







fastai 2.x 版本 源码安装
GitHub - fastai/fastai: The fastai deep learning library

卸载pip的安装包:
pip list 看要卸载哪一个包
pip uninstall xxxx包
写在前面:
最近把fastai的lesson1-lesson12都看完了。我的中文笔记见:
所有中文笔记的CSDN下载地址:fastai-noteslesson1-lesson12中文notes.zip-电信文档类资源-CSDN下载![]() https://download.csdn.net/download/haronchou/43015323
https://download.csdn.net/download/haronchou/43015323
在自己再次看代码途中,期望能用debug的方式学习。我的环境为:docker(fastai) + vscode-ssh。笔记jupyter的方式无法debug。尝试了vscode .python方式debug,可以看到learn = cnn_learner()。步进之后的learn具有的所有变量和函数,感觉很惊讶,原来这个变量里面还有那么多东西。产生了去看源代码的想法。
在逛fastai forum的时候,看到如下帖子:Eight ways to debug in fastai - #24 by slawekbiel - Part 1 (2020) - Deep Learning Course Forums
发现可以debug到库的每一行去。
- VS Code 连接到远程主机 - https://www.youtube.com/watch?v=xovzuPfuglE&t=5m24s

我天,还可以这样使用!!!!
环境搭建:
在fastai forum看到如下的帖子,关注到要debug源码的话,是需要git clone fastai的源码的。

- ① 如帖子中提到的(上图),需要git clone fastai的源码才可以。
- ② 需要特定的fastai v1 1.0.61版本,比较适合fastai.course.v3
- 2019的coursev3 notebook是要使用fastai1.0.61的版本差不多
- 第一个,拉取1.0.61版本的代码:
参考方式:
GitHub下载克隆clone指定的分支tag代码 - Tse先生 - 博客园 -
解决方法:
命令:git clone --branch [tags标签] [git地址] 或者 git clone --b [tags标签] [git地址]
例如:git clone -b 1.4.1 https://github.com/jumpserver/coco.git
-
# step 1 git clone -b 1.0.61 https://github.com/fastai/fastai1.git # step 2 cd fastai python.exe tools/run-after-git-clone # step 3 pip install -e ".[dev]"
- 第一个,拉取1.0.61版本的代码:
- 2019的coursev3 notebook是要使用fastai1.0.61的版本差不多
第三步后如下: (要装很久的依赖!!)

debug效果测试
这就进入到了fastai的源码中去调试啦!!! (*^▽^*)

0.1 fastai course 2018 fastai1 docker构建(失败)
由于使用的jupyter notebook是fastai0.7.x的环境,目前已经弃用了。
找到一个docker文件,GitHub - anurag/fastai-course-1: Docker environment for fast.ai Deep Learning Course 1 at http://course.fast.ai
但是其dockerfile有很多问题,修改如下:
