







- 视频:yotube Jeremy的主页播放列表
- PPT&Jupyter notebook:https://nbviewer.org/github/fastai/fastai1/tree/master/courses/
- 笔记:About the Part 2 & Alumni (2018) category - Part 2 & Alumni (2018) - Deep Learning Course Forums 所有2018课程的wiki
- lesson8 wiki:Part 2 Lesson 8 wiki - Part 2 & Alumni (2018) - Deep Learning Course Forums
- notes: https://medium.com/@hiromi_suenaga/deep-learning-2-part-2-lesson-8-5ae195c49493
- notes: DeepLearning-Lec8-Notes - Part 2 & Alumni (2018) - Deep Learning Course Forums
- 课程的字幕:我有使用网易见外工作台,进行语音翻译,得到文本,比之前的视频字幕翻译要好很多。(视屏自动字幕是yotube平台的,自动识别字幕,且自动翻译,只有每一行的,整个不连续不完整)。
- 稍后贴上下载连接
- lesson8 目标检测:最大bbox的分类器。resnet34的分类器。 分类类别为20类。
- 单目标检测:回归,从分类的网络到回归的网络。使用L1loss() MSE的loss函数。
1. 目前已经学习的内容
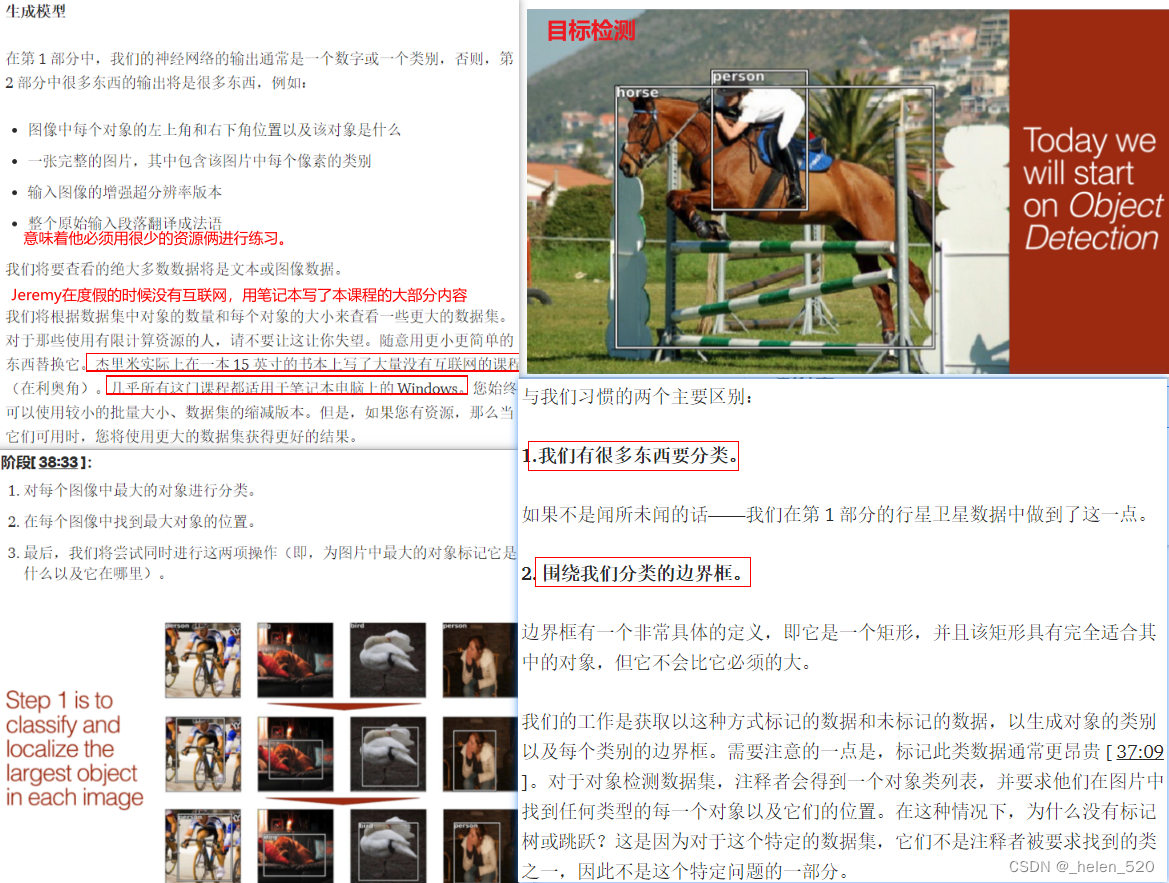
今天我们要讲的是目标检测,它不仅指找出一张图片是什么图片,还包括物体的位置。但总的来说,这部分每节课的思想不是太多,因为我特别想让你们关心,比如,目标检测,而是因为我试图选择一些主题,让我能教你一些你们还没有掌握的基础技能。
目标检测,它将是关于 创建更丰富的卷积网络结构,其中有很多更有趣的东西。
- 可微分层
- 迁移学习
- 网络架构设计
- 处理过拟合
- embedding
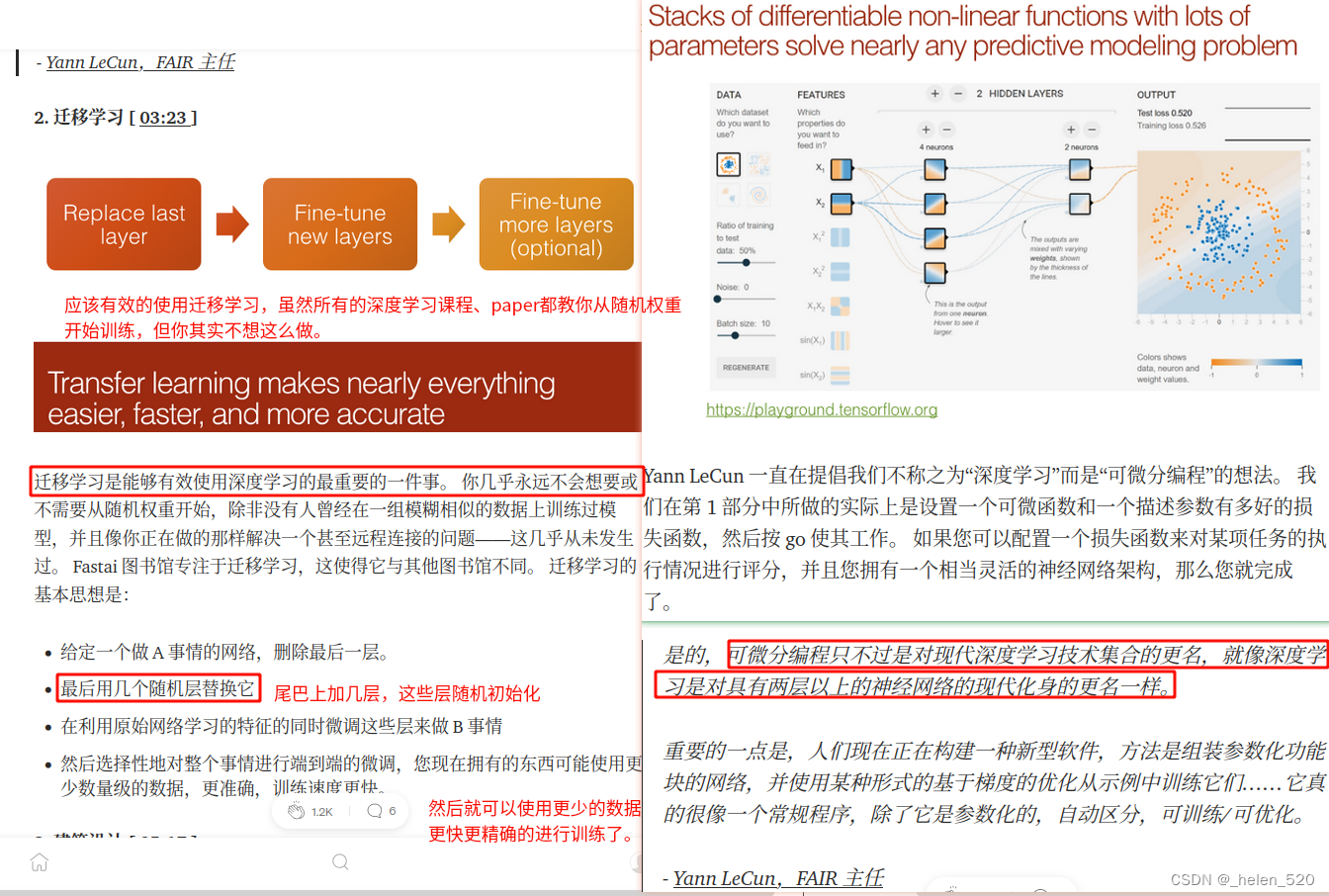
杨乐坤一直在推广说,我们不要叫深度学习。而是可微分编程。你已经注意到,我们在第一部分所做的所有事情都是关于建立一个可微函数和一个损失函数来描述参数有多好,然后按下继续键,它就会工作。
