






pymc和贝叶斯模型编程(1)
简介和安装
简介
PyMC是一个 Python 概率编程库,允许用户使用简单的 Python API 构建贝叶斯模型,并使用马尔可夫链蒙特卡罗 (MCMC) 方法对其进行拟合。
PyMC 致力于使贝叶斯建模尽可能简单、轻松,让用户能够专注于他们的问题而不是方法。
具有如下特性:
- 现代:包括最先进的推理算法,包括 MCMC (NUTS) 和变分推理 (ADVI)。
- 用户友好:使用友好的 Python 语法编写模型。从许多示例笔记本中学习贝叶斯建模。
- 快速:使用PyTensor作为计算后端,通过 C、Numba 或 JAX 进行编译,在 GPU 上运行模型,并从复杂的图形优化中受益。
- 拓展性好:包括概率分布、高斯过程、ABC、SMC 等等。它与用于可视化和诊断的ArviZ以及用于高级混合效果模型的Bambi完美集成。
- 以社区为中心:在讨论中提出问题、加入MeetUp 活动、在Twitter上关注我们并开始贡献。
PyMC和PyMC3?
PyMC3已重命名为PyMC,PyMC3 基于Theano计算 ,PyMC基于tensorflow 概率计算。
There have been many questions and uncertainty around the future of PyMC3 since Theano stopped getting developed by the original authors, and we started experiments with a PyMC version based on tensorflow probability. 自从原作者停止开发 Theano 以来,PyMC3 的未来存在许多问题和不确定性,我们开始使用基于张量流概率的 PyMC 版本进行实验。
pymc与pymc3的安装与使用_pymc和pymc3-CSDN博客的帖子是2020.11的,帖子中选择安装pymc3可能是当时pymc还没迁移好,pymc3的Theano不能用可能也是历史原因。总之我认为现在应该安装pymc。
安装
官方推荐:安装 — PyMC 开发文档 — Installation — PyMC dev documentation
官方只给了用conda创建包含pymc的python环境的示例,我尝试在3.9python执行pip命令,发现也可以成功安装。
pip install pymc
教程
通用API快速入门
PyMC 简介概述 — PyMC 开发文档 — Introductory Overview of PyMC — PyMC dev documentation
为了介绍模型定义、拟合和后验分析,我们首先考虑一个参数具有正态分布先验的简单贝叶斯线性回归模型。我们需要预测 Y Y Y , Y Y Y 是具有期望 μ \mu μ的正态分布观测值,其中 μ \mu μ是两个预测变量 X 1 X_1 X1 和 X 2 X_2 X2 的线性函数。
Y ∼ N ( μ , σ 2 ) μ = α + β 1 X 1 + β 2 X 2 \begin{aligned}&Y\sim\mathcal{N}(\mu,\sigma^{2})\\&\mu=\alpha+\beta_{1}X_{1}+\beta_{2}X_{2}\end{aligned} Y∼N(μ,σ2)μ=α+β1X1+β2X2
α \alpha α 是截距, β i \beta_i βi 是协变量的系数 , σ \sigma σ 代表观测误差。由于我们正在构建贝叶斯模型,因此必须为模型中的未知变量分配先验分布。我们为两个回归系数选择方差为 100 的零均值正态先验,这对应于有关真实参数值的弱信息。我们选择半正态分布 (以零为界的正态分布) 作为 σ \sigma σ的先验。
- 在贝叶斯建模中,未知参数都是随机变量,需要一个先验分布。
α ∼ N ( 0 , 100 ) β i ∼ N ( 0 , 100 ) σ ∼ ∣ N ( 0 , 1 ) ∣ \alpha\sim\mathcal{N}(0,100)\\\beta_{i}\sim\mathcal{N}(0,100)\\\sigma\sim|\mathcal{N}(0,1)| α∼N(0,100)βi∼N(0,100)σ∼∣N(0,1)∣
编程目标:
使用 NumPy 的random模块来模拟该模型中的一些人工数据,然后使用 PyMC 尝试恢复相应的参数。
创建模拟数据
'''导入依赖库'''
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pymc as pm
import pytensor.tensor as pt
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
# True parameter values
alpha, sigma = 1, 1
beta = [1, 2.5]
# Size of dataset
size = 100
# Predictor variable
X1 = np.random.randn(size)
X2 = np.random.randn(size) * 0.2