① 源的问题:Err:11 https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64 Packages 404 No_lgyuWT的博客-CSDN博客
将第一行改为:
FROM nvidia/cuda:8.0-cudnn5-devel-ubuntu16.04
RUN rm /etc/apt/sources.list.d/cuda.list
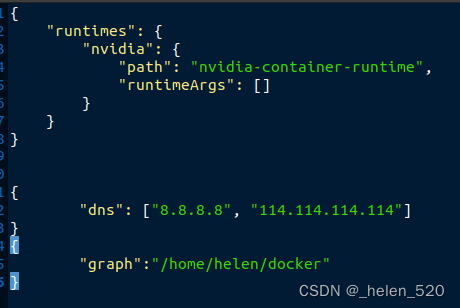
② apt-get update失效,因为dns的原因,需要将
解决办法:更改 /etc/docker/daemon.json
![]()
# 添加如下部分
{
"dns": ["8.8.8.8", "114.114.114.114"]
}
# 回到终端,重启docker
sudo service docker restartconda国内源:(linux)
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirror.nju.edu.cn/pub/anaconda/cloud/pytorch-test/linux-64/
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
- https://mirrors.aliyun.com/anaconda/pkgs/free/
- https://mirrors.aliyun.com/anaconda/pkgs/main/
- https://pypi.doubanio.com/simple/
- defaults
show_channel_urls: true③ 修改源为本地源:
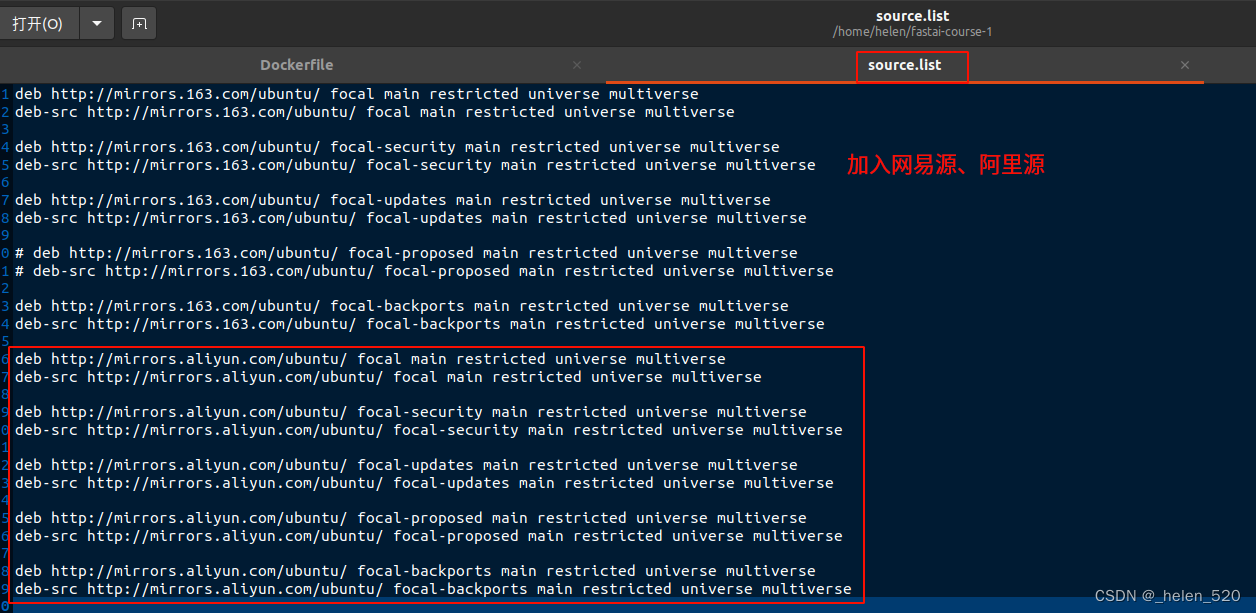
在Dockerfile中切换为本地源
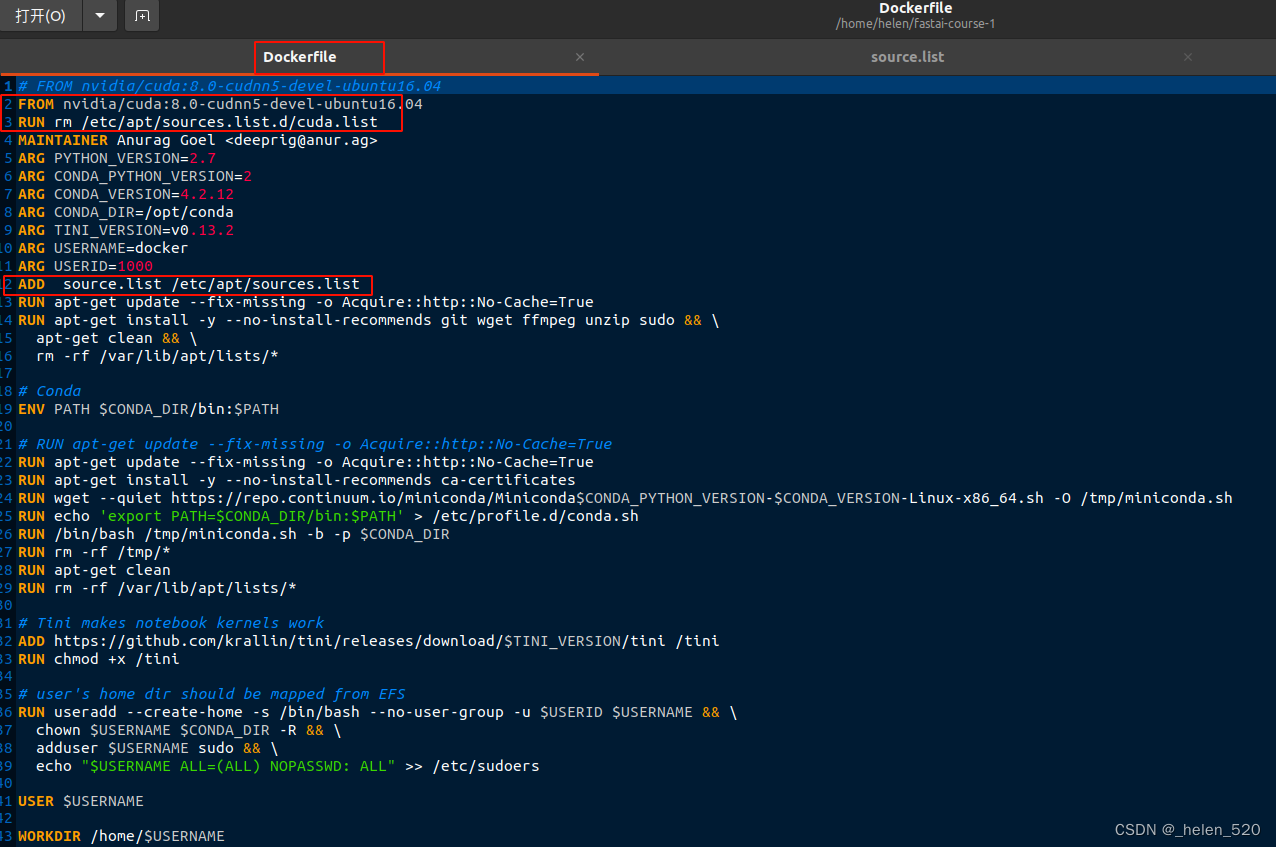
执行docker从Dockerfile构建镜像:
docker build -f Dockerfile -t fastai1 .Dockerfile文件修改如下:
FROM nvidia/cuda:8.0-cudnn5-devel-ubuntu16.04
RUN rm /etc/apt/sources.list.d/cuda.list
MAINTAINER Anurag Goel <deeprig@anur.ag>
ARG PYTHON_VERSION=2.7
ARG CONDA_PYTHON_VERSION=2
ARG CONDA_VERSION=4.2.12
ARG CONDA_DIR=/opt/conda
ARG TINI_VERSION=v0.13.2
ARG USERNAME=docker
ARG USERID=1000
RUN apt-get update && \
apt-get install -y --no-install-recommends git wget ffmpeg unzip sudo && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# Conda
ENV PATH $CONDA_DIR/bin:$PATH
RUN apt-get update && apt-get install -y --no-install-recommends ca-certificates && \
wget --quiet https://repo.continuum.io/miniconda/Miniconda$CONDA_PYTHON_VERSION-$CONDA_VERSION-Linux-x86_64.sh -O /tmp/miniconda.sh && \
echo 'export PATH=$CONDA_DIR/bin:$PATH' > /etc/profile.d/conda.sh && \
/bin/bash /tmp/miniconda.sh -b -p $CONDA_DIR && \