一个可微函数,一个loss描述参数的好坏,一个合理的灵活的神经网络架构。
我们已经学习过这些了,这部分将逐一介绍这些关键的点。
这个网站你可以手动的交互式地创建小的可微函数。
2. 迁移学习
迁移学习可以让我们有效的使用深度学习。
3. 架构设计、处理过拟合
网络架构设计基本上没啥可做的,现在一部分通用架构就可以工作的很好了。我们在架构设计上讨论的很少。
我们还研究了如何处理过拟合。
第一部分的课程是我向你们展示了足够成熟的技术,确保它们可以合理的、可靠的应用于现实实际的问题。Jeremy已经在这上面研究和调整了一段时间,然后给出了一些列的步骤和架构,如果你使用它,肯定能得到很好的结果。然后Jeremy就把它们放在fastai的库里,大家可以用很简单的方式开始。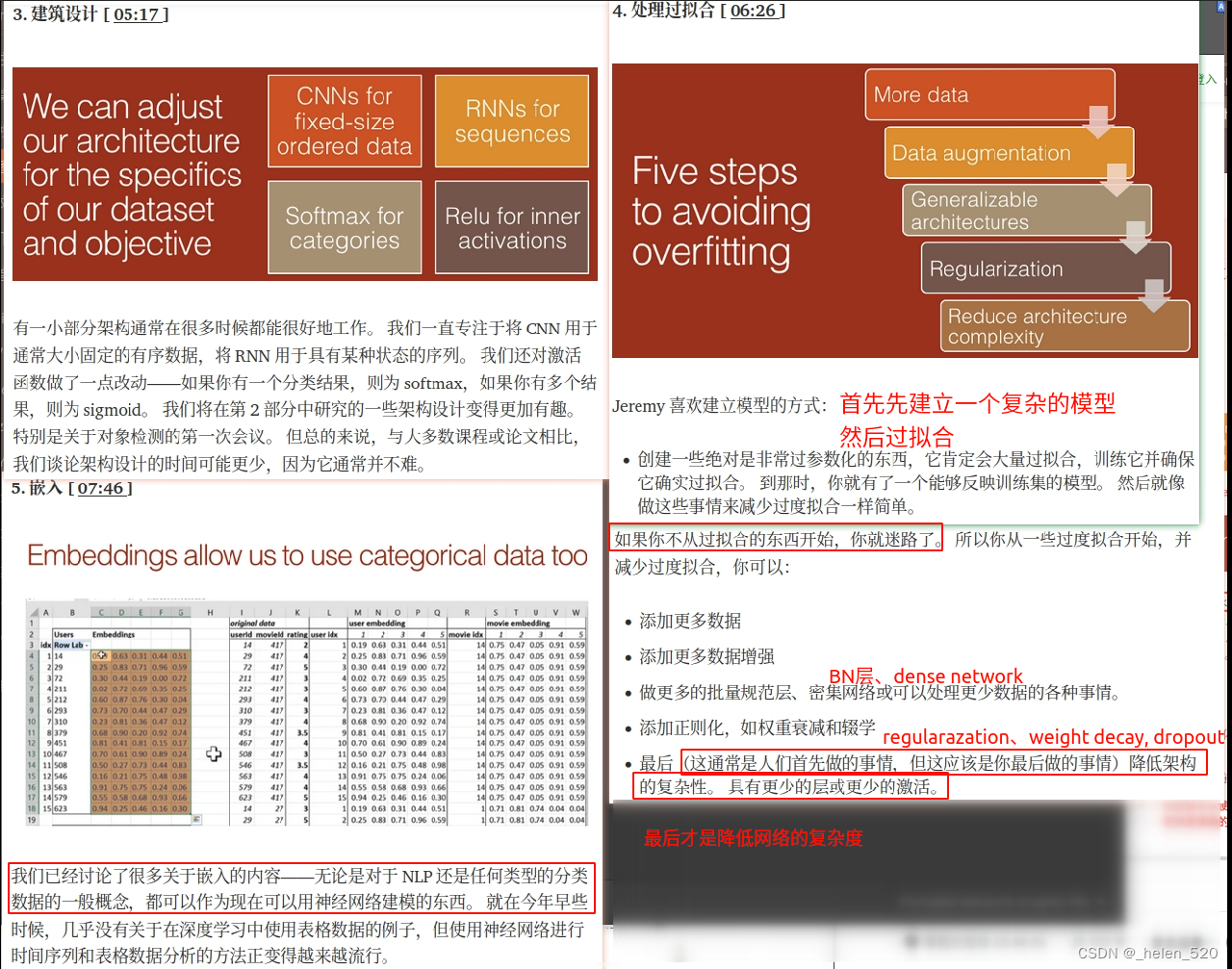
part2的课程是把fastai库和pytorch这个黑盒拆开。充分了解细节、自定义、debug、阅读源码。
如果觉得编程技术困难,如python面向对象之类的,去学习。网络上有很多的资源,fastai的forum论坛上也有的,这又不是火箭科学那么难。网络上有教程都可以学习的,只是你还没有看到这些教程和资料,并不意味着这些东西很难!