# Simulate outcome variable
Y = alpha + beta[0] * X1 + beta[1] * X2 + rng.normal(size=size) * sigma
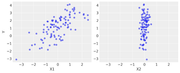
使用绘图库 matplotlib 来可视化数据。
fig, axes = plt.subplots(1, 2, sharex=True, figsize=(10, 4))
axes[0].scatter(X1, Y, alpha=0.6)
axes[1].scatter(X2, Y, alpha=0.6)
axes[0].set_ylabel("Y")
axes[0].set_xlabel("X1")
axes[1].set_xlabel("X2");
模型创建
PyMC 中的模型以Model类为中心。它引用所有随机变量 (RV) 并计算模型 logp 及其梯度。通常,您会将其实例化为with上下文的一部分:
basic_model = pm.Model()
with basic_model:
# Priors for unknown model parameters
alpha = pm.Normal("alpha", mu=0, sigma=10)
beta = pm.Normal("beta", mu=0, sigma=10, shape=2)
sigma = pm.HalfNormal("sigma", sigma=1)
# Expected value of outcome
mu = alpha + beta[0] * X1 + beta[1] * X2
# Likelihood (sampling distribution) of observations
Y_obs = pm.Normal("Y_obs", mu=mu, sigma=sigma, observed=Y)
- 在贝叶斯建模中,未知参数都是随机变量,实例中首先创建了alpha、beta和sigma三个随机变量。
我们调用pm.Normal构造函数来创建一个随机变量来用作普通先验。第一个参数始终是随机变量的名称,它几乎总是与分配给的 Python 变量的名称匹配,因为它有时用于从模型中检索变量以汇总输出。随机对象的其余必需参数是参数,在本例中mu (均值)和sigma (标准差),我们为模型分配超参数值。一般来说,分布的参数是确定随机变量的位置、形状或规模的值,具体取决于分布的参数化。 PyMC 中提供了最常用的分布,例如Beta 、 Exponential 、 Categorical 、 Gamma 、 Binomial等。
- 用这些随机变量建立输入和输出的关系,对应观测/证据和事实的关系
beta变量有一个附加的shape参数,将其表示为大小为 2 的向量值参数。 shape参数可用于所有分布,并指定随机变量的长度或形状,但对于标量变量来说是可选的,因为它默认值为一。它可以是一个整数来指定一个数组,也可以是一个元组来指定一个多维数组(例如shape=(5,7)生成一个具有 5 x 7 矩阵值的随机变量)。
- 有关分布、采样方法和其他 PyMC 函数的详细说明可在API 文档中找到。
mu是创建的一个确定性随机变量,它的值完全由其父级的值决定。也就是说,除了父母固有的不确定性之外,不存在任何不确定性。这里, mu只是截距alpha与beta系数和预测变量(无论它们的值是什么)的两个乘积之和。
PyMC 随机变量和数据可以任意加、减、除、乘并索引以创建新的随机变量。这可以实现出色的模型表现力。还提供了许多常见的数学函数,如sum 、 sin 、 exp和线性代数函数,如dot (用于内积)和inv (用于逆)。
Y
_
o
b
s
=
N
o
r
m
a
l
(
′
Y
_
o
b
s
′
,
m
u
=
m
u
,
s
i
g
m
a
=
s
i
g
m
a
,
o
b
s
e
r
v
e
d
=
Y
)
Y\_obs = Normal('Y\_obs', mu=mu, sigma=sigma, observed=Y)
Y_obs=Normal(′Y_obs′,mu=mu,sigma=sigma,observed=Y)是随机变量的特殊情况,我们称之为观察随机变量,表示模型的数据可能性。它与标准随机变量相同,只是其observed参数(将数据传递给变量)表明该变量的值已被观察到,并且不应通过应用于模型的任何拟合算法来更改。数据可以以ndarray或DataFrame对象的形式传递。请注意,与模型的先验不同, Y_obs正态分布的参数不是固定值,而是确定性对象mu和随机sigma 。这会在似然和这两个变量之间创建父子关系。
模型采样
with basic_model:
# draw 1000 posterior samples
idata = pm.sample()
'''如果想使用切片采样算法而不是 NUTS(默认)来对参数进行采样,我们可以将其指定sample step参数'''
with basic_model:
# instantiate sampler
step = pm.Slice()
# draw 5000 posterior samples
slice_idata = pm.sample(5000, step=step)