rm -rf /tmp/* && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# Tini makes notebook kernels work
ADD https://github.com/krallin/tini/releases/download/$TINI_VERSION/tini /tini
RUN chmod +x /tini
# user's home dir should be mapped from EFS
RUN useradd --create-home -s /bin/bash --no-user-group -u $USERID $USERNAME && \
chown $USERNAME $CONDA_DIR -R && \
adduser $USERNAME sudo && \
echo "$USERNAME ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
USER $USERNAME
WORKDIR /home/$USERNAME
COPY .theanorc .
COPY keras.json .keras/
COPY jupyter_notebook_config.py .jupyter/
RUN conda install -y --quiet python=$PYTHON_VERSION && \
conda install -y --quiet notebook h5py Pillow ipywidgets scikit-learn \
matplotlib pandas bcolz sympy scikit-image mkl-service && \
pip install --upgrade pip --ignore-installed && \
pip install tensorflow-gpu kaggle-cli --ignore-installed && \
pip install git+git://github.com/fchollet/keras.git@1.1.2 --ignore-installed && \
conda clean -tipsy
ENV CUDA_HOME=/usr/local/cuda
ENV CUDA_ROOT=$CUDA_HOME
ENV PATH=$PATH:$CUDA_ROOT/bin:$HOME/bin
ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CUDA_ROOT/lib64
# Jupyter
EXPOSE 8888
# Clone fast.ai source
RUN git clone -q https://github.com/fastai/courses.git fastai-courses
WORKDIR /home/$USERNAME/fastai-courses/deeplearning1/nbs
ENTRYPOINT ["/tini", "--"]
CMD jupyter notebook --ip=0.0.0.0 --port=88880.2 fastai course 2018 fastai1 docker构建 (成功)
Docker Hub docker镜像拉取:fastai course v1
git clone https://github.com/fastai/fastai1.git一、lesson1_pets.py
# demo1: 使用fastai库训练 part1
from fastai.vision import *
from fastai.metrics import error_rate
bs = 16
path = '/local_data/dataset/oxford-iiit-pet/'
path_anno = path+'annotations'
path_img = path+'images'
fnames = get_image_files(path_img)
np.random.seed(2)