4. 我们该如何使用fastai的Notebook?

5. 建立自己的GPU、CPU、硬盘等深度学习环境

每周,我们将实施一两篇论文。 左边是实现 adam 的论文的摘录(您也将 adam 视为电子表格上的单个 excel 公式)。 在学术论文中,人们喜欢使用希腊字母。 他们也讨厌重构,所以你经常会看到一个页面长的公式,当你仔细查看它时,你会发现同一个子方程出现了 8 次。 学术论文有点奇怪,但归根结底,这是研究界交流他们的发现的方式,所以我们需要学会阅读它们。 一件很棒的事情是拿一篇论文,努力理解它,然后写一个博客,用代码和普通英语解释它。 很多这样做的人最终获得了相当多的追随者,最终获得了一些非常棒的工作机会等等,因为能够证明你可以理解这些论文、用代码实现它们并解释这些论文是一项非常有用的技能他们用英语。 很难读懂或理解你不能发声的东西。 所以学习希腊字母!


6. 第二部分课程将要学习的内容
第二部分我们将学习生成模型。
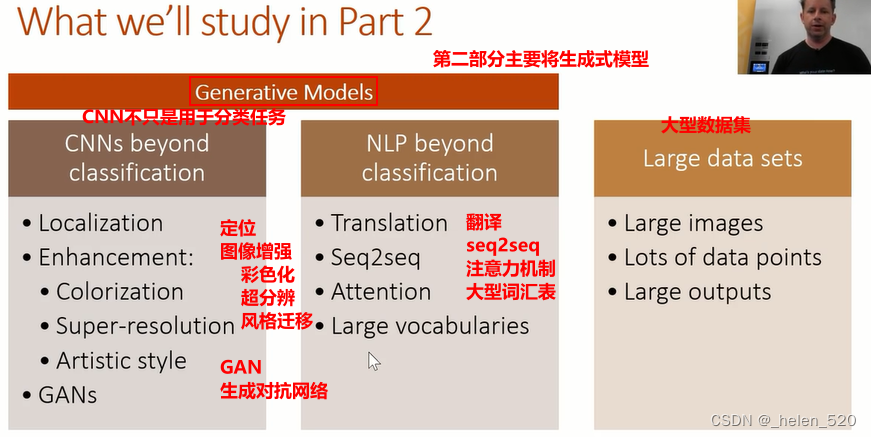
7. 目标检测
备注:2018 fastai course(1),v1版本的课程的环境在fastai1中,dl2中有fastai,按照fastai forum上的wiki中说明,设置即可。网址如下:
Fastai v0.7 install issues thread - Part 1 (2018) - Deep Learning Course Forums
用常量而不是字符串很有帮助,因为我们可以完成制表符并且不会输入错误。 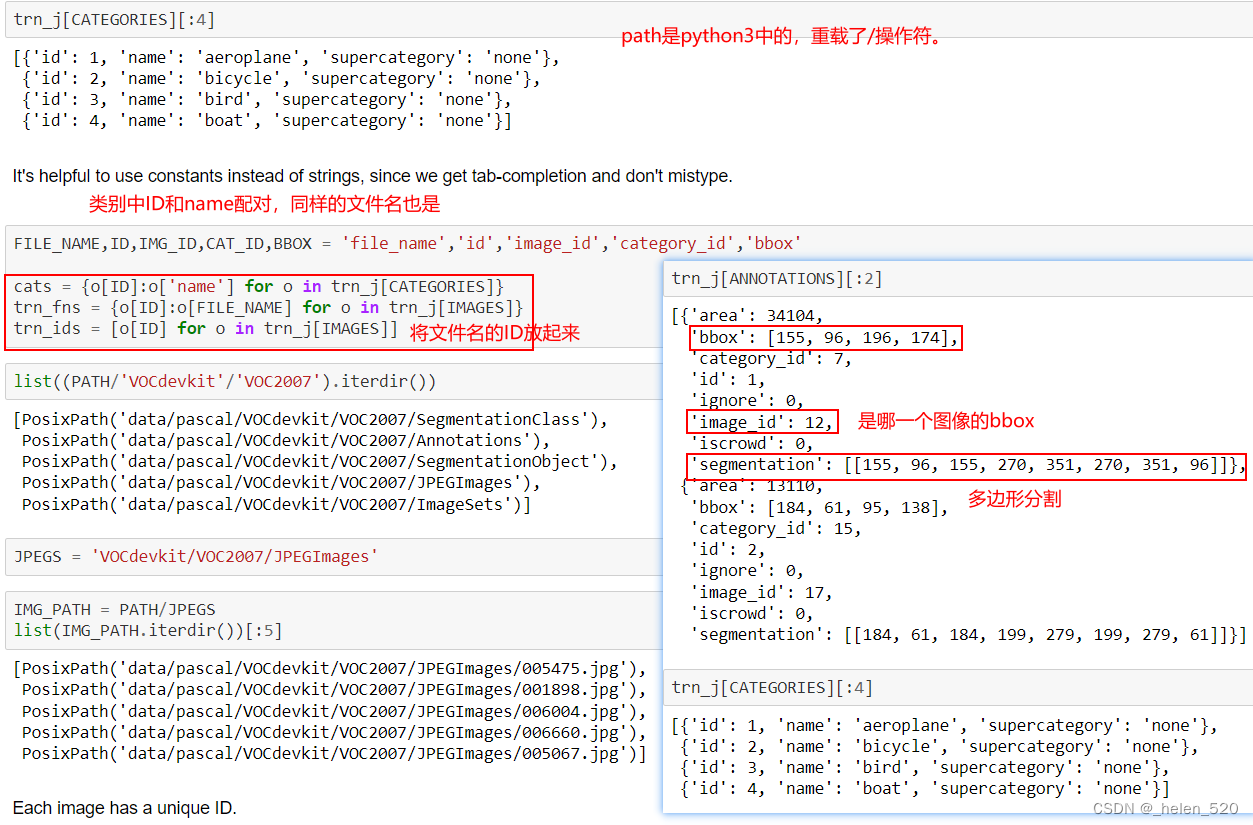
但是 Jeremy 会介绍一些他认为特别有用的工具,比如 Python 调试器,如何使用你的编辑器来跳转代码。 一般来说,会有很多更详细和具体的代码演练,编码技术讨论,以及更详细的论文演练。 (vs code演示)
注意示例代码 [ 13:20 ]! 代码学者已经提交了其他人在 github 上编写的论文或示例代码,Jeremy 几乎总是发现存在一些严重的严重缺陷,因此请小心从在线资源中获取代码并准备进行一些调试。
当人们看到杰里米在看到他的课程后实时工作时,他们最多评论的是什么 [ 51:21 ]:
“哇,你实际上不知道自己在做什么,是吗”。 他所做的 99% 的事情都行不通,而行得通的事情也只有一小部分在这里结束。 他提到这一点是因为机器学习,尤其是深度学习非常令人沮丧 [ 51:45 ]。 理论上,你只需定义正确的损失函数和足够灵活的架构,然后按下 train 就完成了。 但如果这真的是所有的事情,那么什么都不会花费任何时间。 问题是,在它起作用之前的所有步骤,它都不起作用。 就像它直接进入无穷大,由于张量大小不正确而崩溃等等。他会努力向你展示一些调试技术,但这是最难教的东西之一。 它需要的主要是坚韧。 超级有效的人和那些似乎没有走得太远的人之间的区别从来都不是关于智力的。 它一直是关于坚持下去——基本上永不放弃。 这种深度学习尤其重要,因为你不会得到持续的奖励循环[ 53:04 ]。 这是一个持续不断的不工作,不工作,不工作,直到最终它这样做,这有点烦人。