sample函数运行指定(或传递)给它的步骤方法,进行给定的迭代次数,并返回一个InferenceData对象,其中包含收集的样本,以及其他有用的属性,例如采样运行的统计数据和观察到的样本的副本数据。请注意, sample生成了一组并行链,具体取决于计算机上的计算核心数量。
InferenceData对象的各种属性可以通过与包含从变量名称到numpy.array的映射的dict类似的方式进行查询。例如,我们可以使用变量名称作为idata.posterior属性的索引,从alpha潜在变量中检索采样轨迹。返回数组的第一个维度是链索引,第二个维度是采样索引,而后面的维度与变量的形状匹配。我们可以看到每个链中alpha变量的前 5 个值,如下所示:
idata.posterior["alpha"].sel(draw=slice(0, 4))
'''output'''
array([[1.08791286, 1.26743895, 1.06451118, 1.26389222, 1.02433296],
[1.13701586, 1.17487733, 1.17487733, 1.19980906, 1.12605183],
[1.15928954, 1.19440076, 1.18434845, 1.03366877, 1.26142365],
[1.28337771, 1.11653209, 1.17667272, 1.03302484, 1.23291747]])
后验分析
PyMC的绘图和诊断功能由一个名为Arviz 的专用的、与平台无关的第三方库来处理。可以使用plot_trace创建简单的后验图。左列由每个随机变量的边缘后验的平滑直方图(使用核密度估计)组成,而右列包含按顺序绘制的马尔可夫链样本。 beta变量是矢量值,生成两个密度图和两个迹线图,对应于两个预测系数。
az.plot_trace(idata, combined=True);

此外, summary函数提供了常见后验统计的基于文本的输出:
az.summary(idata, round_to=2)

案例研究 1:听障儿童的教育成果
作为一个激励性的例子,我们将使用听力障碍儿童的教育成果数据集。在这里,我们感兴趣的是确定与更好或更差的学习成果相关的因素。
该匿名数据集取自听力和口语数据存储库 (LSL-DR),这是一个国际数据存储库,用于跟踪患有听力损失并参加专注于支持听力和口语发展的项目的儿童的人口统计数据和纵向结果。研究人员有兴趣发现与这些项目中教育成果改善相关的因素。
预测变量包括性别、家庭中兄弟姐妹的数量、母语是否英语、是否残疾等,结果变量是几个学习领域之一的标准化测试分数。
数学建模:预测变量选择
这是一个比第一个回归示例更现实的问题,因为我们现在正在处理多元回归模型。然而,虽然 LSL-DR 数据集中存在多个潜在的预测变量,但很难先验地确定哪些预测变量与构建有效的统计模型相关。进行变量选择的方法有很多种,但一种流行的自动化方法是正则化,如果无效协变量对预测结果没有贡献,则通过正则化(一种惩罚形式)将无效协变量缩小到零。
您可能听说过机器学习或经典统计应用程序中的正则化,其中诸如套索或岭回归之类的方法通过对回归参数的大小应用惩罚来将参数缩小到零。在贝叶斯背景下,我们对回归系数应用适当的先验分布:
分层正则化马蹄形先验
它使用两种正则化策略,一个全局参数和一组局部参数,每个参数一个。实现这项工作的关键是选择一个长尾分布作为收缩先验,它允许一些分布非零,同时将其余分布推向零。
每个回归系数的马蹄先验 β i \beta_i βi 看起来像这样: β i ∼ N ( 0 , τ 2 ⋅ λ ~ i 2 ) \beta_i \sim N\left(0, \tau^2 \cdot \tilde{\lambda}_i^2\right) βi∼N(0,τ2⋅λ~i2)其中 σ \sigma σ 是误差标准差的先验,也将用于模型似然; τ \tau τ 是全局收缩参数, λ ~ i \tilde{\lambda}_i λ~i 是局部收缩参数。
让我们从全局开始:
τ
\tau
τ 我们将使用 Half-StudentT 分布,这是一个合理的选择,因为它是重尾的。
τ
∼
Half-StudentT
2
(
D
0
D
−
D
0
⋅
σ
N
)
\tau \sim \text { Half-StudentT }{ }_2\left(\frac{D_0}{D-D_0} \cdot \frac{\sigma}{\sqrt{N}}\right)
τ∼ Half-StudentT 2(D−D0D0⋅Nσ)
这里有个问题是先验的参数化需要预先指定的值
D
0
D_0
D0 ,它表示非零系数的真实数量。幸运的是,只需要对这个值进行合理的猜测,并且它只需在真实数字的一个数量级内即可。让我们使用预测变量数量的一半作为我们的猜测:
D
0
=
i
n
t
(
D
/
2
)
D0 = int(D / 2)
D0=int(D/2)
局部收缩参数由以下比率定义:
λ
~
i
2
=
c
2
λ
i
2
c
2
+
τ
2
λ
i
2
\tilde{\lambda}_i^2=\frac{c^2 \lambda_i^2}{c^2+\tau^2 \lambda_i^2}
λ~i2=c2+τ2λi2c2λi2
为了完成这个规范,我们需要先验知识
λ
i
