







lesson8 deep learnin from the foundations 从基础开始
- Jupyter notebook:
- 01_matmul.ipynb
- 02_fully_connected.ipynb 主要是计算前向传播、反向传播、抽象基类重构,与nn.Module类的效果相比较。
- lesson8 notes :https://github.com/HaronCHou/deeplearning-assignment/blob/master/lesson8/lesson8.md
lesson9 How to train your model
- Jupyter notebook:
- 02a_why_sqrt5.ipynb 02b_initializing.ipynb 02a_why_sqrt5.ipynb
- pytorch的Convd对weight的权重初始化为sqrt5。经过4层卷积层conv后,前向传播后的方差变小;
反向传播回来的梯度方差也很小;梯度方差小,那么weight梯度下降的更新就小,网络就训练不动。 - ① why good init? 为什么初始化如此重要?为什么是这么一个神奇的sqrt(1/m), sqrt(2/m) for relu? 做个计算就是这样的结果!
- ps: pytorch中的nn.weight的shape是转置了的,反正就是一个历史问题,历史原因,导致在做卷积的时候,使用的是weight.t();知道这个就可以了。
- pytorch的Convd对weight的权重初始化为sqrt5。经过4层卷积层conv后,前向传播后的方差变小;
- 03_minibatch_training.ipynb
- ② 损失函数:MSE(回归任务的代价函数)、cross entropy交叉熵(分类任务的代价函数)
- softmax的pytorch实现
- ③ Basic training loop:
- module的重构:setattr、repr的实现;pytorch的sequential类都实现了。
- Optim类的zero_grad和step分离;
- Dataloader和Dataset、random shuffle随机打乱。
- 每个epoch计算validset的loss和acc,准备train和valid时的某些层的差异。
- ② 损失函数:MSE(回归任务的代价函数)、cross entropy交叉熵(分类任务的代价函数)
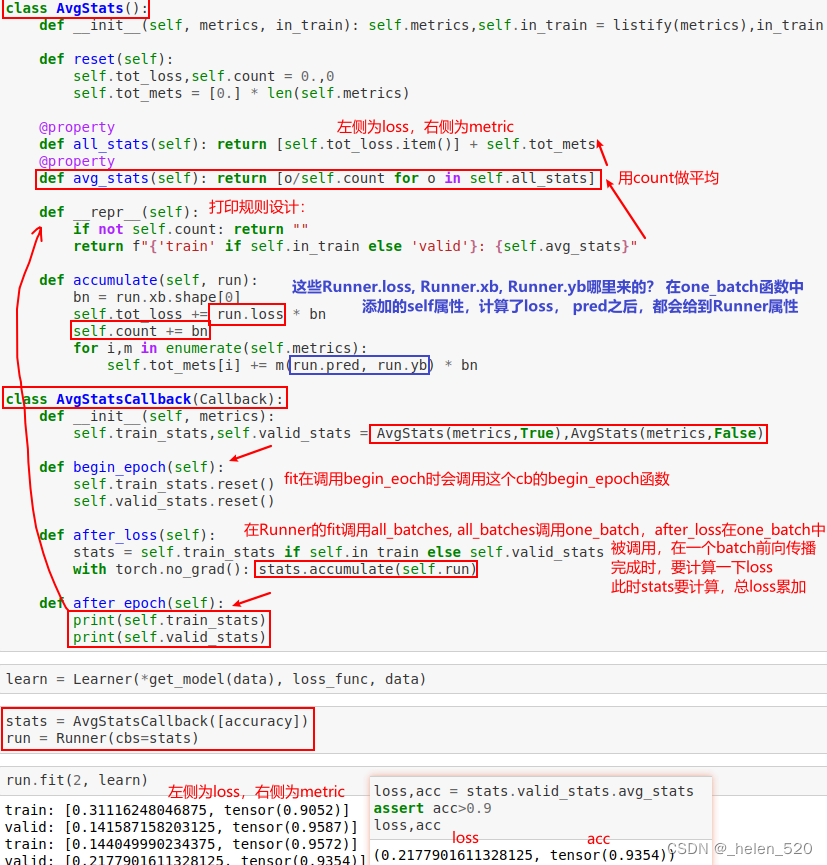
- 04_callbacks.ipynb 回调函数的设计——更多的是软件工程方面的内容
- CallbackHandler和Callback函数的调用逻辑。
- 将fit、all_batches、one_batch都合并在一个Runner类中
- Runner重新设计的好处是:callback变成一个随意的基类,大家靠相同的函数名称method去调用(函数名不能变,必须一模一样)。
- 然后靠callback的Oder决定调用顺序。不同功能的callback对象一定有同样功能的method。method的总量有那么多,但可以在不同功能中有差异,然后按照调用顺序来调用。
- 解决了两个问题,① 什么时候调用?(同一时刻就是调用同样的函数) ② 同样的函数可以实现不同的功能 ③ 不同的功能通过order先后次序来调用了。
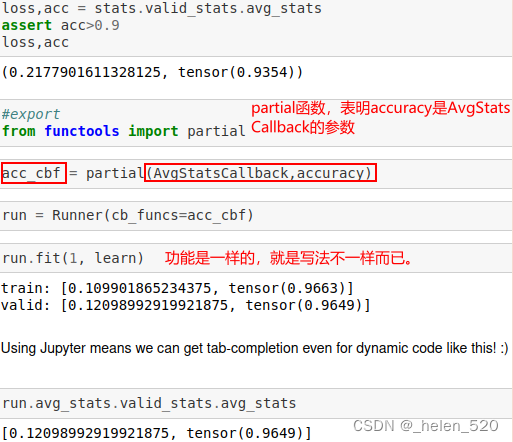
- 演示了AvgStatsCallback的使用。
- 05_anneal.ipynb fastai库如何完成学习率退火 learning rate annealing
- 02a_why_sqrt5.ipynb 02b_initializing.ipynb 02a_why_sqrt5.ipynb
0. 前言
- 从基础开始:学习实现fastai和pytorch库的功能。学习构建库的一些方法。
- 重写fastai和pytorch的很多函数:矩阵惩罚、torch.nn,torch.optim,dataloader等
- 深度学习的前言其实是工程上的,而不只是论文。深度学习领域里,优秀的人更有效率,就是他们能用代码做出有用的东西。part2的目的就是让代码能够work。
- why foudations?为什么要从基础开始学习呢?
① 需要真实的实践:了解模型在干什么?训练中真正在发生一些什么?
② understand by creating it。以重构的方式来理解,以debug的方式来理解。 - modern CNN model的步骤
- ① 矩阵乘法
- ② Relu/初始化
- ③ 前向传播
- ④ 反向传播
- ⑤ train loop 训练循环
- ⑥ conv卷积层
- ⑦ 优化 Optim
- ⑧ 批归一化 batch normalization
- ⑨ Resnet
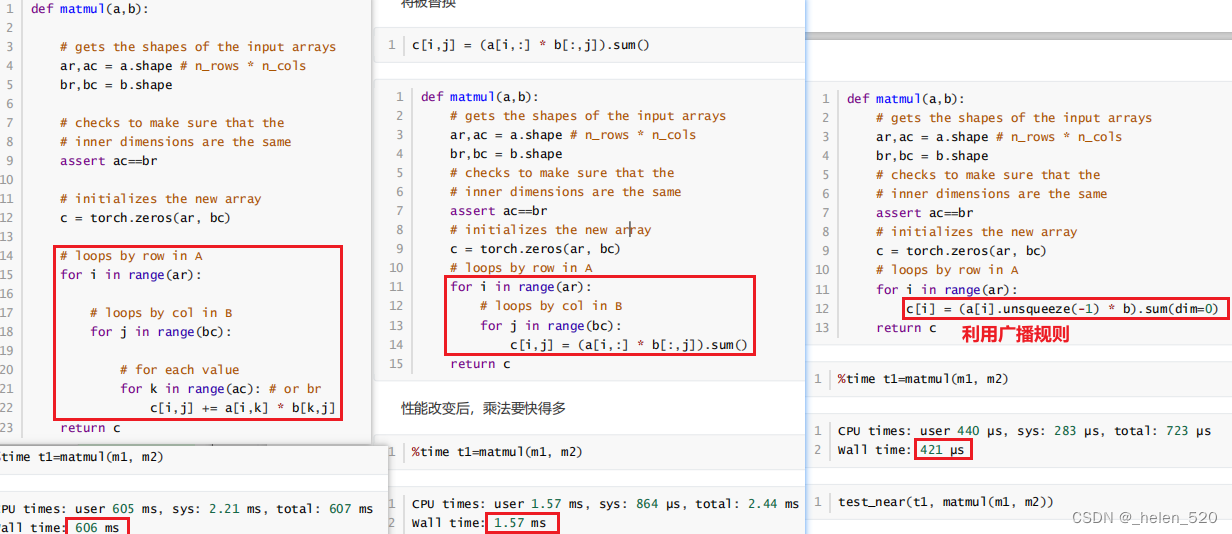
① 矩阵乘法
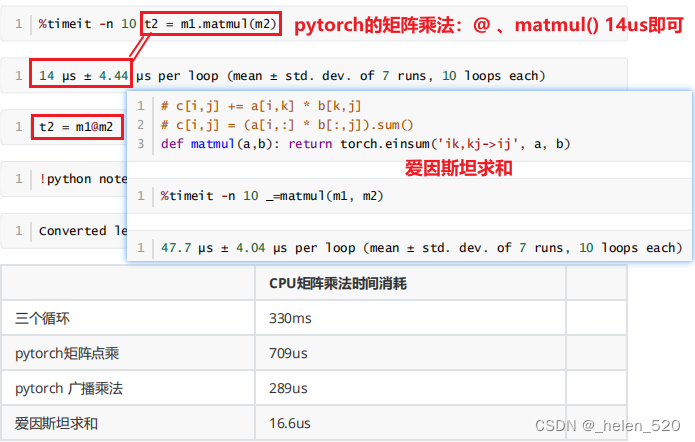
- 第二个使用了pytorch的点乘,利用了torch的点乘;大大加快了速度。
- dim(0)是沿着行;unsqueeze(-1)是沿着列广播;
- pytorch的矩阵乘法是最快的;
m1 = x_valid[:5]
m2 = weights
m1.shape, m2.shape
# (torch.Size([5, 784]), torch.Size([784, 10]))
② Relu/初始化——来源于何凯明的ImageNet比赛获奖paper,ReLU、Resnet、kaiming归一化等
第一个简单模型:y=(x*w1+b1)*w2 + b2
- 非卷积层,简单的线性层;sqrt(2/m)*uniform,ReLU(x*w1+b1)后,均值为0.5,方差0.8;
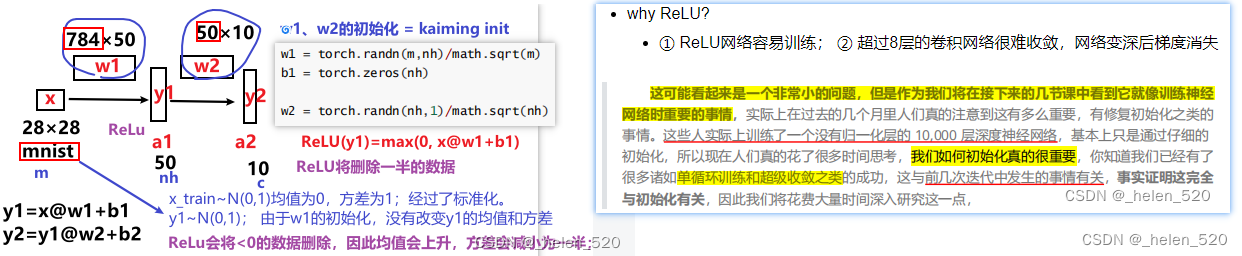
A。why ReLU?