机器学习尤其是深度学习,有点令人难以置信的沮丧,因为在理论上,你证明了正确的损失函数和一个足够灵活的架构,你按下训练键,你就完成了,对吗?但如果这只是说说而已,那什么都不用花时间。问题是所有的步骤,直到它起作用,它不起作用,就像它直接变得无限大、或者网络崩溃了,一个不正确的tensor大小等等。
将尽力向你们展示一些调试技术。但这是最热门的教学内容之一。但最重要的是要有韧性。我发现,在我共事过的人当中,效率高的人与效率不高的人之间最大的区别从来都不是在智力上。一直以来,,坚持下去,基本上,永远,永远不放弃。这种深层次的东西尤其重要,因为你不像普通编程那样获得连续的奖励循环。你要做十二件事才能把你的闪光点展现出来。
变量命名、编码风格哲学等 [ 56:15 - 59:33 ] :
我基于一些编程社区,他们的基本观点是,你在单一类型的屏幕抓取中看到的越多,你就越能,像这样,直观地一次性理解。每次你要看的时候,你的眼睛都要跳来跳去。这有点像环境变化会降低理解能力。Jeremy发现这是一种非常有用的编程风格,一般来说,我尽量减少垂直高度,这样东西就不会滚动出屏幕。
集成开发环境 (IDE) 简介 [ 1:03:13 ]
您可以使用 Visual Studio Code (vscode — Anaconda 最新版本附带的开源编辑器,也可以单独安装)或大多数编辑器和 IDE,以了解有关 open_image功能。 vscode要知道的事情:
就我个人而言,我的观点是isualStudioCode可能是最好的编辑器。它是免费的,开源的。还有其他非常好的例子。好吧,如果你下载了Anaconda的最新版本,它会为你安装VisualStudioCode。它集成在conda中,与你的Python解释器一起设置它,并附带Python扩展和其他所有东西。所以这是个不错的选择。
- 命令面板 (
Ctrl-shift-p) - 选择解释器(用于 fastai env)
- 选择终端外壳
- 转到符号 (
Ctrl-t) - 查找参考 (
Shift-F12) - 转到定义(
F12) - 回去 (
alt-left) - 查看文档
- 隐藏侧边栏 (
Ctrl-b) - zen模式(
Ctrl-k,z)
如果您像我一样在 Mac 上使用 PyCharm 专业版:
- 命令面板 (
Shift-command-a) - 选择解释器(用于 fastai env)(
Shift-command-a然后寻找“口译员”) - 选择终端外壳 (
Option-F12) - 转到符号 (
Option-command-shift-n并键入类名、函数名等。如果是驼峰式或下划线分隔,您可以键入每个位的前几个字母) - 查找参考 (
Option-F7), 下一次出现 (Option-command-⬇︎), 上一次出现 (Option-command-⬆︎) - 转到定义(
Command-b) - 回去 (