pat = r'/([^/]+)_\d+.jpg$'
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs
).normalize(imagenet_stats)
data.show_batch(rows=3, figsize=(7,6))
print(data.classes)
len(data.classes),data.c
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
model_summary(learn.model, data, print_mod=False)
learn.model
learn.fit_one_cycle(4)
# demo2:使用fastai part2课程的自己从头建的模块实现
# code在2080ti机器中
from exp.nb_08 import *
import numpy as np
path = '/dataset_zhr/oxford-iiit-pet/'
# 没加resize,导致后面的dataloader取不到一个batch的数据
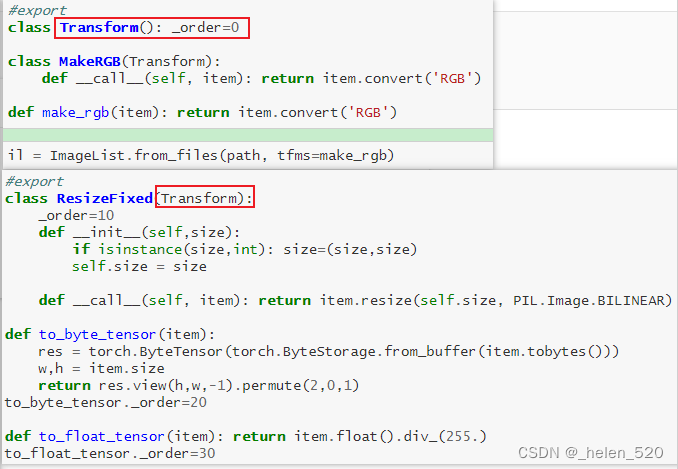
tfms = [make_rgb, ResizeFixed(128), to_byte_tensor, to_float_tensor]
il = ImageList.from_files(path_img, tfms=tfms)
np.random.seed(2)
# 分割验证集和训练集:随机分割改
# 调试这段代码的时候,需要修改nb_08.py split_by_func的一行代码,mask=f(len(items))
def split_by_rand_pct(valid_pct:float=0.2, seed:int=None, len_list:int=None):
if valid_pct==0: valid_pct = 0.2
if seed is not None: np.random.seed(seed)
rand_idx = np.random.permutation(range(len_list))
cut = int(valid_pct * len_list)
# 验证集的索引
mask = np.zeros(len_list, dtype=bool)
mask[rand_idx[:cut]] = True
return mask
# 把随机分割训练集和验证集的做好了
splitter = partial(split_by_rand_pct, 0.2, 2)
# splitter = partial(grandparent_splitter, valid_name='val')
sd = SplitData.split_by_func(il, splitter)
pat = r'/([^/]+)_\d+.jpg$'
pat_label = partial(pat_labeler, pat)
ll = label_by_func(sd, pat_label, proc_y=CategoryProcessor())
# 获取databunch
bs = 16
train_dl, valid_dl = get_dls(ll.train, ll.valid, bs, num_workers=4)
x,y = next(iter(train_dl))
SplitData.to_databunch = databunchify
data = ll.to_databunch(bs, c_in=3, c_out=37, num_workers=16)
cbfs = [partial(AvgStatsCallback, accuracy), CudaCallback, Recorder]