\lambda_i
λi 和
c
c
c 和全局收缩一样,我们使用长尾 Half-StudentT
5
{ }_5
5 (1)于
λ
i
\lambda_i
λi 。我们需要
c
2
c^2
c2 严格为正,但不一定是长尾,因此逆伽马
c
2
,
c
2
∼
InverseGamma
(
1
,
1
)
c^2 , c^2 \sim \operatorname{InverseGamma}(1,1)
c2,c2∼InverseGamma(1,1) 符合要求。
最后,为了让 NUTS 采样器更有效地采样
β
i
\beta_i
βi ,我们将重新参数化它,如下所示:
z
i
∼
N
(
0
,
1
)
β
i
=
z
i
⋅
τ
⋅
λ
i
~
\begin{aligned} z_i & \sim N(0,1) \\ \beta_i & =z_i \cdot \tau \cdot \tilde{\lambda_i} \end{aligned}
ziβi∼N(0,1)=zi⋅τ⋅λi~
在实践中你会经常遇到这种重新参数化的情况。
模型编程
import pytensor.tensor as pt
with pm.Model(coords={"predictors": X.columns.values}) as test_score_model:
# Prior on error SD
sigma = pm.HalfNormal("sigma", 25)
# Global shrinkage prior
tau = pm.HalfStudentT("tau", 2, D0 / (D - D0) * sigma / np.sqrt(N))
# Local shrinkage prior
lam = pm.HalfStudentT("lam", 5, dims="predictors")
c2 = pm.InverseGamma("c2", 1, 1)
z = pm.Normal("z", 0.0, 1.0, dims="predictors")
# Shrunken coefficients
beta = pm.Deterministic(
"beta", z * tau * lam * pt.sqrt(c2 / (c2 + tau**2 * lam**2)), dims="predictors"
)
# No shrinkage on intercept
beta0 = pm.Normal("beta0", 100, 25.0)
scores = pm.Normal("scores", beta0 + pt.dot(X.values, beta), sigma, observed=y.values)
beta的计算包装在Deterministic PyMC 类中。
模型完成后,我们可以使用 GraphViz 查看其结构,它会绘制模型图。确保您编码的模型中的关系正确非常有用,因为很容易出现编码错误。
pm.model_to_graphviz(test_score_model)

预先预测采样
在继续之前,让我们看看模型在看到数据之前会做什么。我们可以进行预先预测采样,以从模型生成模拟数据。然后,我们将这些模拟与数据集中的实际测试分数进行比较。
with test_score_model:
prior_samples = pm.sample_prior_predictive(100)
az.plot_dist(
test_scores["score"].values,
kind="hist",
color="C1",
hist_kwargs=dict(alpha=0.6),
label="observed",
)
az.plot_dist(
prior_samples.prior_predictive["scores"],
kind="hist",
hist_kwargs=dict(alpha=0.6),
label="simulated",
)
plt.xticks(rotation=45);

**判断是否合理需要相关领域知识。**这这里,模拟数据分布的支持与观察到的分数分布的支持大体重叠;这是一个好兆头!有一些负值,还有一些偏大值,但无需担心。
模型拟合
现在是简单的部分:PyMC 的“推理按钮”是调用sample。我们会让这个模型的调整时间比默认值(1000 次迭代)稍长一些。这给了 NUTS 采样器更多的时间来充分调整自身。
with test_score_model:
idata = pm.sample(1000, tune=2000, random_seed=42)
'''请注意,在这里程序会出现关于分歧的警告: NUTS 无法在后验分布中进行有效移动的样本,因此得到的点可能不是后验分布的代表性样本。
这里样本比较少,所以不用在意这个报错,但让我们继续遵循建议,将target_accept从默认值 0.9 增加到 0.99。'''
with test_score_model:
idata = pm.sample(1000, tune=2000, random_seed=42, target_accept=0.99)
由于目标接受率较大,算法的跳跃步数更加保守,使得步数更小。我们为此付出的代价是每个样本需要更长的时间才能完成。然而,警告现在消失了,我们有一个干净的后验样本!