Option-command-⬅︎) - 查看文档
- 禅模式(
Control-`-4–2或搜索“无干扰模式”)
我们来谈谈 open_image [ 1:10:52 ]
Fastai 使用 OpenCV。 TorchVision 使用 PyTorch 张量进行数据增强等。很多人使用 Pillow PIL. Jeremy 对所有这些进行了大量测试,他发现 OpenCV 比 TorchVision 快 5 到 10 倍。 对于 行星卫星图像竞赛 [ 1:11:55 ],TorchVision 非常慢,以至于他们只能获得 25% 的 GPU 利用率,因为他们正在进行大量的数据增强。 Profiler 显示这一切都在 TorchVision 中。
Pillow 快了很多,但它不如 OpenCV 快,而且也不像线程安全 [ 1:12:19 ]。 Python 有一个叫做全局解释器锁(GIL)的东西,这意味着两个线程不能同时做 Python 的事情——这使得 Python 成为现代编程的蹩脚语言,但我们被它困住了。 OpenCV 发布 GIL。 fast.ai 库如此之快的原因之一是因为它不像其他所有库那样使用多个处理器来进行数据增强——它实际上是使用多个线程。 它可以做多线程的原因是因为它使用了 OpenCV。 不幸的是,OpenCV 有一个难以理解的 API,并且文档有些迟钝。 这就是为什么 Jeremy 试图做到这一点,这样使用 fast.ai 的人就不需要知道它正在使用 OpenCV。 您不需要知道要传递哪些标志来打开图像。 你不需要知道如果读取失败,它不会显示异常——它会静默返回 None.
不要开始使用 PyTorch 进行数据扩充或开始引入 Pillow ——你会发现事情突然变慢了,或者多线程不再工作。 您应该坚持使用 OpenCV 进行处理 [ 1:14:10 ]
更好地使用 Matplotlib [ 1:14:45 ]
接下来我想给你们看的是,关于,我们在整个课程中会用到的重要编码内容,就是更好地使用mapplotLib.
Matplotlib 之所以如此命名,是因为它最初是 Matlab 绘图库的克隆。 不幸的是,Matlab 的绘图库并不出色,但在当时,这是大家都知道的。 在某个时候,matplotlib 的人意识到了这一点,并添加了第二个 API,它是一个面向对象的 API。 不幸的是,因为最初学习 matplotlib 的人都没有学习 OO API,所以他们教下一代人旧的 Matlab 风格的 API。 现在,使用更好、更容易理解和更简单的 OO API 的示例或教程并不多。 因为绘图在深度学习中非常重要,所以我们将在这门课中学习的一件事是如何使用这个 API。
技巧 1:plt.subplots [ 1:16:00 ]
Matplotlib 的 plt.subplots是一个非常有用的用于创建图的包装器wrapper,无论您是否有多个子图。 请注意,Matplotlib 有一个可选的面向对象的 API,我认为它更容易理解和使用(尽管网上很少有例子使用它!)

