






一、爬取微信朋友圈的多种方法总结
1.用itchat包实现PC端网页版微信登录爬取数据
->微信已经关闭网页版,方法无法使用
2.用pywinauto库在PC端微信爬取数据
-> 查看github发现Pywinauto库在19年之后没有再维护,很多模块已经不兼容win11,舍弃该方法
3.调用api
-> 这种最方便但是微信官方并不提供朋友圈数据接口,最后得到的数据只有通讯录内容
4.用Appnium自动化模拟操作爬数据
-> Appnium不是一个库,是一套软件,安装需要java环境等,还有配置,非常麻烦
5.用uiautomator2库自动化模拟人工操作
-> uiautomator2比Appnium简单易上手,但是目前相关代码较少这里我们采取用uiautomator2库的方法爬取朋友圈数据。
二、准备操作
1. python3
2. pycharm或其他ide
3. 安卓手机或模拟器
4. uiautomator2库的使用方式(关于u2库的快速入门使用可以看我的上一篇博客python做手机端app自动化测试-CSDN博客)
5. 数据库MySQL -> 用于朋友圈数据的导入,当然也可以选择导入到excel(关于MySQL的快速入门使用可以看MYSQL数据库操作-CSDN博客)
6. xpath语法和lxml库的使用(关于其快速入门可以看xpath和lxml库的使用-CSDN博客)
三、自动化流程
1. 获取微信朋友圈的必要控件信息
连接好手机之后打开weditor,将手机中微信app的包名、‘发现’控件、‘朋友圈’控件信息记录下来。
我的控件信息如下(仅参考):
# 微信包名
'com.tencent.mm'
# ‘发现’控件
resourceId="com.tencent.mm:id/icon_tv", text="发现"
# ‘朋友圈’控件
resourceId="com.tencent.mm:id/m38"
以及朋友圈页面个体项目、网名、文章内容、日期信息也记录下来。
我的控件信息如下(仅参考):
# 朋友圈页面个体
resourceId="com.tencent.mm:id/n9a"
# 网名
resourceId="com.tencent.mm:id/kbq"
# 文章内容
resourceId="com.tencent.mm:id/cut"
# 日期
resourceId="com.tencent.mm:id/n93"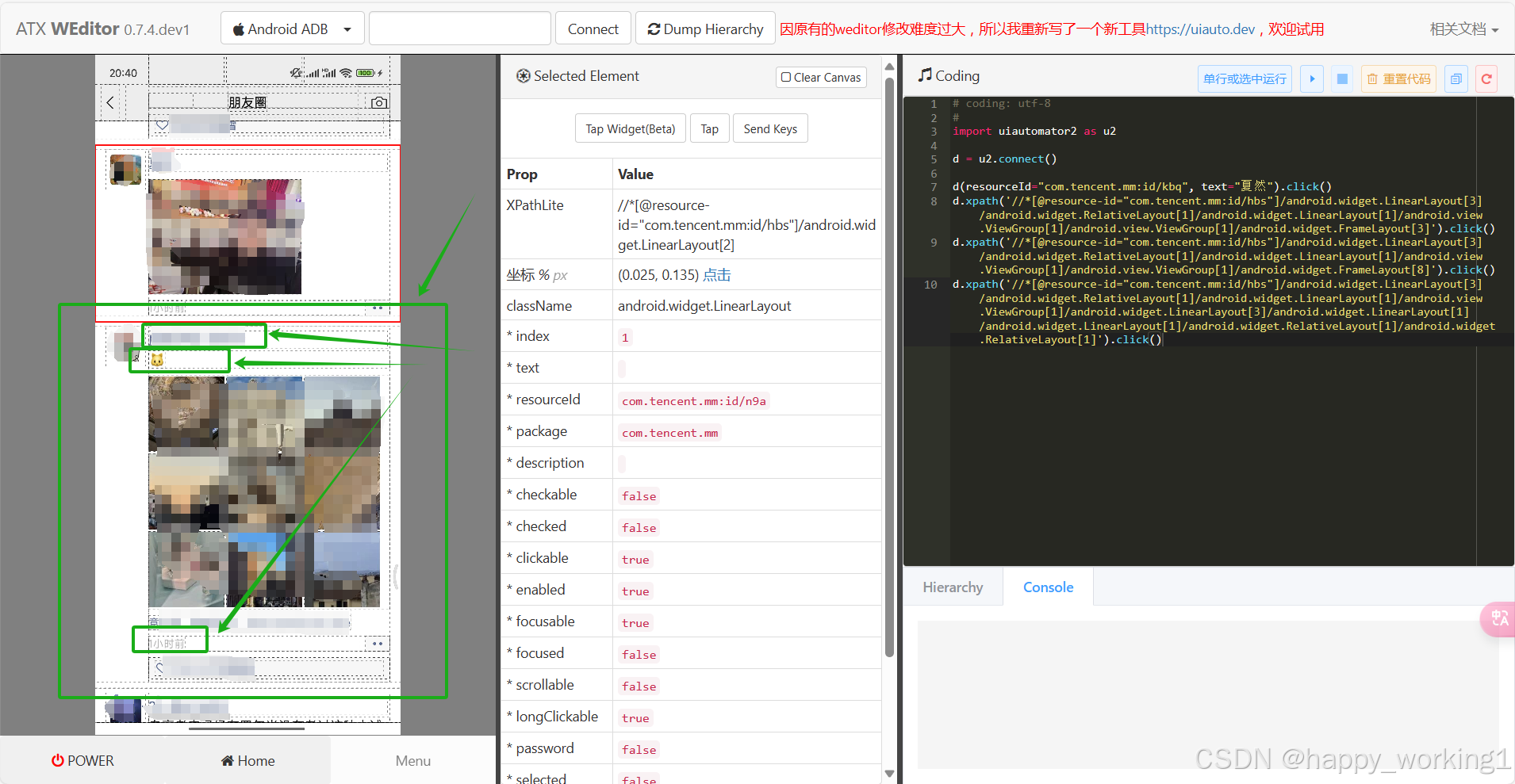
这些数据会在u2库的调用时用到
2. 编写程序
① 首先,用u2库建立好手机与电脑的通信,设备id通过adb devices获取。
import uiautomator2 as u2
phone_id = input("phone id:")
d = u2.connect(phone_id)
print(d.device_info)② 根据微信app控件信息尝试自动化打开微信朋友圈并刷新
# 打开微信app,等待界面加载完成
sess = d.app_start('com.tencent.mm', wait=True) # start
d(resourceId="com.tencent.mm:id/icon_tv", text="发现").click() # 点击‘发现’控件
d(resourceId="com.tencent.mm:id/m38").click() # 点击‘朋友圈’控件
d(resourceId="com.tencent.mm:id/n9a").exists() # 判断朋友圈界面是否存在