- ① ReLU网络容易训练; ② 超过8层的卷积网络很难收敛,网络变深后梯度消失
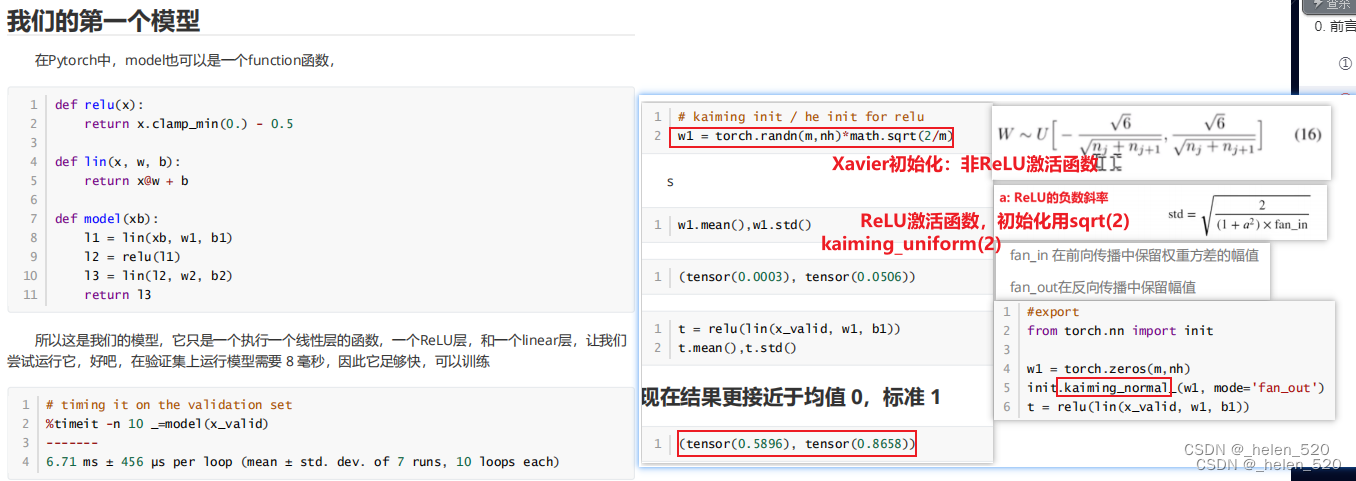
为什么需要一个好的初始化?why a good init? lesson 9
- fastai 2019 lesson9 notes 笔记__helen_520的博客-CSDN博客
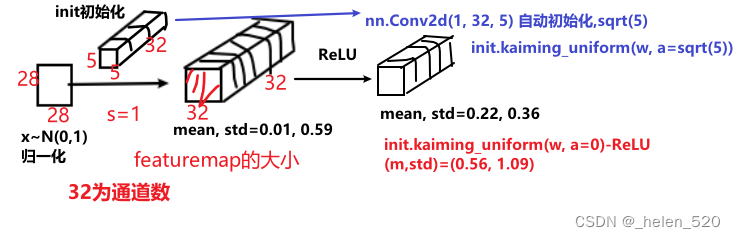
- torch.Conv2d对l1的初始化,是sqrt(5);x经过l1卷积后,均值方差变化了。
- l1.weight == torch.Size([32, 1, 5, 5]) 怎么看待这个滤波器?
- Conv2d的sqrt(5)初始化,让x没经过一次卷积层,方差都减小了;经过4层卷积层后,方差只有0.06了。梯度消失了!!!!
- 怎么样是一个好的初始化?为什么呢?
- D(X)=E(X^2) - E(X)^2。
- E((XY)^2)
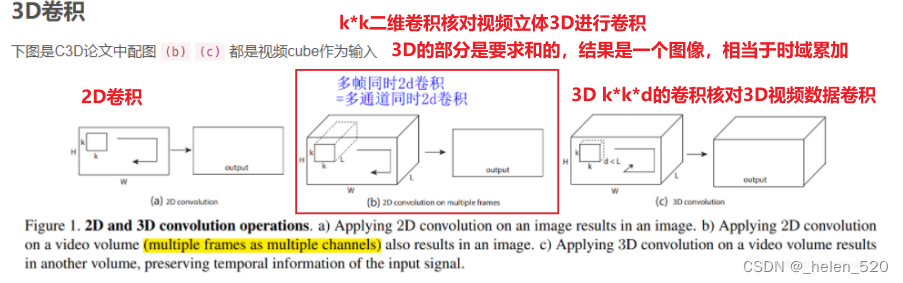
3D卷积的计算方式如下所示:
def get_data():
path = Path('/dataset_zhr/lesson5-sgd-mnist/MNIST dataset/mnist.pkl.gz')
with gzip.open(path, 'rb') as f:
((x_train, y_train),(x_valid, y_valid), _) = pickle.load(f, encoding='latin-1')
return map(tensor, (x_train, y_train, x_valid, y_valid)) # 映射为tensor格式
def normalize(x, m, x): return (x-m)/s
# 数据预处理,归一化
x_train, y_train, x_valid, y_valid = get_data() # torch.Size([50000, 784])
train_mean, train_std = x_train.mean(), x_train.std()
x_train = normalize(x_train, train_mean, train_std)
x_valid = normalize(x_valid, train_mean, train_std) # 用train训练集的均值和标准差来归一化valid验证集
x_train = x_train.view(-1, 1, 28, 28)
x_valid = x_valid.view(-1, 1, 28, 28)
x_train.shape # torch.Size([50000, 1, 28, 28])
n, *_ = x_train.shape
c = y_train.max() + 1 # torch.tensor格式,tensor有很多函数,max(), min(), len(y), y.mean等函数都可以直接调用的,具体参考torch.tensor
nh= 50 # num of hidden layers 一个隐藏层
l1 = nn.Conv2d(1, nh, 5) # Conv2d(1, 32, kernel_size=(5,5), stride=(1,1))
l1.weight.shape # torch.Size([50, 1, 5, 5])
t = l1(x) # 输入经过卷积层之后的结果
stats(t)
----------
(tensor(0.0107, grad_fn=<MeanBackward1>),
tensor(0.5978, grad_fn=<StdBackward0>))
- x为一张图片时,经过5*5*8的卷积 层时,是每一个5*5与x卷积,得到featuremap;然后8个卷积核,就得到featuremap的切片为8;
- 14*14*8的featuremap再经过下一个卷积层时,又是如何计算的呢?
- 拿一个3*3去对14*14*8的卷积核,进行卷积,此时,就是把8的部分都乘起来,再相加。
- 这就是3D卷积的做法!!!
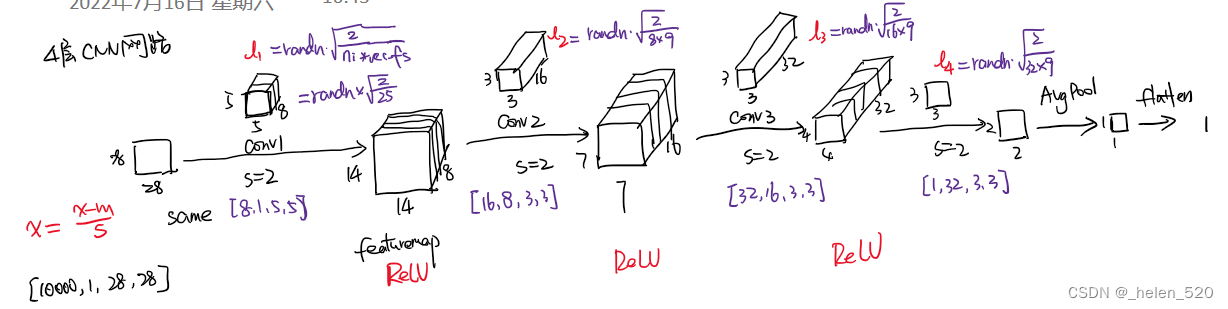
- 4层CNN网络如图所示,正向传播后,x的方差下降的很厉害;
- 误差在反向传播时,grad在m[0]处几乎为0,梯度没有什么变化,梯度消失了。
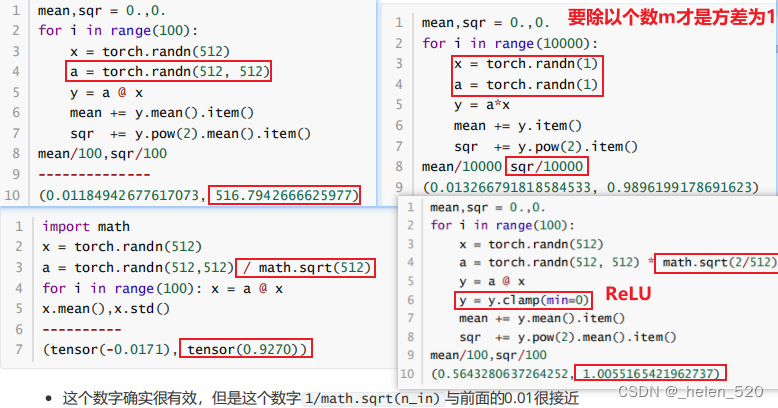
- 为什么要sqrt(/m)?ReLU为啥是sqrt(2/m)? scaling的神奇数字。
- 从数学上证明,只要 a 中和 x 中的元素是独立的,均值是 0,std 是 1。
- a*x相乘,m个ax的乘积的和,要除以m,才能保证均值为1;
- 也就是让a在初始化的时候乘以 sqrt(1/m);
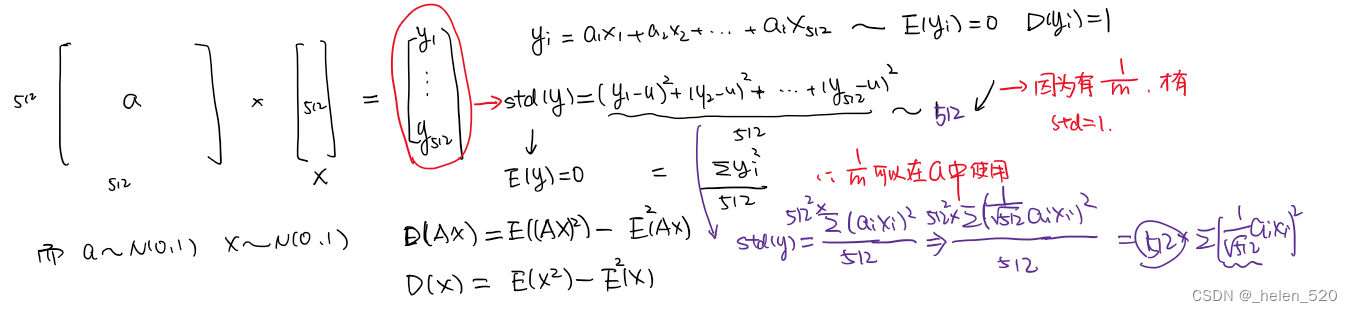
#export
from exp.nb_02 import *
def get_data():
# path = datasets.download_data(MNIST_URL, ext='.gz')
path = Path('/dataset_zhr/lesson5-sgd-mnist/MNIST dataset/mnist.pkl.gz')
with gzip.open(path, 'rb') as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding='latin-1')
return map(tensor, (x_train,y_train,x_valid,y_valid))
def normalize(x, m, s): return (x-m)/s
x_train,y_train,x_valid,y_valid = get_data() # # torch.Size([50000, 784])
train_mean,train_std = x_train.mean(),x_train.std()
x_train = normalize(x_train, train_mean, train_std)
# NB: Use training, not validation mean for validation set
x_valid = normalize(x_valid, train_mean, train_std)
n,m,*_ = x_train.shape
c = y_train.max()+1
""" 一、线性层测试:l1->Relu->l2(10) 一个线性隐藏层(非卷积层)
"""
nh = 50
w1 = torch.randn(m,nh)/math.sqrt(m) # 线性层的初始化方式:Xavier初始化
b1 = torch.zeros(nh)
w2 = torch.randn(nh,1)/math.sqrt(nh)
b2 = torch.zeros(1)
# 状态函数
def stats(x): return x.mean(), x.std()
def lin(x, w, b): return x@w + b
def relu(x): return x.clamp_min(0.)