# 如果自己搭建网络的话,看看效果咋样?怎么才能跟上fastai的结果?这是一个路子
# 从零开始搭建,然后慢慢提升。而不是一下子吃成一个胖子
# m,s = x.mean((0,2,3)).cuda(), x.std((0,2,3)).cuda()
# 使用一个batch的值
m,s = x.mean((0,2,3)).cuda(),x.std((0,2,3)).cuda()
norm_pets = partial(normalize_chan, mean=m.cuda(), std=s.cuda())
cbfs.append(partial(BatchTransformXCallback, norm_pets))
nfs = [64,64,128,256]
sched = combine_scheds([0.3,0.7], cos_1cycle_anneal(0.1, 0.3, 0.05))
# (0.1,0.3,0.05)
# train: [3.6302977524526385, tensor(0.0347, device='cuda:0')]
# valid: [3.6257538956782813, tensor(0.0325, device='cuda:0')]
# train: [3.53294676082544, tensor(0.0641, device='cuda:0')]
# valid: [3.57637405911705, tensor(0.0568, device='cuda:0')]
# train: [3.386827770847429, tensor(0.1189, device='cuda:0')]
# valid: [3.5074616510910013, tensor(0.0670, device='cuda:0')]
# train: [3.2607960371913056, tensor(0.1583, device='cuda:0')]
# valid: [3.468038391195873, tensor(0.0819, device='cuda:0')]
# train: [3.180710313768606, tensor(0.1900, device='cuda:0')]
# valid: [3.458785494544993, tensor(0.0839, device='cuda:0')]
# lr
learn,run = get_learn_run(nfs, data, 0.2, conv_layer,
cbs=cbfs+[partial(ParamScheduler, 'lr', sched)], opt_func=optim.SGD)
# model_summary(run, learn, data)
run.fit(5, learn)
run.recorder.plot_loss()
# run.recorder.plot_lr()
# ll.train.proc_y.vocab
# learn.model(ll.train[0][0])
1. 参考part2的lesson11的Data block API foundations 配合理解 get_image_files
用mini-batch小批量将数据读入RAM,数据集太大,不能一次性的放入到RAM中,需要分批次小批量在使用的时候再读入数据。
c='/local_data/dataset/oxford-iiit-pet/images' ;
extensions有42种数据格式。{'.tif', '.art', '.nef', '.svg', '.png', '.ppm', '.djvu', '.jpf', '.cdt', '.orf', '.jpe', '.djv', '.ras', '.pcx', ...}
遍历文件夹,并grab all the images抓取所有的图像。
- scandir比glob速度快多了,使用的是python中的C API;获取13000个文件名,需要70ms,而windows中查看13000个文件需要4分钟。
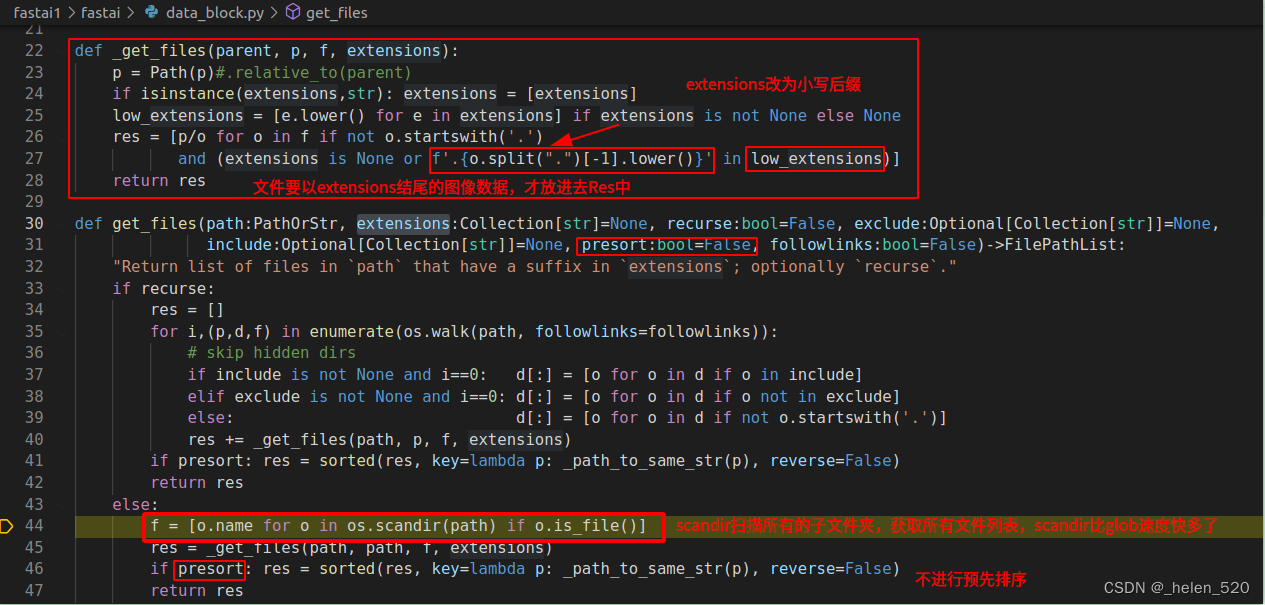
len(f)=7393个图像数据,共37个类别;每个类别大概200张图像。len(res)=7390.