模型检查
单变量潜在参数的跟踪图
模型检查的一个简单的第一步是通过查看单变量潜在参数的跟踪图来目视检查我们的样本,以检查是否存在明显的问题。这些名称可以传递给var_names参数中的plot_trace 。
az.plot_trace(idata, var_names=["tau", "sigma", "c2"]);

这些看起来还好吗?好吧,每个参数左侧的每个密度看起来都与其他参数非常相似,这意味着它们已经收敛到相同的后验分布(无论是否正确)。右侧迹线图的同质性也是一个好兆头;采样值的时间序列没有趋势或模式。请注意, c2和tau偶尔会采样极值,但这是重尾分布的预期。
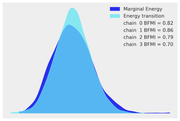
查看 NUTS 采样器是否按预期执行
能量图是检查 NUTS 算法是否能够充分探索后验分布的一种方法。如果探索不充分,当后验的某些部分没有被足够的频率访问时,人们就会面临后验估计有偏差的风险。该图显示了两种密度估计:一种是采样运行的边际能量分布,另一种是步骤之间能量转换的分布。这有点抽象,但我们所寻找的只是分布彼此相似。我们的看起来还不错。
az.plot_energy(idata);
结果查看
最终,我们感兴趣的是beta的估计,即预测系数集。将beta传递给plot_trace会生成非常拥挤的图,因此我们将使用plot_forest ,它旨在处理向量值参数。
az.plot_forest(idata, var_names=["beta"], combined=True, hdi_prob=0.95, r_hat=True);
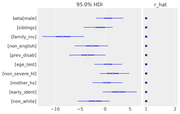
系数的后验分布揭示了一些对预测考试成绩似乎很重要的因素。家庭参与度 ( family_inv ) 较大且呈负数,这意味着较高的分数(与较差的参与度相关)会导致测试成绩更差。另一方面,早期识别听力障碍是积极的,这意味着尽早发现问题可以带来更好的教育成果,这也是直观的。请注意,其他变量,特别是性别 ( male )、测试年龄 ( age_test ) 和母亲的教育状况 ( mother_hs ) 都已基本缩小到零。
案例研究 2:煤矿灾害
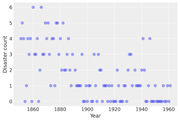
考虑以下从 1851 年到 1962 年英国记录的煤矿灾害的时间序列(Jarrett,1979)。据认为,灾难的数量受到了这一时期安全法规变化的影响。不幸的是,我们有两年的数据丢失,被 pandas Series中的nan识别为丢失。**这些缺失值将由 PyMC 自动估算。**接下来我们将为这个系列构建一个模型,并尝试估计变化发生的时间。同时,我们将了解如何处理缺失数据、使用多个采样器以及从离散随机变量中采样。
# fmt: off
disaster_data = pd.Series(
[4, 5, 4, 0, 1, 4, 3, 4, 0, 6, 3, 3, 4, 0, 2, 6,
3, 3, 5, 4, 5, 3, 1, 4, 4, 1, 5, 5, 3, 4, 2, 5,
2, 2, 3, 4, 2, 1, 3, np.nan, 2, 1, 1, 1, 1, 3, 0, 0,
1, 0, 1, 1, 0, 0, 3, 1, 0, 3, 2, 2, 0, 1, 1, 1,
0, 1, 0, 1, 0, 0, 0, 2, 1, 0, 0, 0, 1, 1, 0, 2,
3, 3, 1, np.nan, 2, 1, 1, 1, 1, 2, 4, 2, 0, 0, 1, 4,
0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1]
)
# fmt: on
years = np.arange(1851, 1962)
plt.plot(years, disaster_data, "o", markersize=8, alpha=0.4)
plt.ylabel("Disaster count")
plt.xlabel("Year");
数学建模:煤矿灾害事件
时间序列中灾难的发生被认为遵循泊松过程,在时间序列的早期部分具有较大的速率参数,而在后面的部分则遵循较小的速率参数。我们有兴趣找出该系列中的变化点,这可能与采矿安全法规的变化有关。
D
t
∼
Pois
(
r
t
)
,
r
t
=
{
e
,
if
t
≤
s
l
,
if
t
>
s
s
∼
Unif
(
t
l
,
t
h
)
e
∼
exp
(
1
)
l
∼
exp
(
1
)