t = lin(x_valid, w1, b1)
stats(t) # (tensor(0.0988), tensor(1.0425))
stats(relu(t)) # (tensor(0.4659), tensor(0.6480))
# ① ReLU用sqrt(2)初始化,方差保持1
w1 = torch.randn(m,nh)*math.sqrt(2/m)
stats(relu(lin(x_valid, w1, b1))) # (tensor(0.5844), tensor(0.8691))
""" 二、卷积层的初始化影响:kaiming初始化参数的影响
"""
x_train = x_train.view(-1,1,28,28)
x_valid = x_valid.view(-1,1,28,28)
from torch import nn
nh = 32
l1 = nn.Conv2d(1, nh, 5)
stats(l1.weight)
stats(l1(x_valid)) # (tensor(-0.0300, grad...ackward0>), tensor(0.6502, grad_...ackward0>))
""" l1是torch.nn.modules.conv.Conv2d,类本身有__call__函数,所以对象名+括号,l1()直接调用了__call__函数
- __call__在Module类中定义了。即在爷类中定义的call函数
"""
import torch.nn.functional as F
def f1(x, a=0):
return F.leaky_relu(l1(x), a)
# pytorch自定义初始化
stats(f1(x_valid)) # (tensor(0.2334, grad_...ackward0>), tensor(0.4282, grad_...ackward0>))
from torch.nn import init
# kaiming初始化
init.kaiming_uniform_(l1.weight, a=0, mode='fan_in')
stats(f1(x_valid)) # (tensor(0.5017, grad_...ackward0>), tensor(0.8888, grad_...ackward0>))
# receptive field size
rec_fs = l1.weight[0,0].numel() # 5*5
nf,ni,*_ = l1.weight.shape # torch.Size([32, 1, 5, 5])
fan_in = ni*rec_fs
fan_out = nf*rec_fs
def gain(a): return math.sqrt(2.0 / (1 + a**2))
def kaiming2(x,a, use_fan_out=False):
nf,ni,*_ = x.shape
rec_fs = x[0,0].shape.numel()
fan = nf*rec_fs if use_fan_out else ni*rec_fs
std = gain(a) / math.sqrt(fan)
bound = math.sqrt(3.) * std
x.data.uniform_(-bound,bound)
kaiming2(l1.weight, a=0)
stats(f1(x_valid)) # tensor(0.5790, grad_...ackward0>), tensor(1.1068, grad_...ackward0>))
"""
三、四个卷积层,初始化不当导致反向传播时梯度消失
"""
class Flatten(nn.Module):
def forward(self,x): return x.view(-1)
"""
m
Sequential(
(0): Conv2d(1, 8, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2))
(1): ReLU()
(2): Conv2d(8, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(3): ReLU()
(4): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(5): ReLU()
(6): Conv2d(32, 1, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(7): AdaptiveAvgPool2d(output_size=1)
(8): Flatten()
)
"""
m = nn.Sequential(
nn.Conv2d(1, 8, 5,stride=2,padding=2), nn.ReLU(), # torch.Size([100, 8, 14, 14])
nn.Conv2d(8, 16, 3,stride=2,padding=1), nn.ReLU(), # torch.Size([100, 16, 7, 7])
nn.Conv2d(16, 32, 3,stride=2,padding=1), nn.ReLU(),# torch.Size([100, 32, 4, 4])
nn.Conv2d(32, 1, 3,stride=2,padding=1), # torch.Size([100, 1, 2, 2])
nn.AdaptiveAvgPool2d(1), # torch.Size([100, 1, 1, 1])
Flatten(), # torch.Size([100])
)
t = m(x_valid)
stats(t)
zz = m[1](x_train); print(stats(zz))
# (tensor(0.3480), tensor(0.8555))
zz = m[3](x_train); print(stats(zz))
# (tensor(0.3480), tensor(0.8555))
zz = m[5](x_train); print(stats(zz))
# (tensor(0.3480), tensor(0.8555))
zz = m(x_train); print(stats(zz))
# (tensor(-0.0067, grad_fn=<MeanBackward0>), tensor(0.0132, grad_fn=<StdBackward0>))
l = mse(t, y_valid)
l.backward()
stats(m[0].weight.grad) # (tensor(0.0109), tensor(0.0375))
stats(m[6].weight.grad)
# (tensor(-0.2138), tensor(0.2431))
stats(m[4].weight.grad)
# (tensor(0.0058), tensor(0.0334))
stats(m[2].weight.grad)
# (tensor(0.0077), tensor(0.0297))
stats(m[0].weight.grad)
# (tensor(0.0109), tensor(0.0375))
-
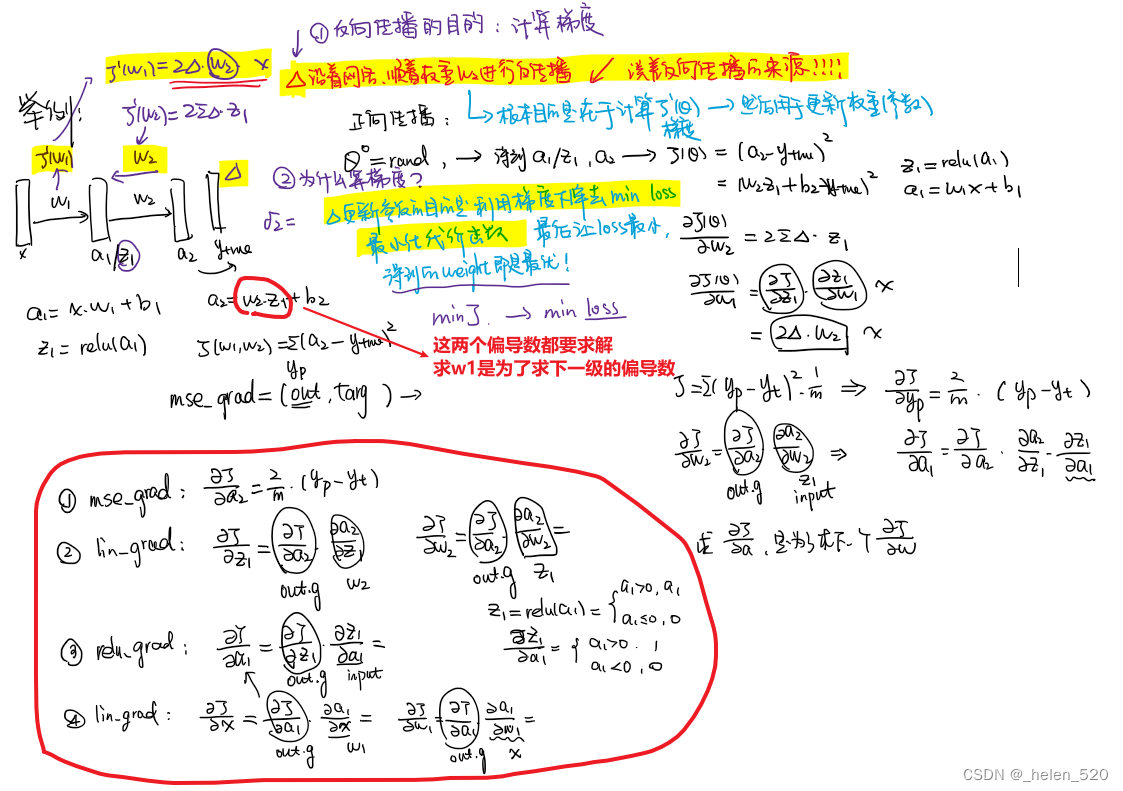
④ 简单线性模型的反向传播 lesson8
- 两个问题:梯度下降 vs 误差反向传播,是啥关系?
- ① 梯度下降是什么?
- ② 误差的反向传播是什么?
- 参考内容:神经网络中的梯度下降与反向传播的关系(大白话,通俗易懂版本)_crxk的博客-CSDN博客_反向传播和梯度下降区别
- 导数_百度百科、 梯度下降算法原理讲解——机器学习_Ardor-Zhang的博客-CSDN博客_梯度下降
# ------------------------------------------------
def model(xb):
l1 = lin(xb, w1, b1)
l2 = relu(l1)
l3 = lin(l2, w2, b2)
return l3
# torch.nn.modules.conv._ConvNd.reset_parameters
x_train = x_train.view(-1,1,784)
x_valid = x_valid.view(-1,1,784)
"""
线性模型:一个中间层(没有卷积层的情况下)
"""
def mse(output, targ):
return (output.squeeze(-1) - targ).pow(2).mean()
y_train,y_valid = y_train.float(),y_valid.float()
def mse_grad(inp, targ):
# grad of loss with respect to output of previous layer
# inp.g = 2. * (inp.squeeze() - targ).unsqueeze(-1) / inp.shape[0]
inp.g = 2. * (inp.squeeze() - targ).unsqueeze(-1) / inp.shape[0] # mse中有mean,所以需要
def relu_grad(inp, out):
# grad of relu with respect to input activations
# inp.g = (inp>0).float() * out.g
inp.g = (inp > 0).float() * out.g
def lin_grad(inp, out, w, b):
# grad of matmul with respect to input
inp.g = out.g @ w.t() # ① 计算w.g是为了梯度下降; ② 计算inp.g是计算z1、a1的链式导数,是为了求下一级的w.g服务的
w.g = (inp.unsqueeze(-1) * out.g.unsqueeze(1)).sum(0)
b.g = out.g.sum(0)
def forward_and_backward(inp, targ):
# forward pass:
a1 = inp @ w1 + b1 # a1 stats(a1)
z1 = relu(a1) # z1 stats(z1)
out = z1 @ w2 + b2 # a2 stats(out)