# 刷新朋友圈
if d(resourceId="com.tencent.mm:id/ef").exists():
d.double_click(0.522, 0.066)
d.swipe_ext('down', 3)③ 创建一个抓取朋友圈个体内容的类
# 创建Dxpath类,封装一些操作安卓app的lxl元素的方法
class Dxpath:
# 初始化安卓设备信息
def __init__(self, d):
self.d = d
# 定义一个通过参数返回app界面特定元素的方法
def dxpath(self, arg):
# 捕获当前屏幕的所有UI元素及其属性,并以XML的形式输出
xml_content = self.d.dump_hierarchy()
# 将字符串形式的 XML 数据解析成一个ElementTree对象
root = etree.fromstring(xml_content.encode('utf-8'))
return root.xpath(arg)
# 定义一个通过元素其他参数返回元素文本内容的方法
def dxpath_text(self, t, arg, one=True, time_out=False):
# t为dxpath迭代的对象
# 定义文本参数的xpath格式
args = '{}/@text'.format(arg)
text = []
# 将t对象中所有符合args规则的文本导入到列表中
for txt in t.xpath(args):
text.append(str(txt))
# one/time_out的布尔值是根据所需要的内容来的:网名、数据内容或朋友圈日期
if one:
return text[0]
elif time_out:
return text[2]
else:
return text
# 判断输入的xpath路径下是否有元素
def dxpath_exist(self, t, arg):
element = self.dxpath(arg)
return len(element) > 0④ 进行朋友圈数据内容存储
# 创建一个类用来存储朋友圈的三个属性信息
class Item(object):
name = None # 更:网名
comment = None # 更:数据内容
date = None # 朋友圈日期
data_value = set() # 记录已填入数据
items = [] # 数据汇总⑤ 判断条件循环输出朋友圈数据,将个体项目、网名、文章内容、日期信息的属性写上,滑动操作可以让朋友圈数据爬取的内容不断刷新。
# 创建手机类对象(我是小米所以用的mi作为变量)
mi = Dxpath(d)
# 给予判断的初始布尔值
match = False
# 开始输出
while not match:
# 循环每一个朋友圈个体内容
for t in mi.dxpath('//*[@resource-id="com.tencent.mm:id/n9a"]'):
try:
# 分别找到该个体的网名、数据内容和朋友圈日期
comment = mi.dxpath_text(t, './/*[@resource-id="com.tencent.mm:id/cut"]')
name = mi.dxpath_text(t, './/*[@resource-id="com.tencent.mm:id/kbq"]')
# 用weditor发现date的日期文本数据在text[2]中,所以更改对应布尔值
date = mi.dxpath_text(t, './/*[@resource-id="com.tencent.mm:id/n93"]/', one=False, time_out=True)