\begin{aligned} D_t & \sim \operatorname{Pois}\left(r_t\right), r_t= \begin{cases}e, & \text { if } t \leq s \\ l, & \text { if } t>s\end{cases} \\ s & \sim \operatorname{Unif}\left(t_l, t_h\right) \\ e & \sim \exp (1) \\ l & \sim \exp (1) \end{aligned}
Dtsel∼Pois(rt),rt={e,l, if t≤s if t>s∼Unif(tl,th)∼exp(1)∼exp(1)
- D t : D_t: Dt: 一年中发生的灾害次数 t t t
- r t : r_t: rt: 年份灾害泊松分布的比率参数 t t t 。
- s : s: s: 速率参数发生变化的年份(切换点)。
- e : e : e: 切换点 s s s 前的速率参数。
- l : l: l: 切换点 s s s 后的速率参数。
- t l , t h : t_l, t_h: tl,th: 年份的下限和上限 t t t 。
模型编程
该模型的构建方式与我们之前的模型非常相似。主要区别在于引入了具有泊松和离散均匀先验的离散变量以及确定性随机变量rate的新颖形式。
with pm.Model() as disaster_model:
switchpoint = pm.DiscreteUniform("switchpoint", lower=years.min(), upper=years.max())
# Priors for pre- and post-switch rates number of disasters
early_rate = pm.Exponential("early_rate", 1.0)
late_rate = pm.Exponential("late_rate", 1.0)
# Allocate appropriate Poisson rates to years before and after current
rate = pm.math.switch(switchpoint >= years, early_rate, late_rate)
disasters = pm.Poisson("disasters", rate, observed=disaster_data)
rate随机变量是使用switch实现的,该函数的工作原理类似于 if 语句。它使用第一个参数在接下来的两个参数之间切换。
模型拟合
在创建观察到的随机变量时,通过将 NumPy MaskedArray或具有 NaN 值的DataFrame传递给observed参数来透明地处理缺失值。在幕后,创建另一个随机变量: disasters.missing_values来对缺失值进行建模。
不幸的是,由于它们是离散变量,因此没有有意义的梯度,因此我们不能使用 NUTS 来对switchpoint或缺失的灾害观测进行采样。相反,我们将使用Metropolis步骤方法进行采样,该方法实现了自适应 Metropolis-Hastings,因为它旨在处理离散值。 PyMC 自动分配正确的采样算法。
with disaster_model:
idata = pm.sample(10000)
模型检查
在下面的迹线图中,我们可以看到大约 10 年的跨度可能会导致安全性发生重大变化,但 5 年的跨度包含大部分概率质量。由于年份切换点和可能性之间的跳跃关系,分布呈锯齿状;锯齿状不是由于采样误差造成的。
axes_arr = az.plot_trace(idata)
plt.draw()
for ax in axes_arr.flatten():
if ax.get_title() == "switchpoint":
labels = [label.get_text() for label in ax.get_xticklabels()]
ax.set_xticklabels(labels, rotation=45, ha="right")
break
plt.draw()

请注意, rate随机变量不会出现在迹线中。在这种情况下这很好,因为它本身并不令人感兴趣。请记住前面的示例,我们将通过将变量包装在Deterministic类中并为其命名来跟踪该变量。
下图将切换点显示为橙色垂直线,并将其最高后验密度 (HPD) 显示为半透明带。黑色虚线表示事故率。
plt.figure(figsize=(10, 8))
plt.plot(years, disaster_data, ".", alpha=0.6)
plt.ylabel("Number of accidents", fontsize=16)
plt.xlabel("Year", fontsize=16)
trace = idata.posterior.stack(draws=("chain", "draw"))