# we don't actually need the loss in backward!
# loss = mse(out, targ)
# backward pass:
mse_grad(out, targ) # a2.g
lin_grad(z1, out, w2, b2) # z1.g, w2.g
relu_grad(a1, z1) # a1.g
lin_grad(inp, a1, w1, b1) # w1.g
w1 = torch.randn(mm,nh)*math.sqrt(2/mm) # 线性层的初始化方式:kaiming_uniform初始化
b1 = torch.zeros(nh)
w2 = torch.randn(nh,1)/math.sqrt(nh)
b2 = torch.zeros(1)
# 进行了一次前向传播和反向传播;w的权重得到更新
forward_and_backward(x_train, y_train)4.1 Refactoring 重构——使用抽象基类实现前向传播、反向传播
- 单独建类:前向传播和反向传播;
- 时间上: 70.7ms 前向传播; 3.4s 反向传播
- 建立抽象基类: 46.3ms 前向传播; 140ms 反向传播 ;其中,线性层的反向传播的矩阵乘法的计算,导致了这两次的时间消耗差异。
① 抽象基类的核心特征是不能被直接实例化;
② 抽象基类是用来给其他类当基类使用的;
③ 抽象基类的主要用途是强制规定所需要的编程接口。- 抽象基类中,数据没有重复保留到各自的self中;
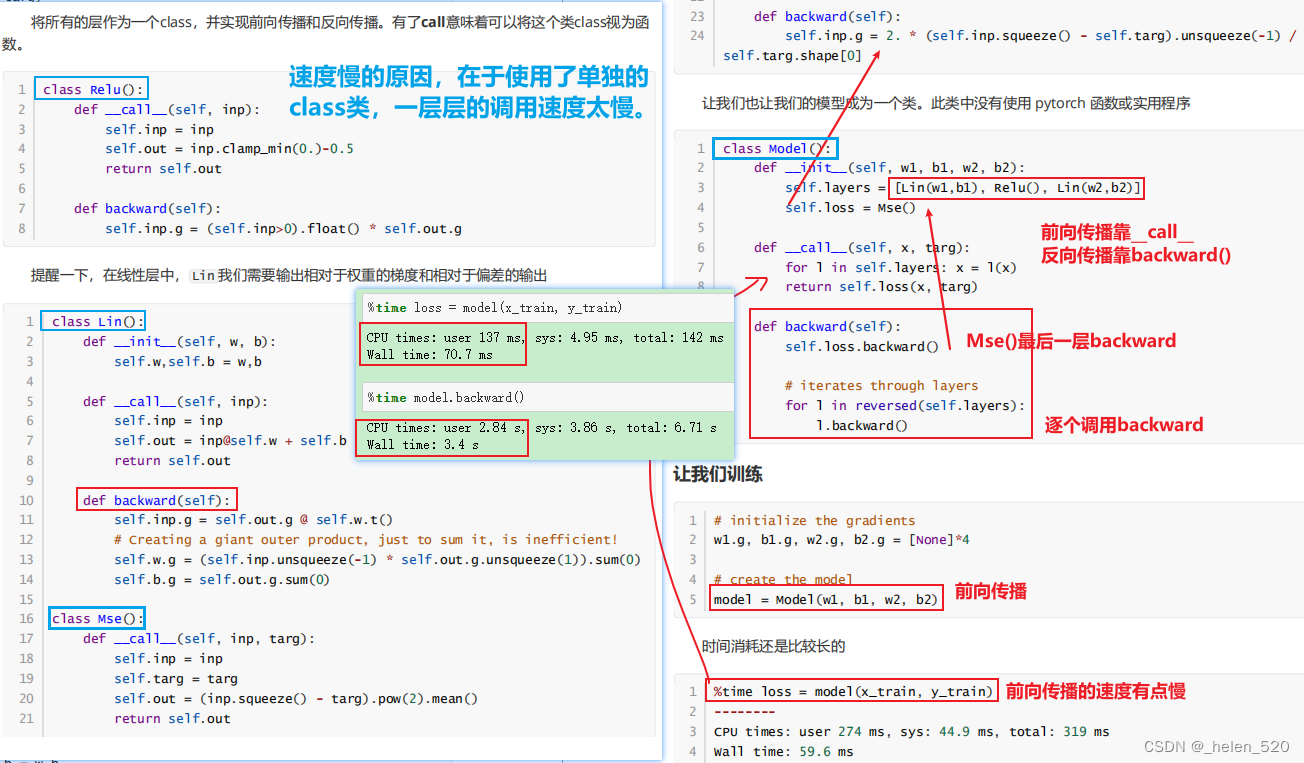
下面是建立了抽象基类的情况: 其中,线性层的反向传播的矩阵乘法的计算,导致了这两次的时间消耗差异。
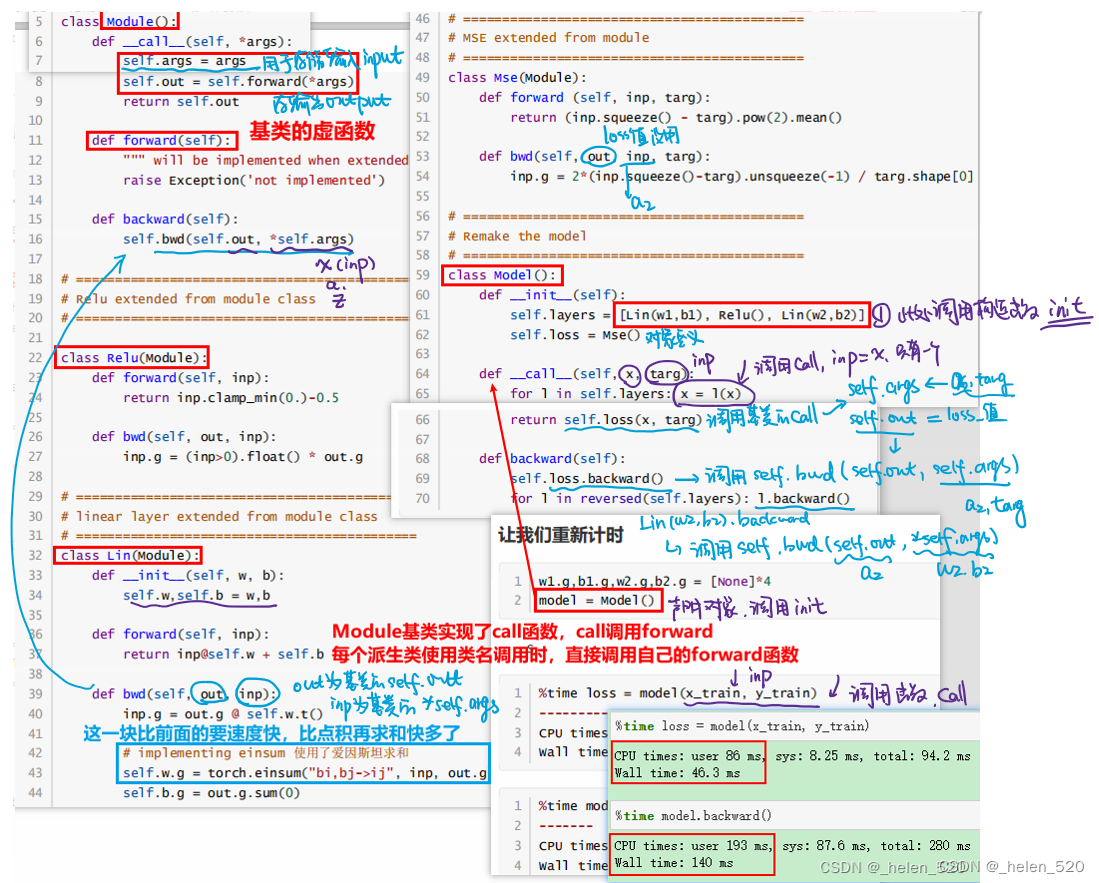
上面相当于是重构的nn.Module的前向传播和反向传播,可以看出结果是一样的。可以自己写反向传播的。
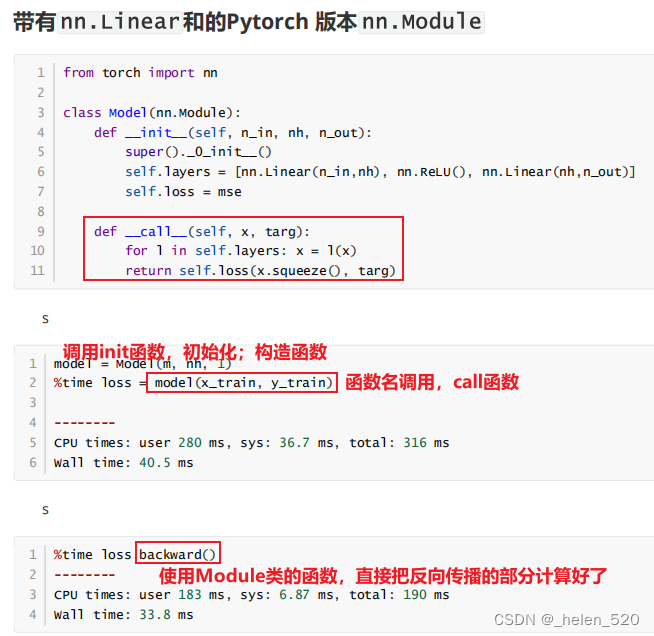
⑤ train loop训练循环
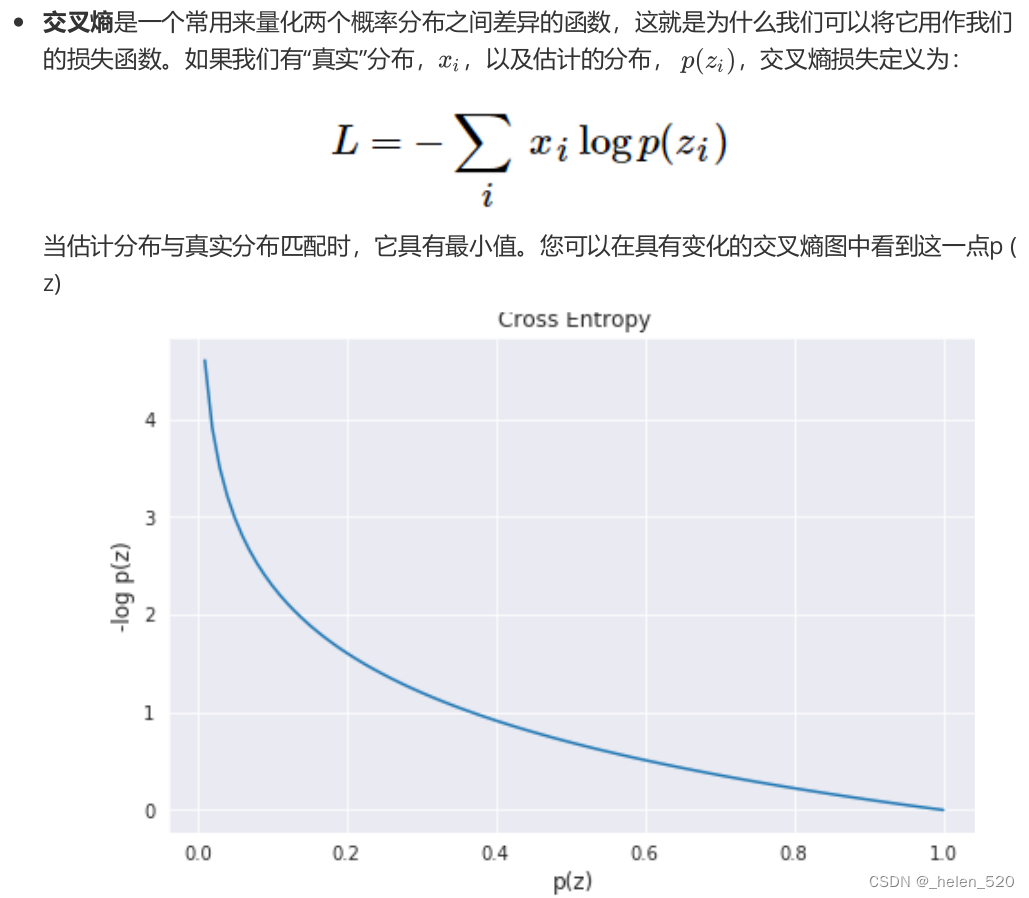