# 当日期数据为一天前内容时,停止循环
match = re.search(r"天", date)
# 确保数据不重复并且非朋友圈广告信息
if comment not in data_value and not mi.dxpath_exist(t,'.//*[@resource-id="com.tencent.mm:id/egc"]'): # 不能是广告
print("抓取到{}朋友圈数据:\n{}\n时间为:{}".format(name, comment, date))
item = Item()
item.name = name
item.comment = comment
item.date = date
items.append(item)
data_value.add(comment)
# 输出目前总共收集了多少天数据
print('*' * 25 + str(len(data_value)))
except:
pass
# 滑动
d.swipe(300, 800, 300, 300, 0.1)ok整体框架完成了
四、整体代码与运行结果展示
整体代码如下(当然代码结构比较混乱,功能模块也没有做封装处理,整体实现demo大致如此,大家有兴趣可以做优化和整理)
import uiautomator2 as u2
import time
from lxml import etree
import re
# 创建Dxpath类,封装一些操作安卓app的lxl元素的方法
class Dxpath:
# 初始化安卓设备信息
def __init__(self, d):
self.d = d
# 定义一个通过参数返回app界面特定元素的方法
def dxpath(self, arg):
# 捕获当前屏幕的所有UI元素及其属性,并以XML的形式输出
xml_content = self.d.dump_hierarchy()
# 将字符串形式的 XML 数据解析成一个ElementTree对象
root = etree.fromstring(xml_content.encode('utf-8'))
return root.xpath(arg)
# 定义一个通过元素其他参数返回元素文本内容的方法
def dxpath_text(self, t, arg, one=True, time_out=False):
# t为dxpath迭代的对象
# 定义文本参数的xpath格式
args = '{}/@text'.format(arg)
text = []
# 将t对象中所有符合args规则的文本导入到列表中
for txt in t.xpath(args):
text.append(str(txt))
# one/time_out的布尔值是根据所需要的内容来的:网名、数据内容或朋友圈日期
if one:
return text[0]
elif time_out:
return text[2]
else:
return text
# 判断输入的xpath路径下是否有元素
def dxpath_exist(self, t, arg):
element = self.dxpath(arg)
return len(element) > 0
# 创建一个类用来存储朋友圈的三个属性信息
class Item(object):
name = None # 更:网名
comment = None # 更:数据内容
date = None # 朋友圈日期
data_value = set() # 记录已填入数据
items = [] # 数据汇总