2. 构建ImageDataBunch(参考lesson11 data api)
参考:fastai lesson11 notebook调试学习笔记__helen_520的博客-CSDN博客
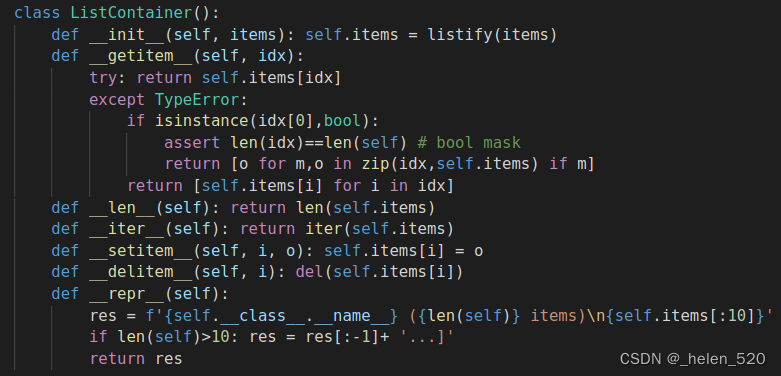
在Data block API中,ListContainer->ItemList->ImageList
- __init__构造函数,双下划线函数。
- __call__,调用类名的函数时,就去调用call这个函数了。
- 调用cls(),本类的构造函数;Python super() 函数 | 菜鸟教程
super() 函数是调用父类(超类super类)的一个方法,解决多重继承的问题,直接用类名调用父类方法在单继承的时候没问题,但使用多继承时会涉及到查找顺序MRO、重复调用等种种问题 - classmethod用的是cls,类方法,默认使用的第一个参数是cls;
- 实例方法中,一般使用self作为第一个参数。
- MRO就是类的方法解析顺序表,继承父类方法是的顺序表。
【python基础笔记-2】cls含义及使用方法 - 偷月 - 博客园
- staticmethod静态函数,可以通过类名访问,也可以通过实例来访问
- 常规函数,只能通过实例来调用
- classmethod类方法,cls作为第一个参数;类方法只与类本身有关,与实例无关;可以通过实例化来调用,也可以通过类名来调用。
- 第三点是关于cls(),其实这就是类本身,比如这里的cls()=A,如果cls()里面有参数,那么这个参数就是构造函数init(self,parameter1,parameter2)中的参数1,2,同时还是表示类本身。
class A(object):
a='a'
@staticmethod
def foo1(name):#静态函数
print("hello",hello)
def foo2(self,name):#常规函数
print("hello",name)
@classmethod
def foo3(cls,name):#类方法
print("hello",name)
#接着我们实例化A类,
a=A()
print(a.foo1('ma'))#output:hello ma
print(A.foo1('ma'))#output:hello ma
#而foo2是常规函数,只能通过类的实例化来调用,即a.foo2()来调用。
# 而foo3是类函数,cls作为第一个参数用来表示类本身,在类方法中用到,类方法只是与类本身有关而与实例无关的方法。可以通过实例化来调用,也可以通过类名.类函数名来调用。即a.foo3('mam')或A.foo3('mam')
# (2)staticmethod和classmethod方法的区别
# 在classmethod中可以调用类中定义的其他方法、类的属性,但staticmethod只能通过A.a调用类的属性,但无法通过在该函数内部调用A.foo2()。
class A(object):
a = 'a'
@staticmethod
def foo1(name):
print 'hello', name
print A.a # 正常