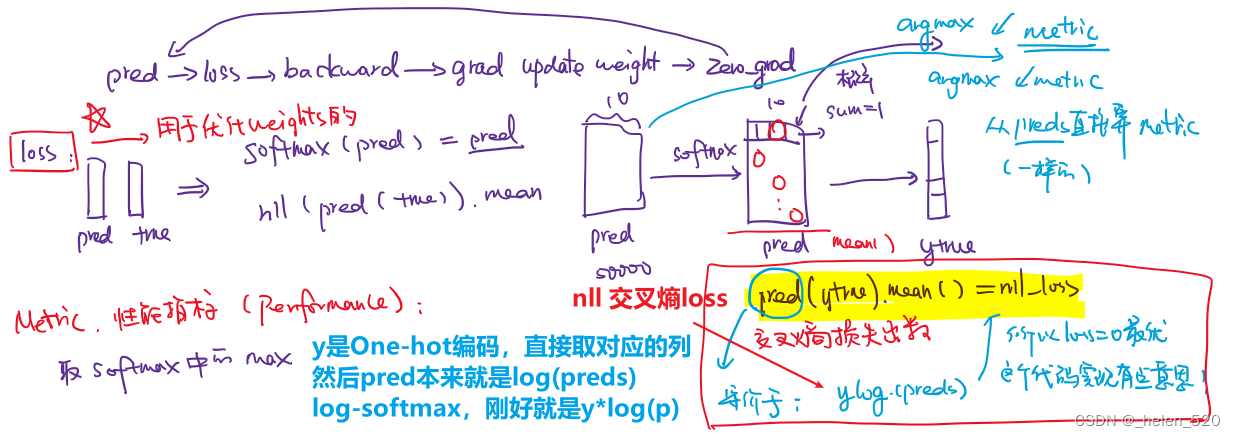
a. 分类任务的损失函数:交叉熵 cross entropy
交叉熵损失函数原理详解_Cigar丶的博客-CSDN博客_交叉熵损失函数 、画图3D图的网址:Calculator Suite - GeoGebra
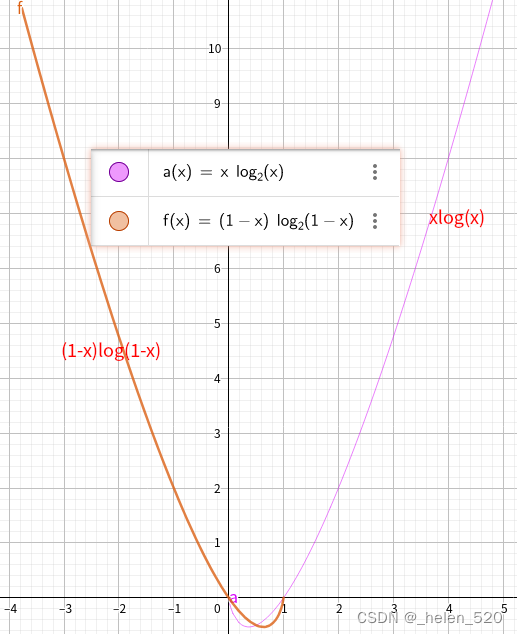
xlogx与(1-x)log(1-x)的函数曲线如下图所示: 是一个凸函数。
- 对交叉熵函数有一个认识!二元函数xlogy在什么时候取得最小值,当y=x时取最小。
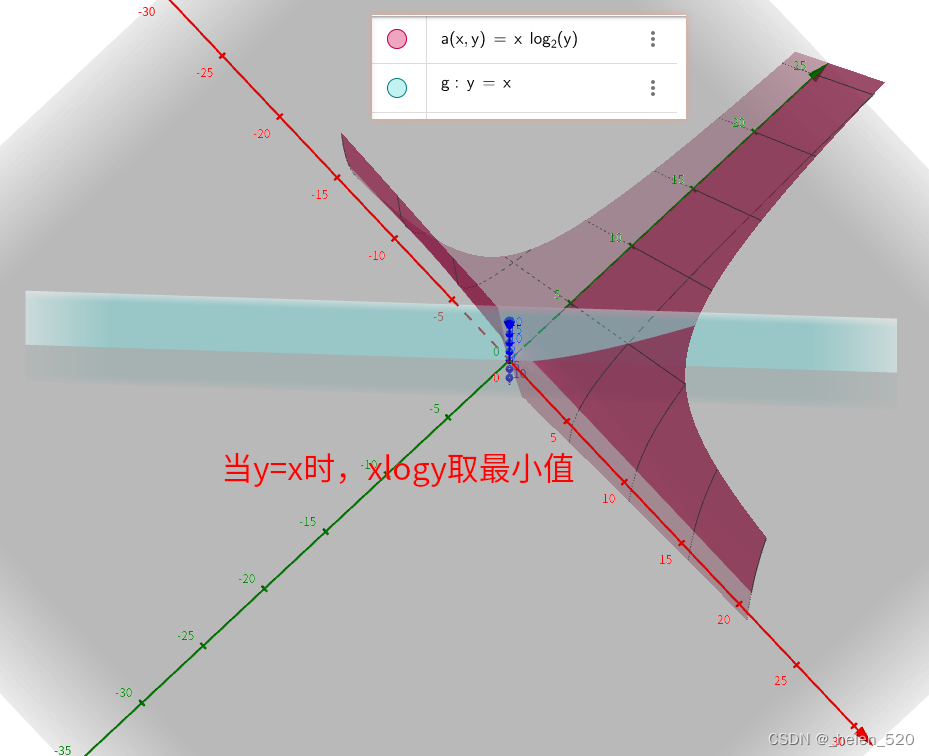
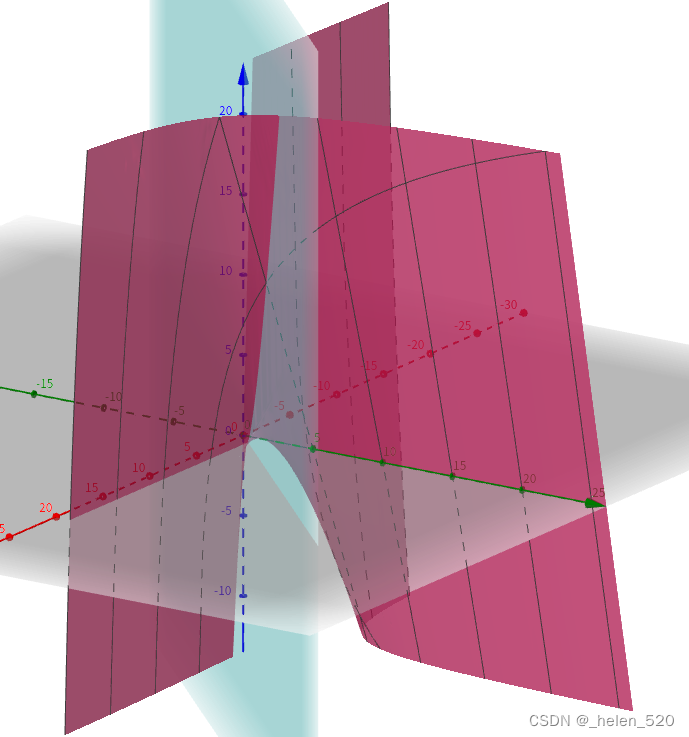
- xlogy是一个曲面,且是一个凸曲面,这个曲面的最低点就是函数min(x*logy)的最小值。即当y=x时,这个曲面取得最小值。
- 对于交叉熵来说:L取得最小值,是在x=y处;也就是pred_y与y_true的类别完全一样时,就取得最小值。
- 所以适合用在分类任务中作为Loss损失函数。
- x*log(y)来源于通信领域的信息论,有其物理背景和现实含义,也可以用于理解和参考。
-
交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。
-
交叉熵在分类问题中常常与softmax是标配,softmax将输出的结果进行处理,使其多个分类的预测值和为1,再通过交叉熵来计算损失。
-
softmax是为了得到p(x),然后才能计算 yi*log(p(x));把预测的结果变为概率,这是关键!
-
交叉熵是分类任务的损失函数
-
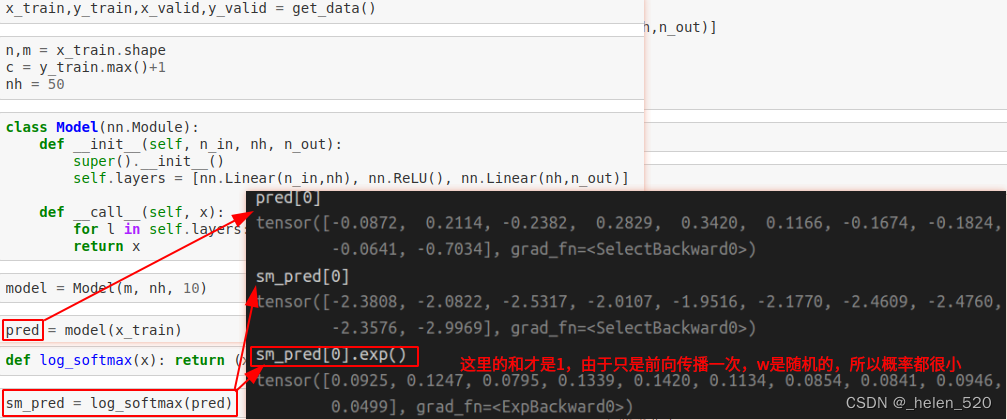
b. softmax的工程实现
- 由于浮点数、指数、对数,在实际计算过程中可能会出现不可思议的bug!一定要注意代码具体实现。
- ① 尽量避免对数、指数运算;因此利用公式,将对数指数给消减,得到分母的x(避免了做一个对数、再做一个指数的危险运算)