它返回两件事——你可能不会关心第一个(Figure 对象),第二个是 Axes 对象(或它们的数组)。 基本上你曾经说过的任何地方 plt.某事,你现在说 ax.一些东西,它现在将对那个特定的子图进行绘图。 当您想要绘制多个图时,这很有帮助,以便您可以相互比较。
技巧 2:无论背景颜色如何,可见文本 [ 1:17:59 ]
无论背景如何,使文本可见的一个简单但很少使用的技巧是使用带有黑色轮廓的白色文本,反之亦然。 这是在 matplotlib 中的操作方法。
Largest item classifier 最大项目分类器 [ 1:22:57 ]
与其试图一次性解决所有问题,不如让我们不断进步。 我们知道如何在每张图像中找到最大的物体并对其进行分类,所以让我们从那里开始。 Jeremy 参加 Kaggle 比赛的方式是每天半小时 [ 1:24:00 ]。 在那半小时结束时,提交一些东西并尝试使它比昨天的更好一点。
Jeremy在几个月前开始准备这门课之前并没有太多的经验来做这种目标检测的东西。我想获得这种感觉,尽管这是深度学习,持续进步。那么,我能做些什么呢?好吧,我找出每张图片中最大的物体然后分类?我知道怎么做,对吧?所以这是我发现的最大的问题之一,尤其是对那些年纪最小的学生来说,当他们想出他们想要的整个大解决方案时,通常会涉及到很多以前没有人尝试过的新的推测性想法。他们花了6个月的时间来做这件事,但是在演讲的前一天,什么都没用。这个小组就在其他地方,就像我之前说过的我参加当地比赛的方法一样,大概每天半个小时。在这半小时的最后,提交一些正确的东西,并努力使它比昨天更好。所以我在准备这节课的时候也试着做了同样的事情,对吧?那就是,尝试创造一些比持久更好的东西。
我们需要做的第一件事是遍历图像中的每个边界框并获得最大的一个。