print A.foo2('mamq') # 报错: unbound method foo2() must be called with A instance as first argument (got str instance instead)
def foo2(self, name):
print 'hello', name
@classmethod
def foo3(cls, name):
print 'hello', name
print A.a
print cls().foo2(name)#可以在foo3中调用foo2,因为持有cls参数,彷佛是类本身,故可以调用该foo2方法。
# 第三点是关于cls(),其实这就是类本身,比如这里的cls()=A,如果cls()里面有参数,那么这个参数就是构造函数init(self,parameter1,parameter2)中的参数1,2,同时还是表示类本身。
- ImageList通过get_files获取了前面的文件列表;
① 派生类调用父类的构造函数cls来调用的;self.path, self.tfms
② 父类又通过super去调用爷类的构造函数; self.items
`il = ImageList.from_files(path_img, tfms=tfms)` il的构造函数,实际上去建立了ItemList的对象,ImageList的构造函数没有什么有用的成员变量。
self.path, self.tfms是ItemList的成员变量;self.items是ListContainer的成员变量。
用type()可以查看数据的类型;items是list类型的对象;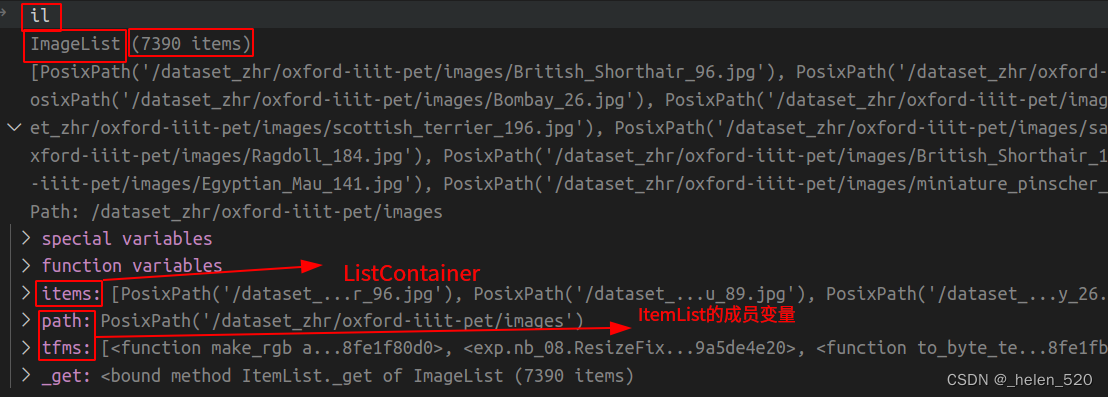
- SplitData通过split_by_func函数,
① il具有ItemList的new方法;new的内容是,cls(items, path, tfms)即调用了本类当前类的构造函数;新的构造函数,new就是新建一个对象给lists。
② 建立的lists是两个new的ItemList类型的数据,分别是train和valid,且lists的类是ItemList类别的。
③ 然后用SplitData的cls(*lists)给包装成了SplitData类的对象了。 - 打标签label:Processor
① compose的概念:函数的链式法则,将函数列表组成一个管道,依次执行。x=f(g(h(x))))
② 将process_y的标签给做成数字;并准备好查表vocab - 将labelList转为databunch格式
① ll是LableList类型,但其中的sd是SplitData类型,且sd有两个数据集,valid,train。
② get_dls是返回DataLoader(torch的函数接口)的对象;
③ 创建了DataBunch类,为了加入c_in,c_out属性,方便以后的建模型。
④ 给SplitData添加一个to_databunch函数。
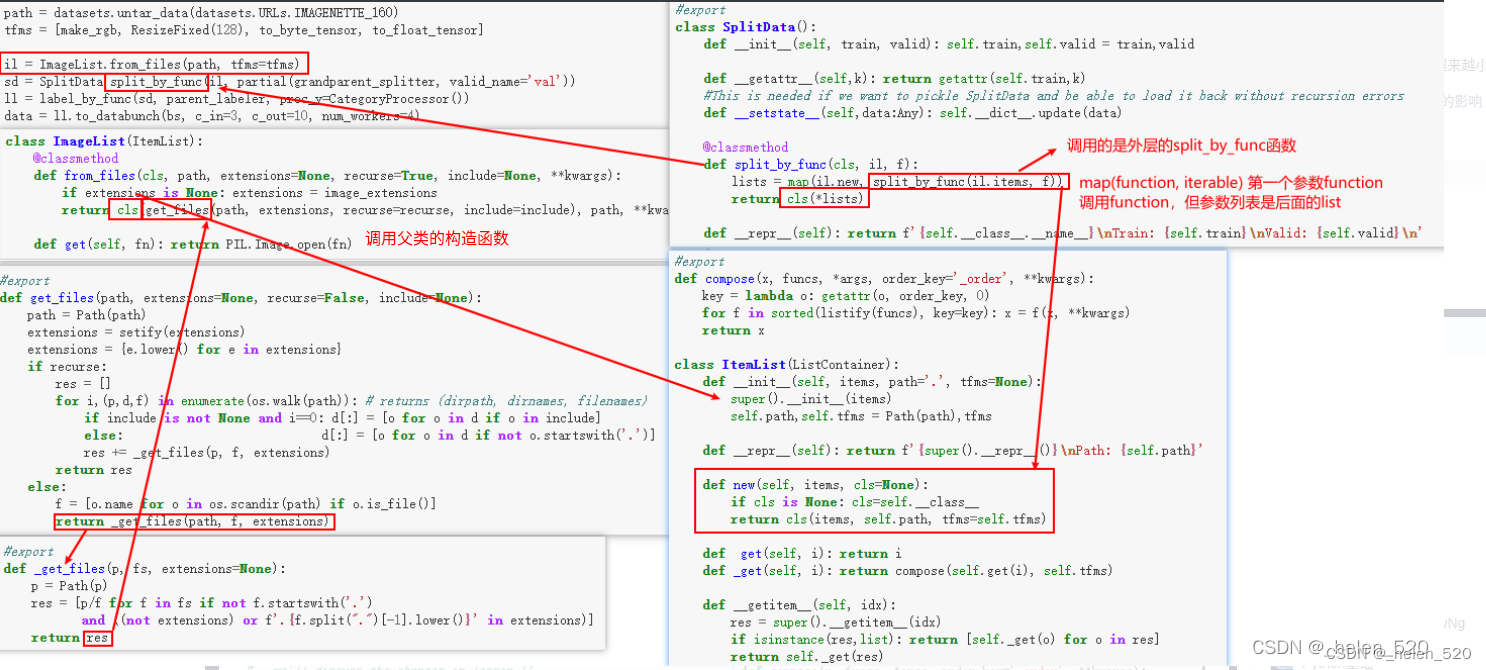
如何对数据进行Transform操作的!!!