# 正式开始,用u2库进行操作
phone_id = input("phone id:")
d = u2.connect(phone_id)
print(d.device_info)
mi = Dxpath(d)
# 打开微信app,等待界面加载完成
sess = d.app_start('com.tencent.mm', wait=True) # start
d(resourceId="com.tencent.mm:id/icon_tv", text="发现").click() # 点击‘发现’控件
d(resourceId="com.tencent.mm:id/m38").click() # 点击‘朋友圈’控件
d(resourceId="com.tencent.mm:id/n9a").exists() # 判断朋友圈界面是否存在
time.sleep(2)
# 刷新朋友圈
if d(resourceId="com.tencent.mm:id/ef").exists():
d.double_click(0.522, 0.066)
d.swipe_ext('down', 3)
time.sleep(5)
match = False
while not match:
# 循环每一个朋友圈个体内容
for t in mi.dxpath('//*[@resource-id="com.tencent.mm:id/n9a"]'):
try:
# 分别找到该个体的网名、数据内容和朋友圈日期
comment = mi.dxpath_text(t, './/*[@resource-id="com.tencent.mm:id/cut"]')
name = mi.dxpath_text(t, './/*[@resource-id="com.tencent.mm:id/kbq"]')
# 用weditor发现date的日期文本数据在text[2]中,所以更改对应布尔值
date = mi.dxpath_text(t, './/*[@resource-id="com.tencent.mm:id/n93"]/', one=False, time_out=True)
# 当日期数据为一天前内容时,停止循环
match = re.search(r"天", date)
# 确保数据不重复并且非朋友圈广告信息
if comment not in data_value and not mi.dxpath_exist(t,'.//*[@resource-id="com.tencent.mm:id/egc"]'): # 不能是广告
print("抓取到{}朋友圈数据:\n{}\n时间为:{}".format(name, comment, date))
item = Item()
item.name = name
item.comment = comment
item.date = date
items.append(item)
data_value.add(comment)
# 输出目前总共收集了多少天数据
print('*' * 25 + str(len(data_value)))
except:
pass
# 滑动
d.swipe(300, 800, 300, 300, 0.1)
# 输出汇总数据
print(items)
运行结果如下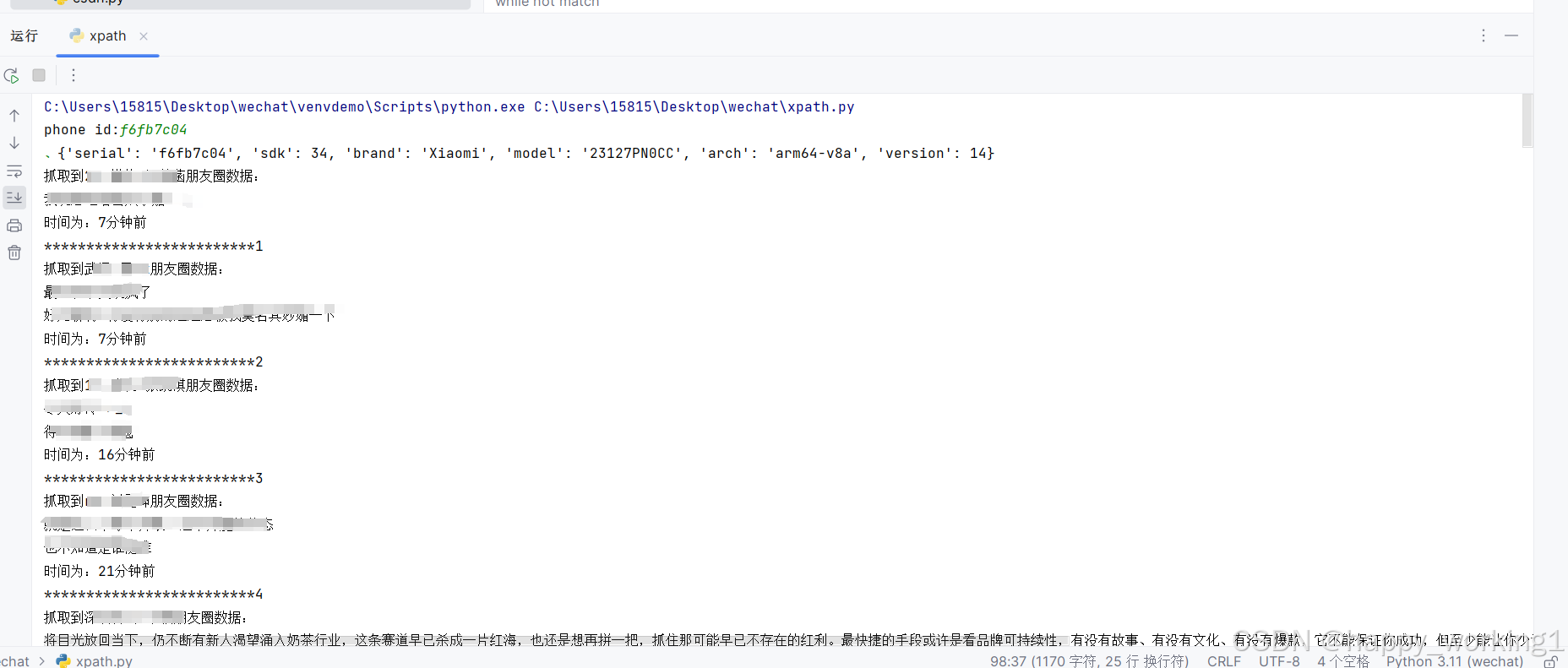

















 3315
3315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









