






t-SNE和UMAP学习记录
来源:https://www.youtube.com/watch?v=o_cAOa5fMhE
t-SNE
思想:
使高维接近的点在低维投影仍然接近
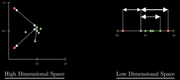
数学建模
∂ Loss (HighDim, LowDim) ∂ LowDim \frac{\partial \text { Loss (HighDim, LowDim) }}{\partial \text { LowDim }} ∂ LowDim ∂ Loss (HighDim, LowDim)
-
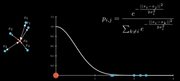
将点距离远近转换为归一化的高斯概率分布(高维空间)。
方差 σ \sigma σ为超参数,称为困惑度, σ \sigma σ值越大,覆盖的点越多,但在实践中,他的作用不明显,需要多尝试直到对可视化满意。此外,困惑度越大计算越慢。
p i , j = e − ∥ x i − x j ∥ 2 2 σ i 2 ∑ k ≠ i e − ∥ x i − x k ∥ 2 2 σ i 2 p_{i, j}=\frac{e^{-\frac{\left\|x_i-x_j\right\|^2}{2 \sigma_i^2}}}{\sum_{k \neq i} e^{-\frac{\left\|x_i-x_k\right\|^2}{2 \sigma_i^2}}} pi,j=∑k=ie−2σi2∥xi−xk∥2e−2σi2∥xi−xj∥2
-
在低维空间随机初始化一个分布,点距离同样用归一化高斯概率分布表示
q i , j = e − ∥ y i − y j ∥ 2 ∑ k ≠ i e − ∥ y i − y k ∥ q_{i, j}=\frac{e^{-\left\|y_i-y_j\right\|^2}}{\sum_{k \neq i} e^{-\left\|y_i-y_k\right\|}} qi,j=∑k=ie−∥yi−yk∥e−∥yi−yj∥2
-
用KL散度描述p、q分布的差异
D K L ( P ∥ Q ) = ∑ i P ( i ) log P ( i ) Q ( i ) D_{K L}(P \| Q)=\sum_i P(i) \log \frac{P(i)}{Q(i)} DKL(P∥Q)=i∑P(i)logQ(i)P(i)

-
KL散度对低维求梯度,据此调整低维分布
∂ D K L ( P ∥ Q ) ∂ y i = 2 ∑ j ( p i , j − q i , j + p j , i − q j , i ) ( y i − y j ) \frac{\partial D_{K L}(P \| Q)}{\partial y_i}=2 \sum_j\left(p_{i, j}-q_{i, j}+p_{j, i}-q_{j, i}\right)\left(y_i-y_j\right) ∂yi∂DKL(P∥Q)=2j∑(pi,j−qi,j+pj,i−qj,i)(yi−yj)
优缺点
相较于PCA,主要优点是可以处理非线性数据。

主要缺点是运算慢,困惑度越大计算越慢,t-SNE使用t分布加速运算。
UMAP
思想
使高维接近的点在低维投影仍然接近,但不是使用概率分布,而是使用图来表示高维和低维数据。

主要步骤
找到每个样本的最近k个邻居,得到初始的二元图。k是UMAP的主要超参数。

二元图转换为加权图,以表示每个点与邻居的接近程度。
v i , j = e − max ( 0 , d ( x i , x j ) − ρ i ) σ i v_{i, j}=e^{-\frac{\max \left(0, d\left(x_i, x_j\right)-\rho_i\right)}{\sigma_i}} vi,j=e−σimax(0,d(xi,xj)−ρi)
ρ i = distance to nearest neighbor \rho_i=\text { distance to nearest neighbor } ρi= distance to nearest neighbor ,概率值随着距离增加指数衰减,最近的邻居权重为1。不用归一化,运算速度比t-SNE更快。
将所有样本的加权图合并为1个

方式是将图对称化,使得任意两个点之间只有一条边:
w
i
j
=
v
i
,
j
+
v
j
,
i
−
v
i
,
j
⋅
v
j
,
i
w_{i j}=v_{i, j}+v_{j, i}-v_{i, j} \cdot v_{j, i}
wij=vi,j+vj,i−vi,j⋅vj,i
这个方程的作用是,结合边,并保持权重在0和1之间。
对高维和低维表示最小化交叉熵
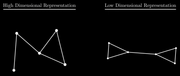
用邻接矩阵表示加权图

∑ i , j w h d ( i , j ) log ( w h d ( i , j ) w l d ( i , j ) ) + ( 1 − w h d ( i , j ) ) log ( 1 − w h d ( i , j ) 1 − w l d ( i , j ) ) \sum_{i, j} w_{h d}(i, j) \log \left(\frac{w_{h d}(i, j)}{w_{l d}(i, j)}\right)+\left(1-w_{h d}(i, j)\right) \log \left(\frac{1-w_{h d}(i, j)}{1-w_{l d}(i, j)}\right) i,j∑whd(i,j)log(wld(i,j)whd(i,j))+(1−whd(i,j))log(1−wld(i,j)1−whd(i,j))
优缺点
优点:计算快,效果好,擅长保持全局结构。
缺点:超参数影响大。
python
pip install umap-learn
import umap
reducer = umap.UMAP()
embedding = reducer.fit_transform(scaled_penguin_data)
'''-----------------------------------------------------------------'''
UMAP(a=None, angular_rp_forest=False, b=None,
force_approximation_algorithm=False, init='spectral', learning_rate=1.0,
local_connectivity=1.0, low_memory=False, metric='euclidean',
metric_kwds=None, min_dist=0.1, n_components=2, n_epochs=None,
n_neighbors=15, negative_sample_rate=5, output_metric='euclidean',
output_metric_kwds=None, random_state=42, repulsion_strength=1.0,
set_op_mix_ratio=1.0, spread=1.0, target_metric='categorical',
target_metric_kwds=None, target_n_neighbors=-1, target_weight=0.5,
transform_queue_size=4.0, transform_seed=42, unique=False, verbose=False)
=-1, target_weight=0.5,
transform_queue_size=4.0, transform_seed=42, unique=False, verbose=False)
















 5866
5866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











