






1月29,Hadoop 10周年生日之际,CSDN主办的“Hadoop英雄会——暨Hadoop 10周年生日大趴”在北京举行,汇聚热爱开源,热爱大数据,热爱Hadoop的技术人,共同为Hadoop庆生(不方便来到现场的朋友也可以扫描文章最后的二维码通过Hadoop微信群进行更多的交流)。

中科院计算所副研究员、中国大数据技术大会(原Hadoop in China)发起人查礼,Hulu高级研发工程师董西成,Cloudera资深工程师李建伟,明略数据资深工程师梁堰波,以及AdMaster技术副总裁卢亿雷从计算、调度、存储、分析、安全、生态和应用等多个角度的分享了各个机构在Hadoop方面的工作,并与现场参会人员互动。此外,Hadoop之父、Cloudera首席架构师Doug Cutting还专门为此次活动发来视频贺词。

Doug Cutting:Hadoop的蓬勃还要持续几十年
在视频贺词中,Doug Cutting表示,他对大家使用Hadoop的各种应用感到非常欣慰,例如用它来挽救生命,医院里明显减少了败血症率,新生儿重症监护室改善早产儿的护理条件。甚至他的父亲,也是通过使用Hadoop的网上约会系统找到他人生的另一半。

Doug Cutting当初并没有预料到Hadoop能够取得今天的巨大成就,但这与社区的贡献有关。以开源的方式开始Hadoop的工作,是因为他相信开源的力量开源创造标准,人人共享,发展成主导地位,吸引更多的人参与进来并将其改善。他认为,Hadoop正处在其蓬勃发展期,这样的蓬勃还要持续几十年。
视频连接:http://v.qq.com/page/n/n/j/n0182mt5nnj.html
孟迎霞:将通过更多形式的活动推动Hadoop技术交流

CSDN总编孟迎霞在开场致辞中欢迎大家共聚一堂为Hadoop十周年庆生,并介绍了本次活动的演讲嘉宾。她同时表示,以Hadoop为代表的开源大数据技术一直是CSDN技术社区的关注重点,本次活动也是2016年CSDN社区活动的开始,后续将结合线上和线下,组织知识图谱、博文征文、技术问答、在线公开课、BDTC等一系列相关活动,真正推动包括Hadoop在内的技术交流与应用。
查礼:期待Hadoop生态更加繁荣

中科院计算所副研究员、中国大数据技术大会(原Hadoop in China)发起人查礼回顾Hadoop在中国的十年发展,他最初发起的Hadoop in China仅仅是60人规模,到2011年就达1000人的规模,在业界、社区的交流中,围绕Apache Hadoop建立起来的整套技术体系逐渐被大家所认识,HBase、Hive、Yarn等技术已经在大数据产业广泛应用。他希望看到Hadoop在下一个十年能有非常棒的工作和非常棒的项目,并推动大数据生态系统能够蓬勃发展,为整个学术界和工业界提供研究、改进业务及创业的机会。
董西成:Hadoop YARN程序设计与应用案例

Hulu高级研发工程师董西成介绍了Hadoop YARN程序设计与应用案例,包括Yarn API、开发步骤和一些实践经验,他重点介绍如何在Yarn上开发应用程序,包括一个client和一个ApplicationMaster。他还介绍了Container、TRACKING URL、LOG Rotation、Memory overhead、DEBUG和Label-based scheduling的经验。

PPT下载:董西成-Hadoop YARN程序设计与应用案例
李建伟:Spark将取代MapReduce成为Hadoop标准处理引擎
Cloudera资深技术工程师李建伟表示,当前我们谈Hadoop已经不只是Hadoop,已经扩展涵盖了Spark、Impala、Kafka、Flume、Avro、Hive、Pig、Mahout、ZooKeeper、Yarn等一系列的项目。未来的Hadoop数据处理,包括通用数据处理(Spark)、分析型数据库(Impala)、全文检索(Solr)和磁盘数据处理(MapReduce)等。

