 表达式
parse(source, parser=None, base_url=None)
"""
source:必选参数,表示待解析的内容,该参数共支持4种类型的取值,分别是打开的文件对象(确保以二进制模式打开)、类似文件的对象、字符串形式的文件名称、字符串形式的URL。
parser:可选参数,表示解析器。若未指定解析器,则会使用默认的解析器;若希望指定其他的解析器,则可以通过help(etree.XMLParser)查看lxml支持的解析器base
ur:可选参数,表示基础URL
"""
以之前bookstore.xml为例,演示如何根据该文档使用parse()函数创建ElementTree类的对象。
from lxml import etree
# 从bookstore.xml文件中解析,返回ElementTree类的对象
ele_tree= etree.parse(r'bookstore.xml')
print(type(ele_tree))
运行结果如下
<class 'lxml.etree._ElementTree'>
etree模块中还提供了3个函数:fromstring()、XML()和HTML(),这3个函数也可以解析HTML或XML文档或片段,只不过在解析成功后返回根节点或者解析器目标返回的结果。其中,fromstring0)函数和XML()函数的功能相同,都可以从字符串常量中解析XML文档或片段;HTML()函数用于从字符串常量中解析HTML文档或片段,并能够自动补全文档或片段中缺少的<html>和<body>元素。
①Element类
Element类的对象可以理解为XML或HTML文档的节点,它与Python中的列表非常相似,可以使用诸如len()、append()、remove()等方法修改节点,也可以使用索引、切片获取节点集中的子节点。使用索引或切片获取root node对象中的子节点,具体代码如下所示:
print(root_node[:]) # 获取所有的子节点
print(root_node[0]) # 获取第1个子节点
print(root_node[1]) # 获取第2个子节点
运行结果如下:
[<Element book at 0x34cae00>,<Element book at 0x34cae80>]
<Element book at 0x34cae00>
<Element book at 0x34cae00>
Element类还提供了一些获取节点的属性,关于这些属性及其说明如下表。

2. ElementTree类或Element类的查找方法
ElementTree类或Element类中提供了3个常用的査找方法,分别是find()、findall()、xpath(),3个方法都会从节点树的根节点开始查找目标节点
find()方法:从节点树的某个节点开始查找,返回匹配到的第一个子节点。
findall()方法:从节点树的某个节点开始查找,以列表的形式返回匹配到的所有子节点。
xpath()方法:从节点树的根节点或某个节点开始查找,以列表的形式返回匹配到的所有子节点。
以root_node对象为例,分别使用以上3个方法的查找第一个price节点的文本
res1 = root node.find('.//price').text
print(res1)
res2 = root node.findall('.//price')[0].text
print(res2)
res3 = root node.xpath('.//price')[0].text
print(res3)
差不多了解学习够用了,实际使用到的时候再查就可以了

















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