plt.vlines(trace["switchpoint"].mean(), disaster_data.min(), disaster_data.max(), color="C1")
average_disasters = np.zeros_like(disaster_data, dtype="float")
for i, year in enumerate(years):
idx = year < trace["switchpoint"]
average_disasters[i] = np.mean(np.where(idx, trace["early_rate"], trace["late_rate"]))
sp_hpd = az.hdi(idata, var_names=["switchpoint"])["switchpoint"].values
plt.fill_betweenx(
y=[disaster_data.min(), disaster_data.max()],
x1=sp_hpd[0],
x2=sp_hpd[1],
alpha=0.5,
color="C1",
)
plt.plot(years, average_disasters, "k--", lw=2);

自定义任意运算
由于对 PyTensor 的依赖,PyMC 提供了许多数学函数和运算符,用于将随机变量转换为新的随机变量。然而,PyTensor 中的函数库并不详尽,因此 PyTensor 和 PyMC 提供了在纯 Python 中创建任意函数的功能,并将这些函数包含在 PyMC 模型中。这是由as_op函数装饰器支持的。
PyTensor 需要知道函数的输入和输出的类型,这些类型由输入的itypes和输出的otypes为as_op指定。
from pytensor.compile.ops import as_op
@as_op(itypes=[pt.lscalar], otypes=[pt.lscalar])
def crazy_modulo3(value):
if value > 0:
return value % 3
else:
return (-value + 1) % 3
with pm.Model() as model_deterministic:
a = pm.Poisson("a", 1)
b = crazy_modulo3(a)
这种方法的一个重要缺点是pytensor不可能检查这些函数来计算基于哈密顿量的采样器所需的梯度。因此,对于使用此类运算符的模型,不可能使用 HMC 或 NUTS 采样器。但是,如果我们继承Op而不是使用as_op ,则可以添加梯度。 PyMC 示例集包含更详细的 as_op 用法示例。
自定义任意分布
同样,PyMC 中的统计分布库并不详尽,但 PyMC 允许为任意概率分布创建用户定义的函数。对于简单的统计分布, CustomDist类将任何计算对数概率的函数作为参数
log
(
p
(
x
)
)
\log (p(x))
log(p(x))。该函数可以在其计算中使用其他随机变量。这是一个示例,灵感来自 Jake Vanderplas 的一篇博客文章,其中先验用于线性回归(Vanderplas,2014)。
import pytensor.tensor as pt
with pm.Model() as model:
alpha = pm.Uniform('intercept', -100, 100)
# Create variables with custom log-densities
beta = pm.CustomDist('beta', logp=lambda value: -1.5 * pt.log(1 + value**2))
eps = pm.CustomDist('eps', logp=lambda value: -pt.log(pt.abs_(value)))
# Create likelihood
like = pm.Normal('y_est', mu=alpha + beta * X, sigma=eps, observed=Y)
对于更复杂的分布,可以创建Continuous或Discrete的子类,并根据需要提供自定义logp函数。这就是 PyMC 中内置发行版的指定方式。例如,心理学和天体物理学等领域对于可能需要数值近似的特定过程具有复杂的似然函数。下面显示了将上面的beta变量实现为Continuous子类以及关联的RandomVariable对象,该对象的实例成为分布的属性。
class BetaRV(pt.random.op.RandomVariable):
name = "beta"
ndim_supp = 0
ndims_params = []
dtype = "floatX"
@classmethod
def rng_fn(cls, rng, size):