随着Spark的越来越成熟,它正慢慢的侵蚀MapReduce的地盘,李建伟认为,Spark终将取代MapReduce成为Hadoop标准处理引擎。Spark适合类似机器学习的迭代式工作,并随着和HBase、Solr等框架的集成,正迅速的成为一个好的普式计算引擎框架,而MapReduce适合IO密集型的,对容错和扩展性有更高要求的负载。
未来的发展,利用Hadoop本地资源管理、支持万级节点规模集群、支持80%的通用流处理工作负载、全面支持Hadoop安全是未来四大技术方向。通过Spark on Yarn集成、SparkSQL与Hive集成、Kerberos集成、Flume集成、Kafka集成、改进Scheduler对节点故障的处理、改进基于Shuffle的排序、基于HDFS数据本地化和HDFS缓存的任务调度等措施来实现。
谈到如何正确选择SQL引擎,他表示,批处理最好是Hive,SparkSQL目前还不够稳定,性能也逊于Impala,尤其在多并发情况下,在流数据处理、机器学习的场景,要做转换的时候,SparkSQL比较合适。
PPT下载:李建伟-Hadoop新技术介绍
梁堰波:SQL on Hadoop演进分析

明略数据的资深工程师梁堰波分享了目前主流的 SQL on Hadoop 框架。在他看来,企业使用这些架构的最终目的是为了搭建大数据时代的数据仓库。因此,Spark、Hive、Impala 等等这些架构并没有优劣之分,只有是否适合企业的自身业务。例如,Hive on Tez的性能完全可以达到 Spark 的水平,同时还可以将现有的企业无缝进行迁移,然后使用现有的的ODBC/JDBC、MetaStore等系统进行处理,运维人员不需要再去部署新的 Spark 集群。
PPT下载:梁堰波-SQL on Hadoop for 10 years
卢亿雷:Hadoop的应用及趟坑

AdMaster技术副总裁卢亿雷介绍Hadoop的应用和趟坑。AdMaster的Hadoop系统平台,包括在线计算(HBase)、离线计算(MapReduce)、流失计算(Storm)和实时计算(Spark)等几个部分,下面是HDFS和Yarn。在离线计算部分,为数据科学家提供pig做算法,工程师则通过Cascading编程。
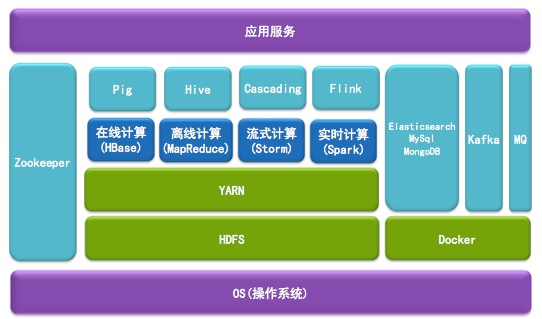
具体到AdMaster营销数据挖掘系统,做了如下的主要工作:
- MR:减少数据扩充,优化合并过程,使采集数据直接生成客户所需格式,提高处理速度;
- 算法:内置广告行业算法,不需要编写MapReduce就可以计算PV、UV等各种维度数据;
- HBase:优化HBase查询,专为社会化数据定制,提高处理性能;内置多SCAN实现;回收策略修改;
- 调度:集成数据任务调度系统,可以根据业务需求自动调整计算资源;
- Storm:集成Storm,优化Storm传输,减小数据延迟,实时提供数据计算;
- Spark:集成Spark,优化迭代工作负载,提高性能和存储效率。
所遇到的坑包括基本网络,硬件,ulimit、内存等系统配置,HDFS配置,Hadoop严重bug,Hbase配置等。比如硬盘大小不一致,balancer不会考虑,单盘打满,HBase Regions数太多,Snapshot量太多。bug方面,包括Datanode硬盘坏,服务重启,block不会被发现,压缩的jni C代码bug,导致作业无法成功等,这些已经在新版本中被修复。

PPT下载:卢亿雷-Hadoop应用及趟坑


















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