- ② 为了防止分母的部分会对一个较大的数值取对数,因此先取一个max,做减法。

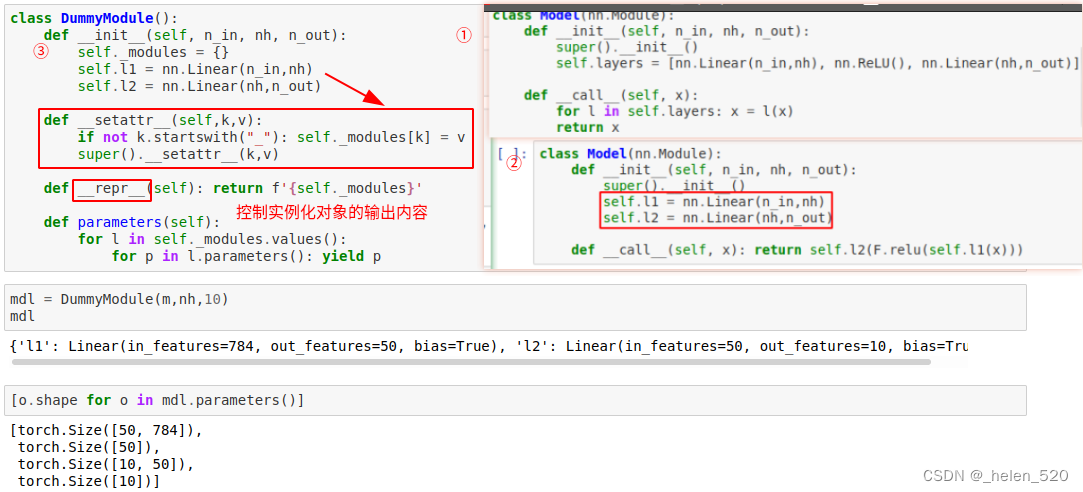
c. Module基类的重构
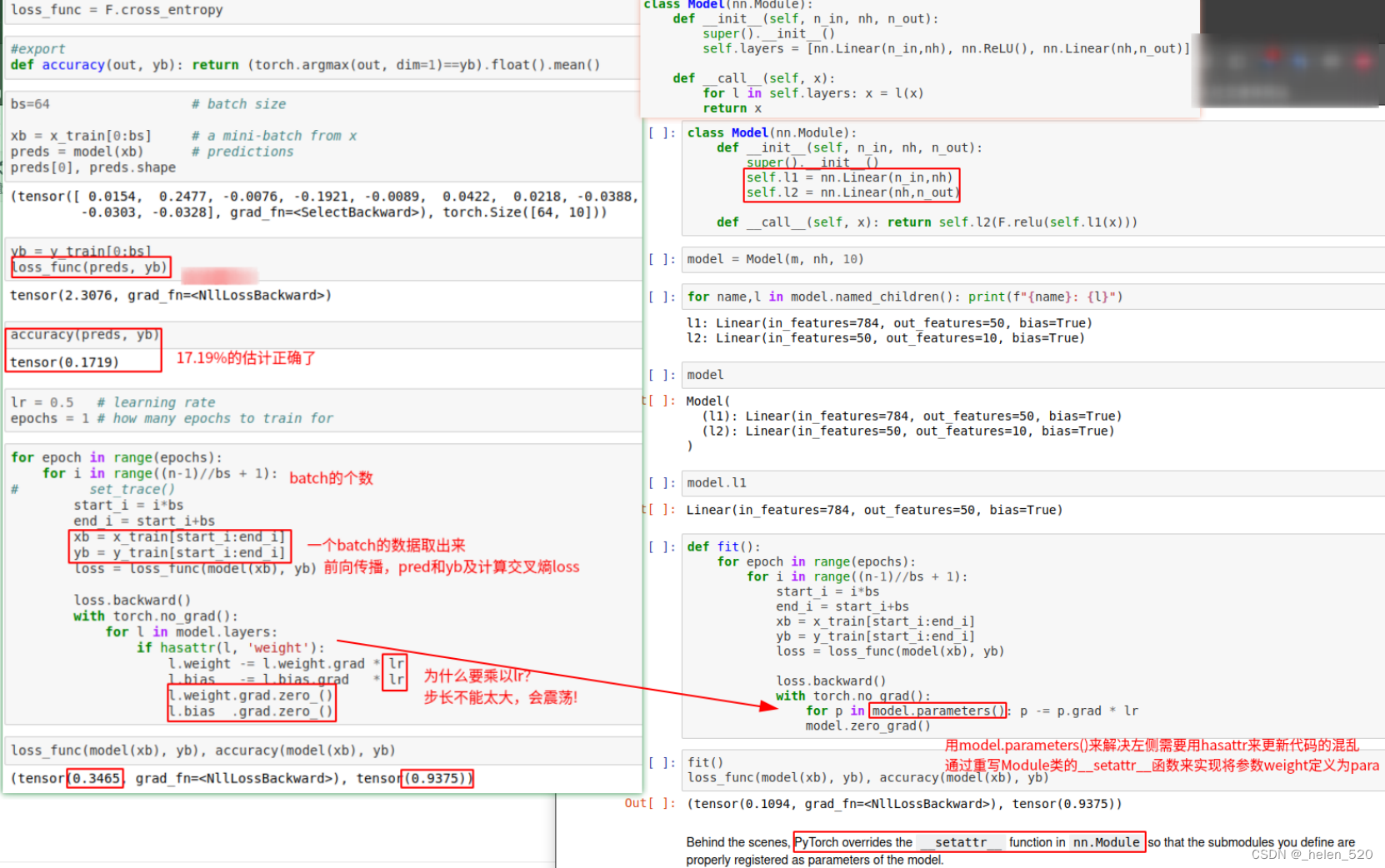
- 使用__setattr__来实现Parameter()功能
- 参考教程:理解setattr python魔法方法之__setattr__() - 知乎
- 类的构造函数,每次给self赋值时,都要调用一次__setattr__函数。
- __setattr__()方法在类的属性赋值时被调用,并通常需要把属性名和属性值存储到self的__dict__字典中。
- 【Python】详解类的 __repr__() 方法_Xavier Jiezou的博客-CSDN博客 repr()函数功能:控制此函数为它的实例所返回的内容。
- 参考教程:理解setattr python魔法方法之__setattr__() - 知乎
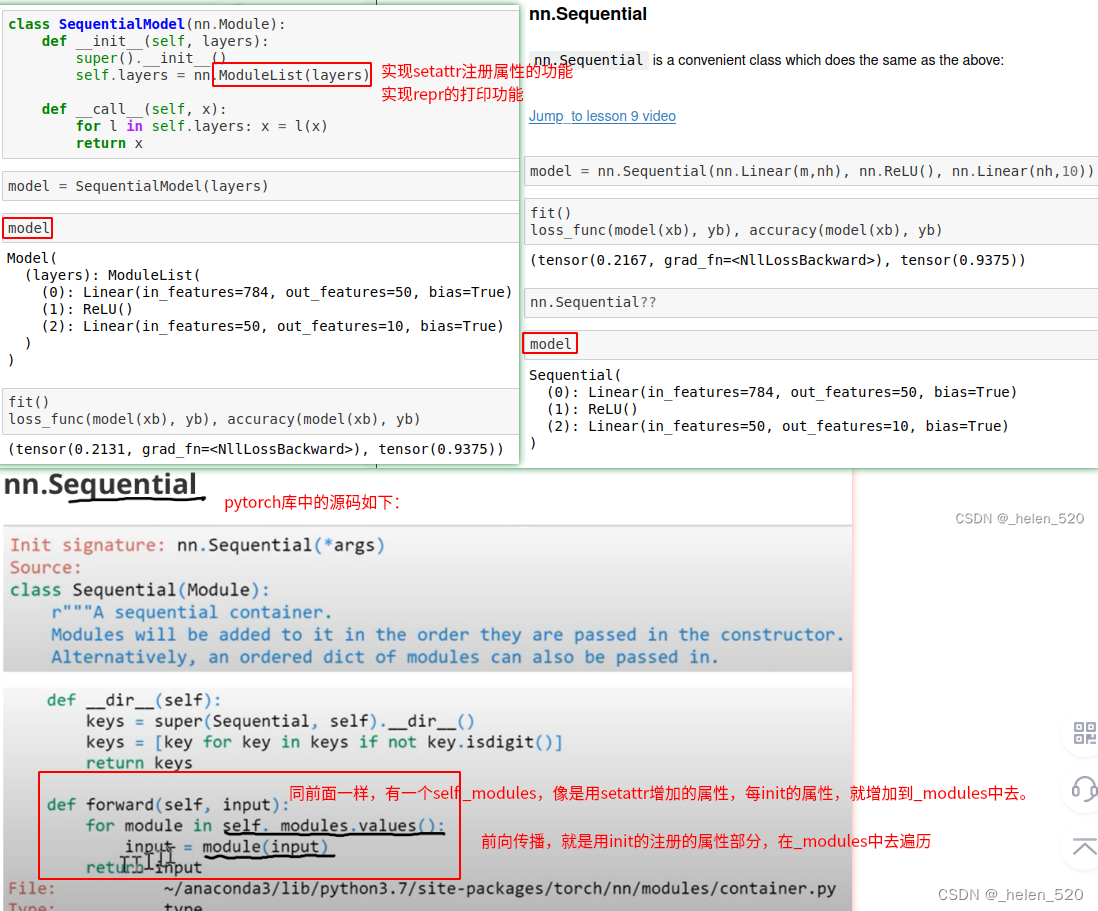
- Pytorch的nn.Sequential实现了setattr功能,也实现了repr功能。
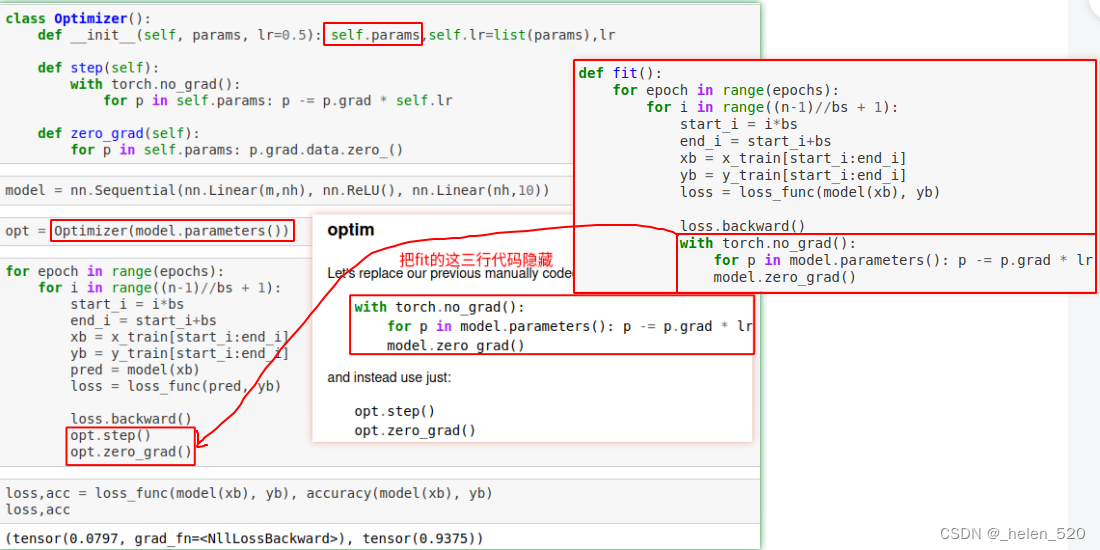
⑦ Optim优化
- 通过Optimizer类来隐藏这三行代码。
- 反向传播、参数更新、梯度归零
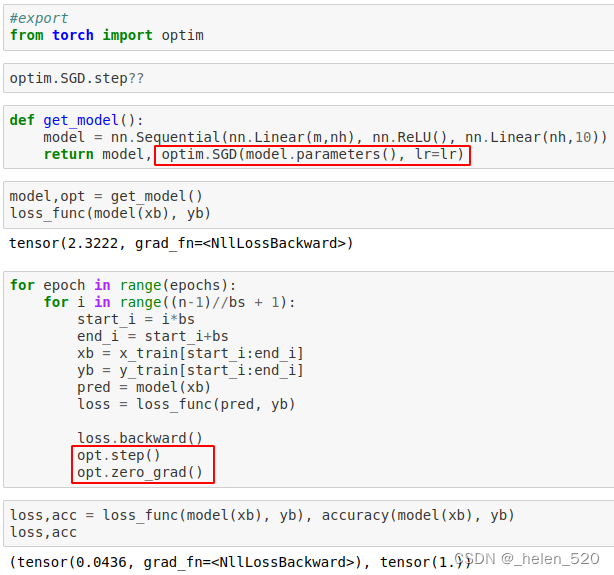
- pytorch中也已经有了相应的代码,为optim.SGD,SGD里面做了很多事情,如Weight decay,Momentum等。
⑩ DataLoader、Dataset
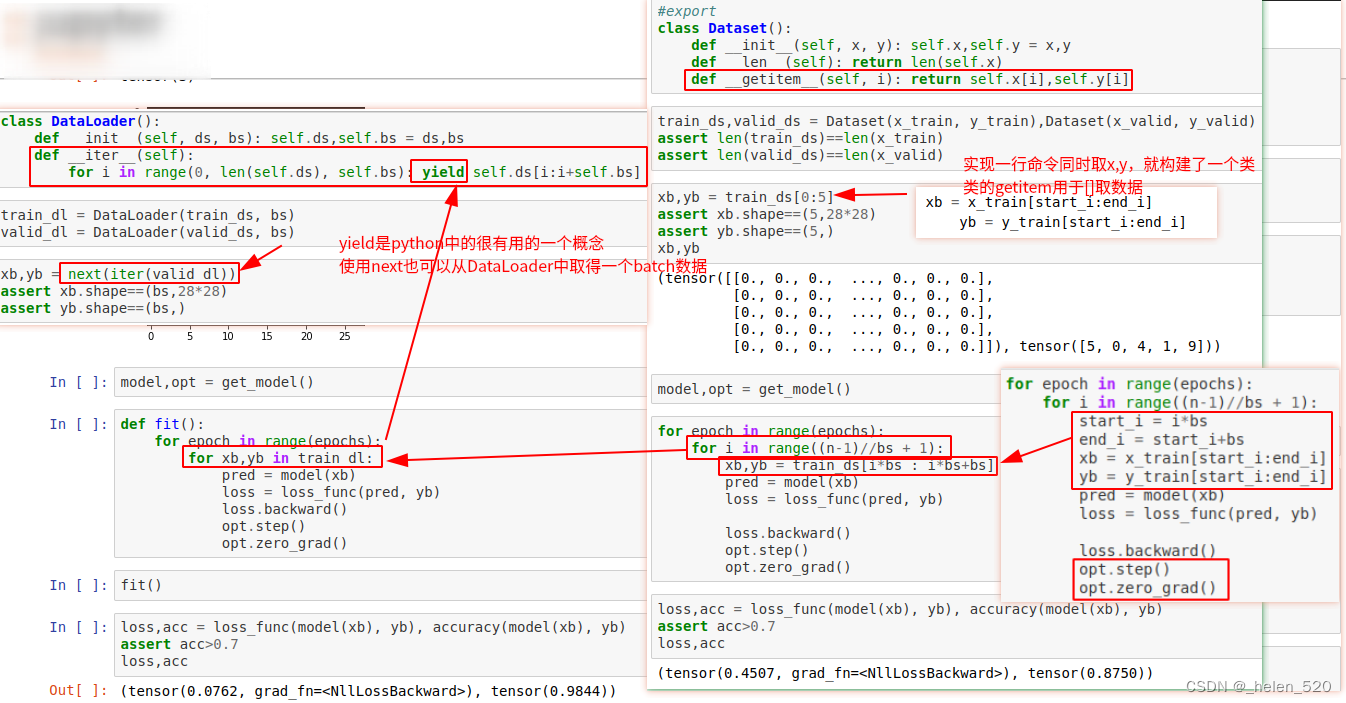
随机洗牌:Radom Sampling
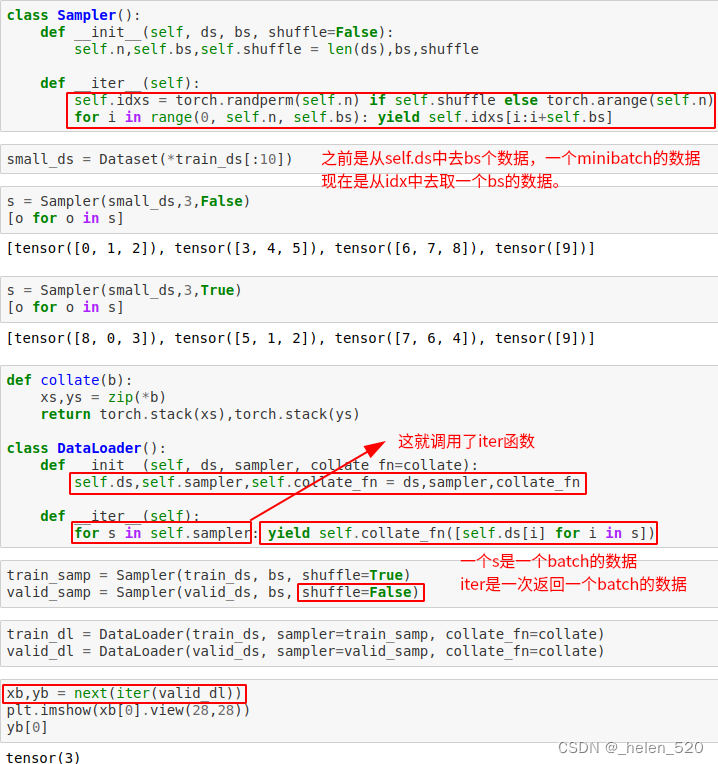
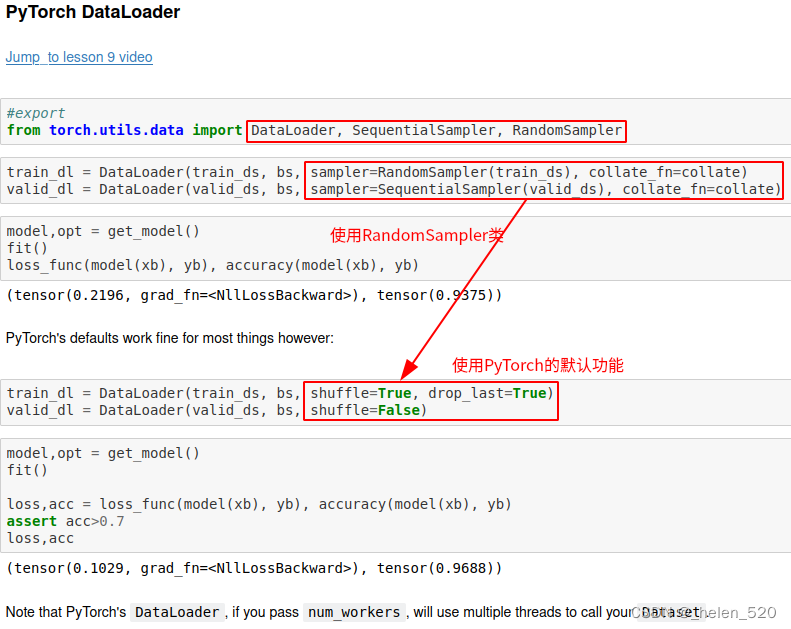
Validation类
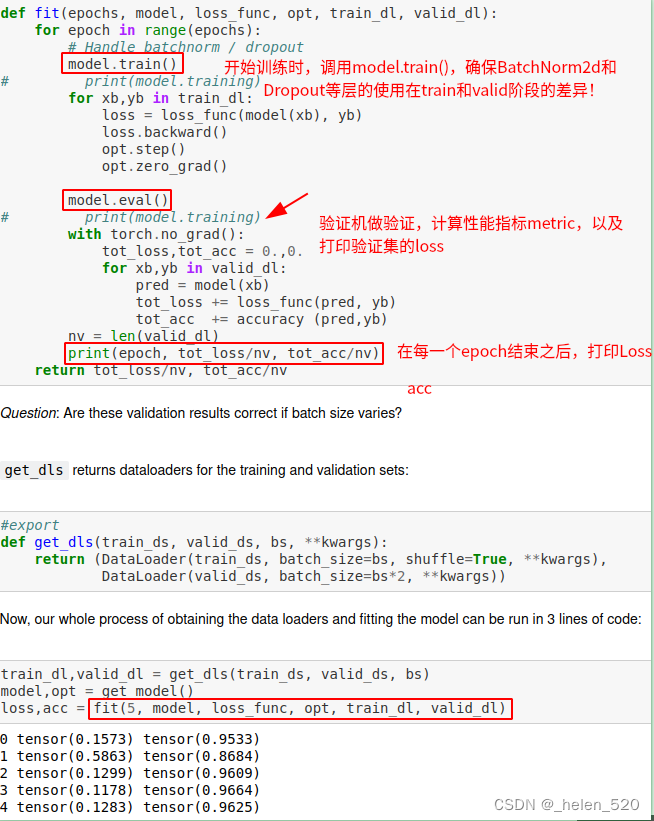