raise NotImplementedError("Cannot sample from beta variable")
beta = BetaRV()
class Beta(pm.Continuous):
rv_op = beta
@classmethod
def dist(cls, mu=0, **kwargs):
mu = pt.as_tensor_variable(mu)
return super().dist([mu], **kwargs)
def logp(self, value):
mu = self.mu
return beta_logp(value - mu)
def beta_logp(value):
return -1.5 * pt.log(1 + (value) ** 2)
with pm.Model() as model:
beta = Beta("beta", mu=0)
如果你的 logp 无法用 PyTensor 表达,你可以用as_op修饰函数,如下所示: @as_op(itypes=[pt.dscalar], otypes=[pt.dscalar]) 。请注意,这将创建一个黑盒 Python 函数,该函数会慢得多,并且不提供 NUTS 等所需的梯度。
讨论
概率编程是统计学习中的新兴范例,贝叶斯建模是其中的一个重要子学科。概率编程的标志性特征——将变量指定为概率分布以及其他变量和观测值的调节变量——使其成为在各种设置和各种模型复杂性范围内构建模型的强大工具。伴随着概率规划的兴起,贝叶斯模型拟合方法出现了一系列创新,这代表了对现有 MCMC 方法的显着改进。然而,尽管有这种扩展,但很少有可用的软件包能够跟上方法创新的步伐,而且允许非专家用户实现模型的软件包更少。
PyMC为定量研究人员提供了一个概率编程平台,可以灵活、简洁地实现统计模型。大型统计分布库和几种预定义的拟合算法使用户能够专注于手头的科学问题,而不是贝叶斯建模的实现细节。选择 Python 作为开发语言,而不是特定于领域的语言,意味着 PyMC 用户能够使用动态的高级编程语言以交互方式构建模型、内省模型对象以及调试或分析其工作这很容易学。 PyMC 的模块化、面向对象的设计意味着添加新的拟合算法或其他功能非常简单。此外,PyMC 还具有大多数其他软件包中没有的几个功能,最显着的是基于哈密顿量的采样器以及仅由 Stan 提供的约束随机变量的自动转换。然而,与 Stan 不同的是,PyMC 支持离散变量以及基于非梯度的采样算法,例如 Metropolis-Hastings 和 Slice 采样。
PyMC 的开发是一项持续的工作,并且计划在未来版本中提供一些功能。最值得注意的是,变分推理技术通常比 MCMC 采样更有效,但代价是普遍性。然而,最近开发了黑盒变分推理算法,例如自动微分变分推理(ADVI;Kucukelbir 等人,2017)。该算法预计将添加到 PyMC 中。作为开源科学计算工具包,我们鼓励研究人员为贝叶斯模型开发新的拟合算法,以在 PyMC 中提供参考实现。由于采样器可以用纯 Python 代码编写,因此可以普遍实现它们以使其在任意 PyMC 模型上工作,从而为作者提供更多的受众来使用他们的方法。
结语
在下一篇会使用pymc进行变分推理。
。选择 Python 作为开发语言,而不是特定于领域的语言,意味着 PyMC 用户能够使用动态的高级编程语言以交互方式构建模型、内省模型对象以及调试或分析其工作这很容易学。 PyMC 的模块化、面向对象的设计意味着添加新的拟合算法或其他功能非常简单。此外,PyMC 还具有大多数其他软件包中没有的几个功能,最显着的是基于哈密顿量的采样器以及仅由 Stan 提供的约束随机变量的自动转换。然而,与 Stan 不同的是,PyMC 支持离散变量以及基于非梯度的采样算法,例如 Metropolis-Hastings 和 Slice 采样。
PyMC 的开发是一项持续的工作,并且计划在未来版本中提供一些功能。最值得注意的是,变分推理技术通常比 MCMC 采样更有效,但代价是普遍性。然而,最近开发了黑盒变分推理算法,例如自动微分变分推理(ADVI;Kucukelbir 等人,2017)。该算法预计将添加到 PyMC 中。作为开源科学计算工具包,我们鼓励研究人员为贝叶斯模型开发新的拟合算法,以在 PyMC 中提供参考实现。由于采样器可以用纯 Python 代码编写,因此可以普遍实现它们以使其在任意 PyMC 模型上工作,从而为作者提供更多的受众来使用他们的方法。
结语
在下一篇会使用pymc进行变分推理。
某乎、某书、某号同名,期待您的关注!
















 431
431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











