



想在自己的PC上部署一个大模型吗?只需两步:
- 从Ollama.com下载Ollama安装程序,并安装;
- 在控制台执行一条ollama指令下载指定的模型,比如ollama run deepseek-r1:8b 即为下载80亿参数的DeepSeek-R1-0528版本,等下载完成,即可愉快地对话啦。
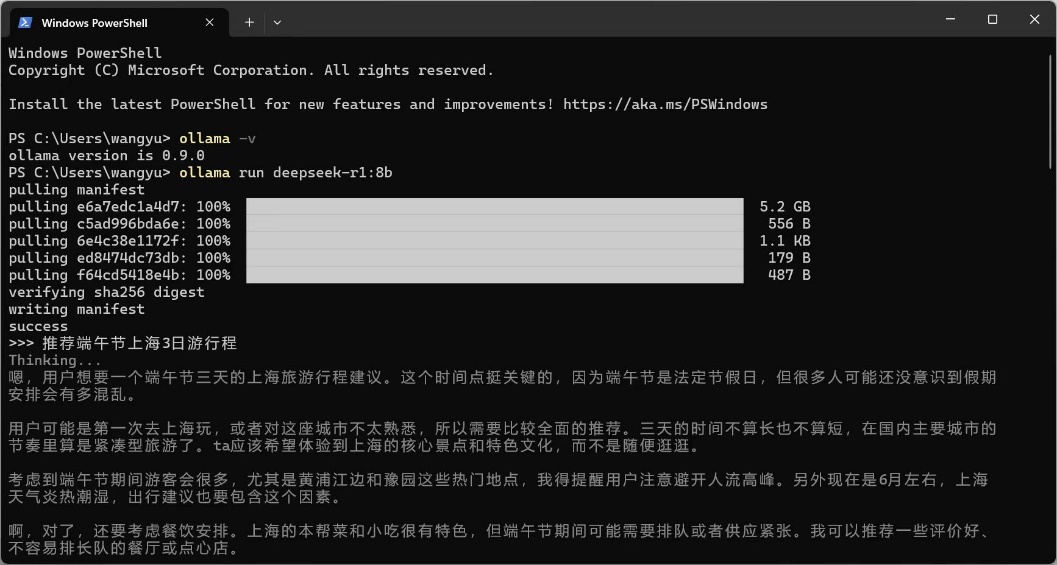
Ollama支持Windows、Linux、macOS,默认安装到C盘,须确保C盘有5GB以上的空间。Ollama支持的大模型有DeepSeek-R1, Qwen 3, Llama 3.3, Qwen 2.5‑VL, Gemma 3等。可以去官网Ollama Search 挑选,然后执行页面顶部提示的命令行即可。
接下来的问题是:怎么把大模型的对话能力嵌入到自己的软件里?既然Ollama是控制台输入/输出,我最初的想法是通过匿名管道来拦截它的输入输出,写了测试程序,结果没有跑通!其实,有更简单的方法,因为Ollama提供了REST API。如果在浏览器地址栏里输入http://localhost:11434,可以看到Ollama服务已经在默默工作了(要不然,可以在控制台运行ollama serve启动服务):
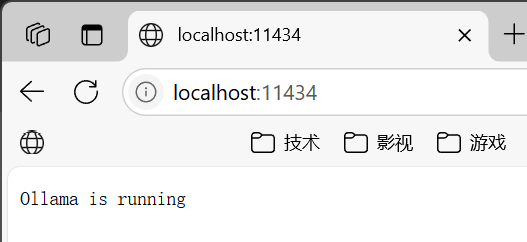
与Ollama服务器的通信方法也很简单,C++参考代码如下:
void CConsoleHostTestDlg::OnBnClickedButtonTest()
{
httplib::Client cli("localhost", 11434);
// 构建请求JSON
std::string request = R"(
{
"model": "llama2",
"prompt": "你好,请介绍一下自己。",
"stream": false
}
)";
// 调用Ollama API
auto res = cli.Post("/api/generate", request, "application/json");
if (res && res->status == 200) {
std::cout << "模型回复:" << res->body << std::endl;
}
else {
std::cout << "请求失败!";
if (res) {
std::cout << "状态码:" << res->status << std::endl;
}
}
}完整的演示程序在这里:https://github.com/luqiming666/OllamaTest,涉及如何在局域网里从一台机器请求另一台机器上的Ollama服务,以及如何做流式响应处理。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