⑪ Callbacks 回调函数
对fit()函数进行修改,让大家可以在里面实现进度条、选择不同的优化器、tensorboard集成、正则化等功能。
对于一个库而言,需要足够开放和灵活,这样才能添加和处理很多不可预见的扩展功能,callback回调函数就是一种方法可以来实现这种灵活的扩展功能。
- CallbackHandler和Callback的调用逻辑梳理如下
class TestCallback(Callback):
def begin_fit(self,learn):
super().begin_fit(learn)
self.n_iters = 0
return True
def after_step(self):
self.n_iters += 1
print(self.n_iters)
if self.n_iters>=10: self.learn.stop = True
return True
fit(1, learn, cb=CallbackHandler([TestCallback()]))
1
2
3
4
5
6
7
8
9
10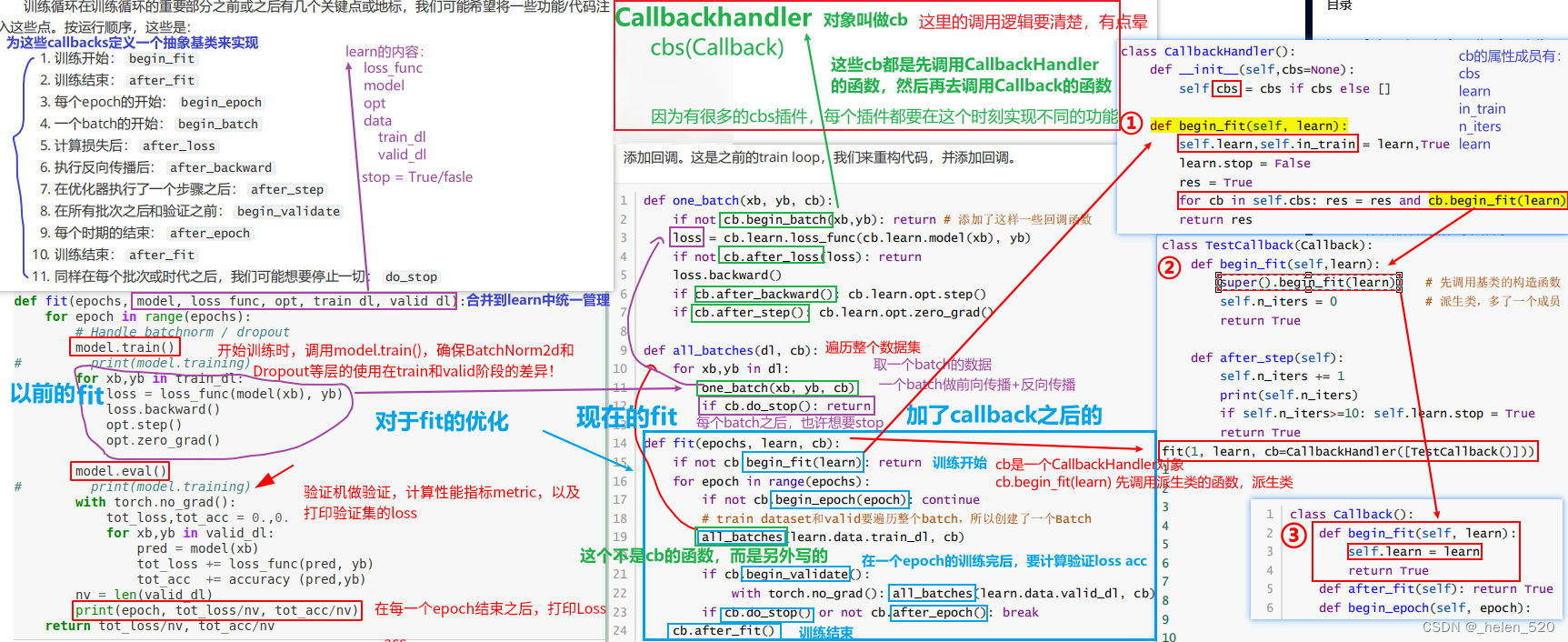
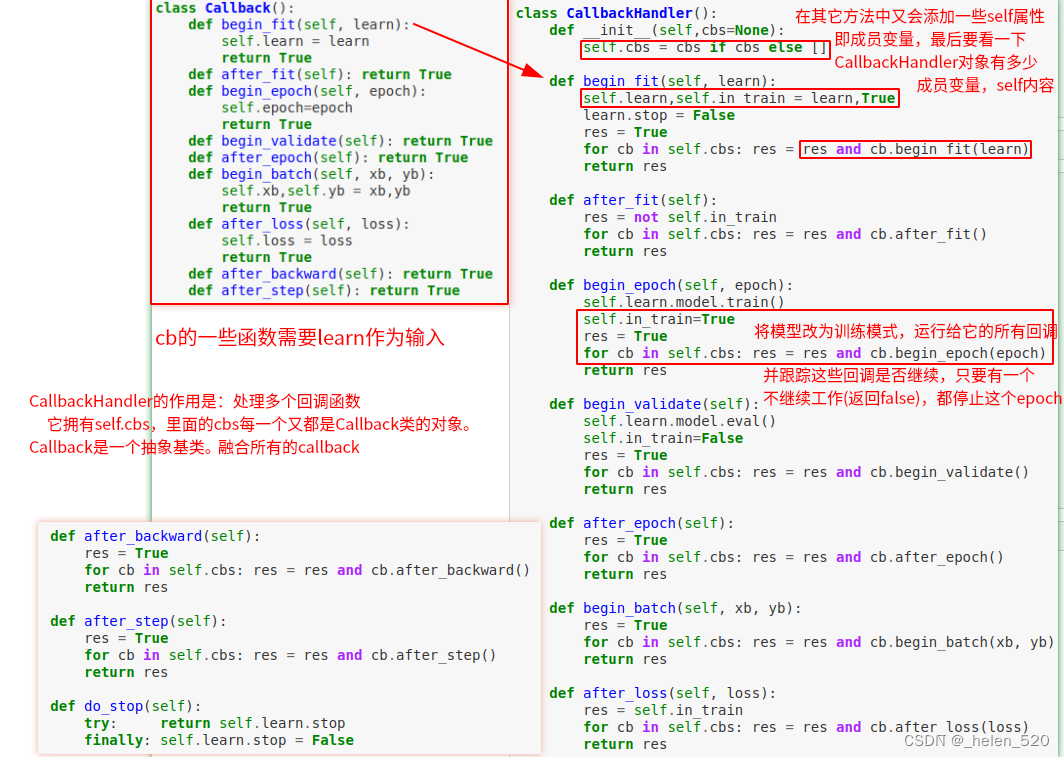
Callback继续优化
由于fit、one_batch、all_batches等函数里面都在反复调用cb(CallbackHandler)。考虑优化这一点。

新的Callback类设计如下:
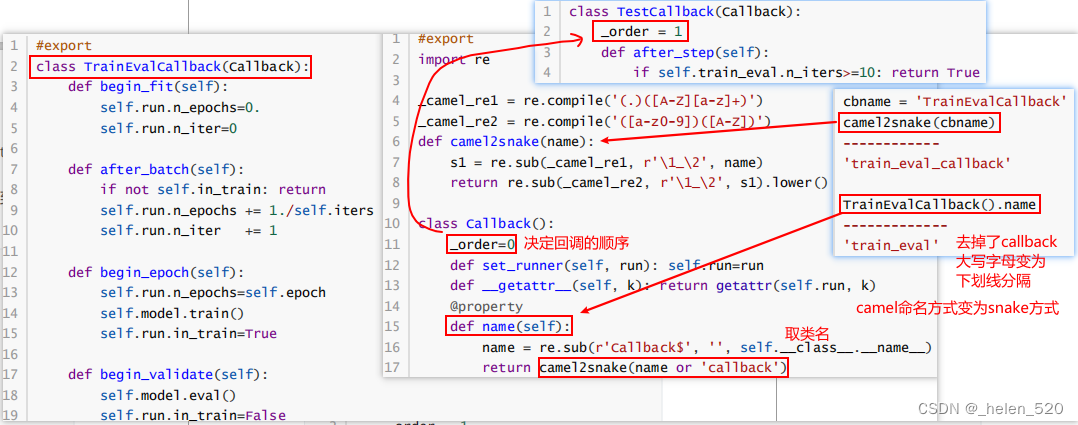
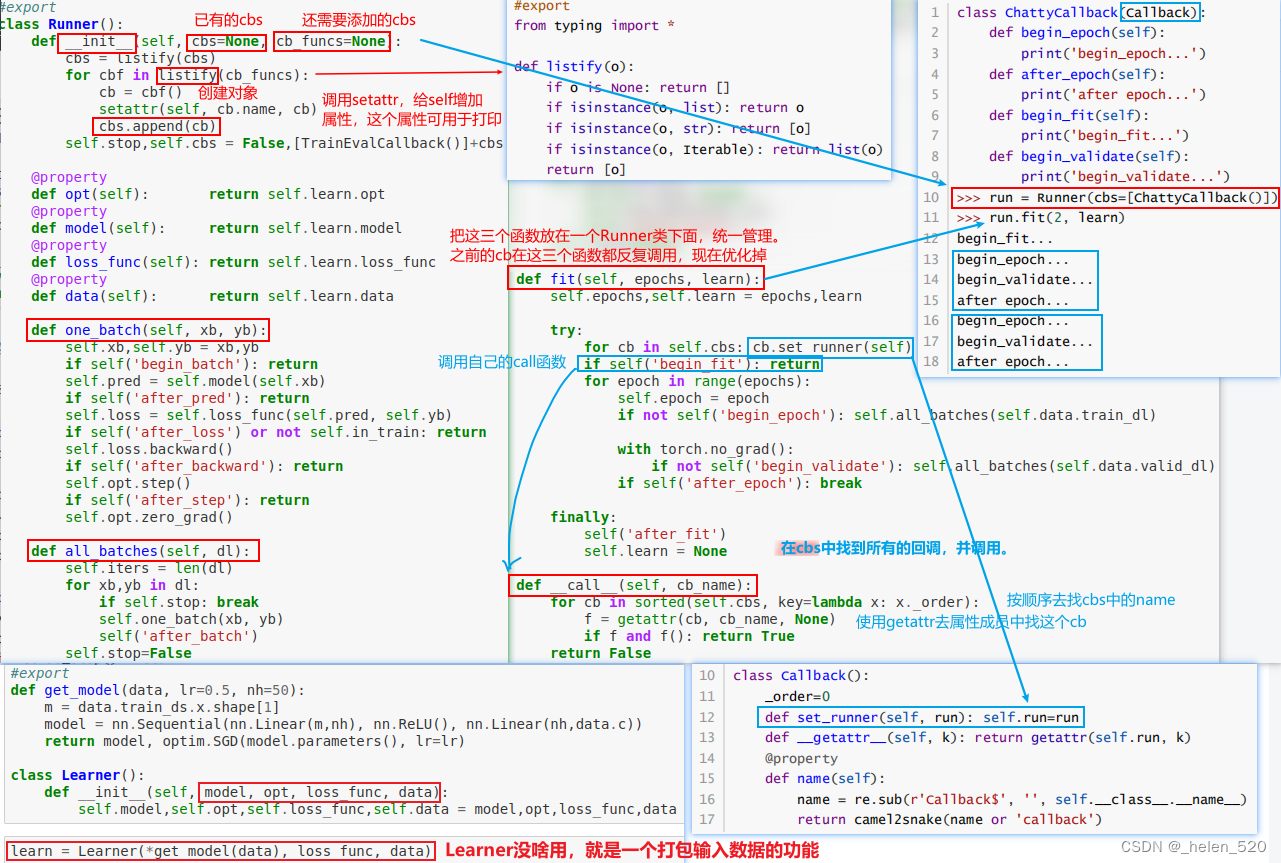
将fit、one_batch、all_batches等函数合并在一个类Runner中,统一管理,这样cbs就不用重复引用。
- Runner主要用来管理cbs的,可以添加、修改、重复等。
- 这样的Runner设计将训练循环和callback回调相分离。这样即使训练循环的训练和验证部分所需的不同逻辑也可以实现为 Callback 硬编码到 Runner 类中的