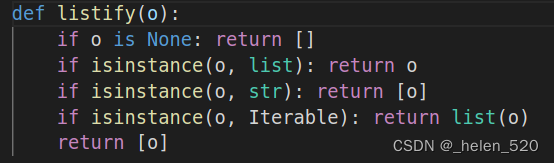
 listify()
listify()
3. learner_runner
参考:lesson9 How to train your model notes
- 思维导图 fastai 2019 lesson1~lesson12
- fastai 2019 lesson9 notes 笔记__helen_520的博客-CSDN博客
- https://github.com/HaronCHou/fastai-notes fastai notes 中文笔记合集
- fastai jupyter notebook 在线预览:https://nbviewer.org/github/fastai/course-v3/tree/master/nbs/dl2/
4. Normalization 归一化
为什么需要归一化?归一化的好处是什么?归一化之前和之后的变化是什么?
附录:python 基础知识补充
学习《python编程:从入门到实践》
- linux terminal:Ctrl+Alt+T
- Geany编辑器是作者推荐的;里面也还是有compile、make、execute的命令指令过程
- compile:python -m py_copile "%f"
- excute: python "%f"
- Python中下划线的5种含义 - 知乎 名称修饰:name mangling
- 单下划线,双下划线(dunder)
- 函数单下划线:_internel_func在import的时候,使用通配符导入python不会导入_internel_func函数。
- 如果是常规导入,import XXXX;————与通配符导入不同,常规导入不受前导单个下划线命名约定的影响:
- 使用通配符导入:from XXX import * ————应该避免通配符导入,因为它们使名称空间中存在哪些名称不清楚。 为了清楚起见,坚持常规导入更好。
- 单个下划线是一个Python命名约定,表示这个名称是供内部使用的。 它通常不由Python解释器强制执行,仅仅作为一种对程序员的提示。
- 双前导下划线 __var
- self.__baz是为了防止变量在子类中被重写。
- 父类为:_Test__baz;继承的子类中为_ExtendTest__baz;且子类对象还有_Test__baz成员变量。
-
双前导和双末尾下划线 _var_
-
如果一个名字同时以双下划线开始和结束,则不会应用名称修饰。
-
但是,Python保留了有双前导和双末尾下划线的名称,用于特殊用途。 这样的例子有,__init__对象构造函数,或__call__ --- 它使得一个对象可以被调用。
-
这些dunder方法通常被称为神奇方法 - 但Python社区中的许多人(包括我自己)都不喜欢这种方法。
-
最好避免在自己的程序中使用以双下划线(“dunders”)开头和结尾的名称,以避免与将来Python语言的变化产生冲突。
-
一、python
Python中类-带括号与不带括号的区别(通俗易懂)_无梦生7的博客-CSDN博客_python类名加括号是什么意思
- id() 函数用于获取对象的内存地址。
- 不带括号的类:等同于赋值——赋值是给地址;
- b = Tea(),b是Tea实例化的一个对象了。
- python 类 -
带括号是实例化,不带括号是赋值。 - 本节再介绍 Python 类中一个非常特殊的实例方法,即 __call__()。该方法的功能类似于在类中重载 () 运算符,使得类实例对象可以像调用普通函数那样,以“对象名()”的形式使用。
- call就相当于重载了括号()运算法;对象名()的形式使用。调用的是哪一个函数呢?
- 《python核心编程》chap14 可调用对象。
- BIF built-in-functions/method 内建函数/方法
-
记住只有定义类的时候实现了__call__方法,类的实例才能成为可调用的
-
python 给类提供了名为__call__的特别方法,该方法允许程序员创建可调用的对象(实例)。默认情况下,__call__()方法是没有实现的,这意味着大多数实例都是不可调用的。
- 然而,如果在类定义中覆盖了这个方法,那么这个类的实例就成为可调用的了。调用这样的实例对象等同于调用__call__()方法
-















 2153
2153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