- 给cbs一个顺序,允许不同的cbs对象定义同样的功能,只要给cbs对象一个优先级,然后决定根据优先级顺序调用即可。
- __call__函数中,`f = getattr(cb, cb_name, None)` 是看cb中是否有cb_name这个method方法/函数。一个cb可能有多个方法。这样就调用了所有cb中的cb_name方法。
callbacks和hook的差别?
- 目前无法再model()前向传播,或者loss.backward()中间加入回调函数。
- hook是在前向传播、反向传播的过程中,将activations中间层的数值给保存下来。
- hook是一个特殊的pytorch hooks callbacks,可以添加到特定的pytorh模块中,我们在后面的课程中还会继续讲解的。
⑫Anealing 学习率退火
- 需要创建一个回调函数来进行超参数的调度。比如对学习率lr在每个batch都要进行调整。
我们要能对训练过程中的环节都能加以干预:比如dropout的数量、怎样的数据增强、weight decay、learning rate、momentum等。这样一切才有意义。 - 定义两个新的callback
- Recorder用于保存loss、lr
- ParamScheduler用于调度超参数
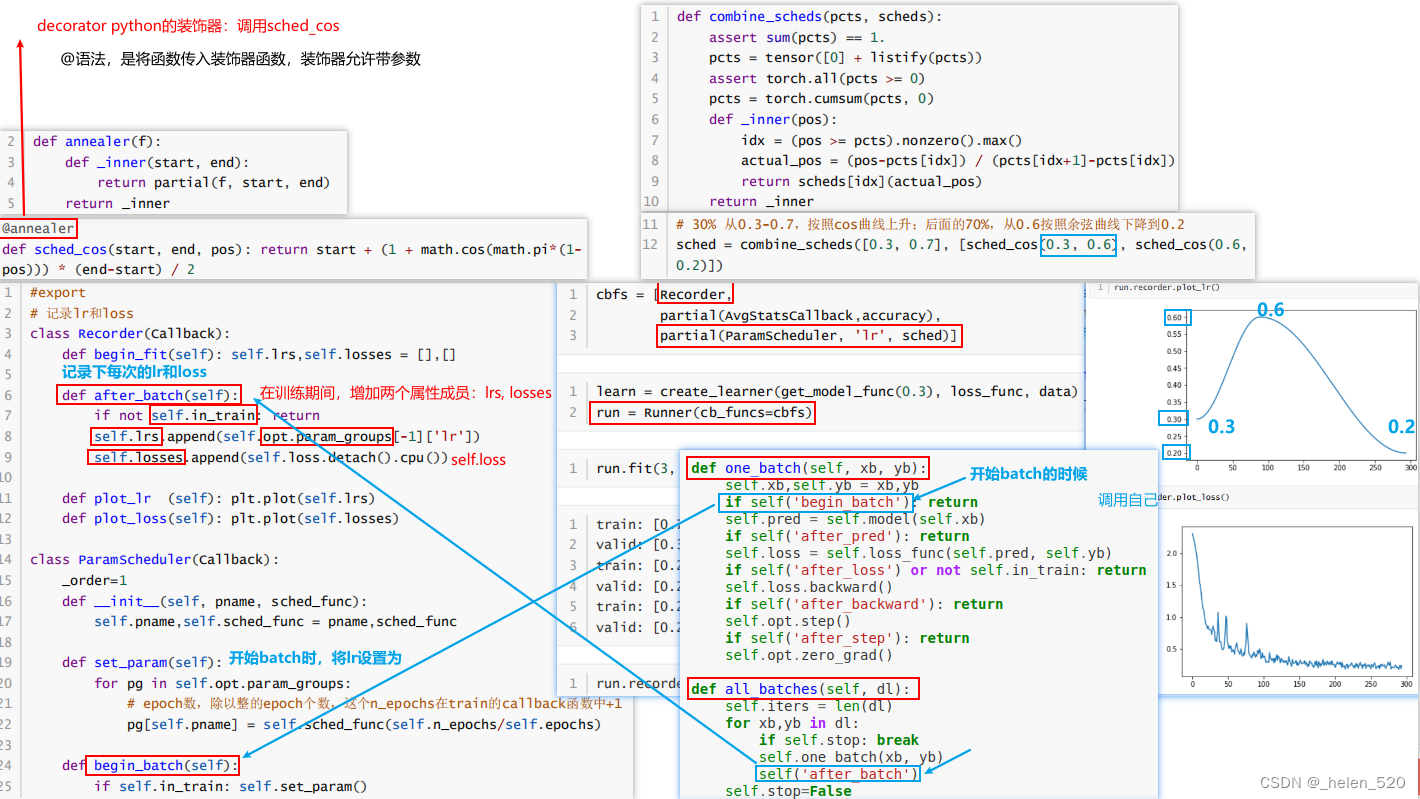
- matplotlib无法绘制tensor, torch.Tensor.ndim = property(lambda x: len(x.shape))
- 给torch的tensor指定一个新属性,就可以绘制了。
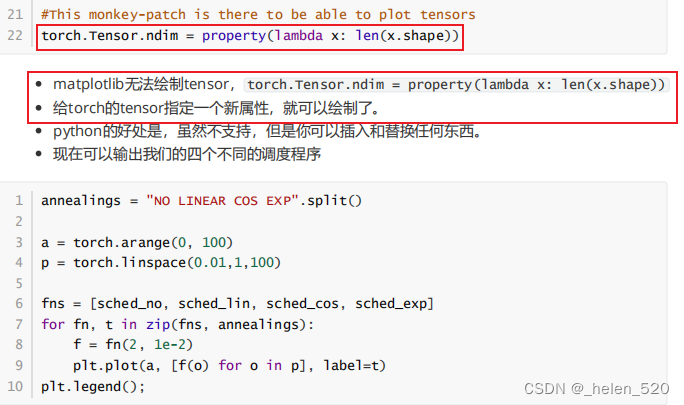
- fastai的1cycle方法。
- 一开始用高的学习率
- 然后需要在很长一段时间内以非常低的学习率进行微调
- 使用1cycle之后,确实提升了一些valid_acc。
- 我们目前还是在Mnist数据集上,使用的最简单的一个隐藏层的网络。















 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