一种 lambda 函数 内联定义匿名函数的方法。 在这里,我们使用它来描述如何对每个图像的注释进行排序——通过边界框大小(降序)。
现在我们有一个从图像 id 到单个边界框的字典——该图像的最大边界框。
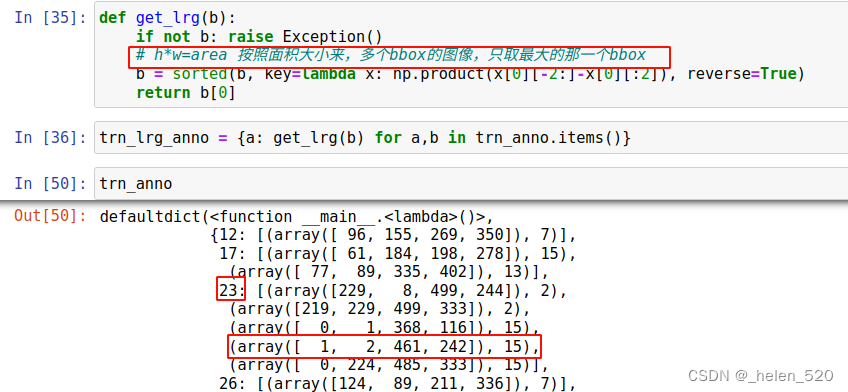
当您有任何类型的处理管道时,您需要查看每个阶段 [ 1:28:01 ]。 假设你做的每件事在你第一次做的时候都是错的。
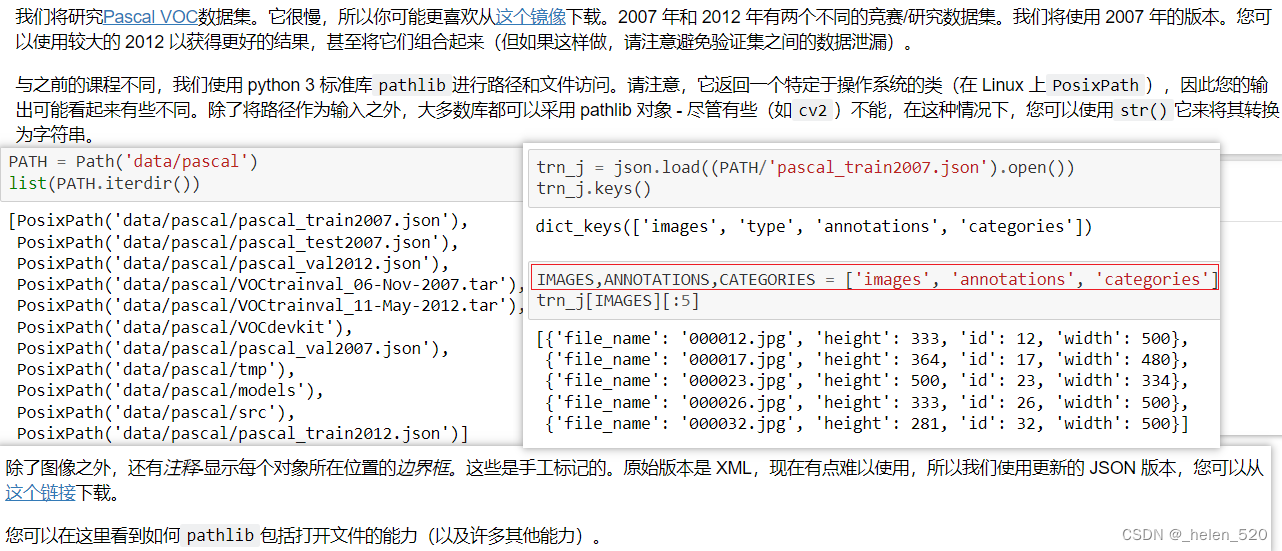
通常最简单的方法是简单地创建要建模的数据的 CSV,而不是尝试创建自定义数据集 [ 1:29:06 ]。 在这里,我们使用 Pandas 帮助我们创建图像文件名和类的 CSV。 columns=[‘fn’,’cat’]是否存在,因为字典没有顺序并且列的顺序很重要。
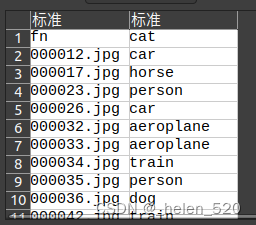
让我们看看这个[ 1:30:48 ]
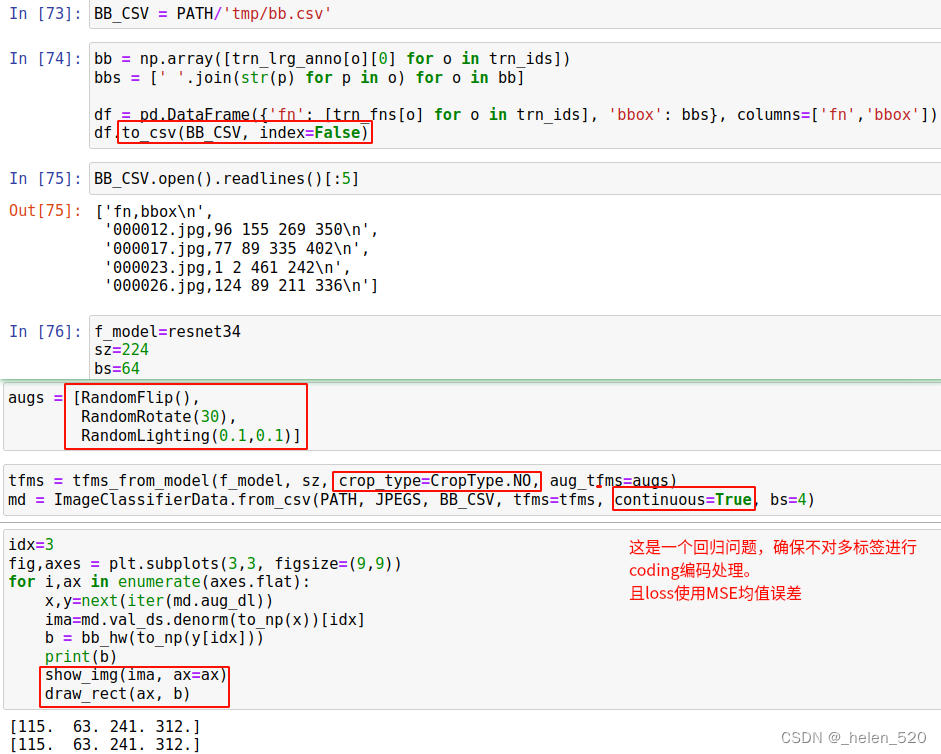
- 不同的一件事是
crop_type. 在 fast.ai 中创建 224 x 224 图像的默认策略是首先调整其大小,使最小边为 224。然后在training期间进行random crop随机平方裁剪。 在valid期间,我们采用中心裁剪center crop,除非我们使用数据增强。之前的分类任务是这样的。 - 但对于目标检测任务,对于边界框bbox,我们不想这样做,因为与图像网络不同,我们关心的东西几乎在中间并且非常大,目标检测中的很多东西非常小并且靠近边缘。 所以我们可以把它剪掉,那就不好了。通过设置
crop_type至CropType.NO,它不会裁剪,因此,为了使它成为方形,它会挤压它 [ 1:32:09 ]。 一般来说,如果你裁剪而不是挤压,许多计算机视觉模型的效果会更好一些,但如果你挤压它们,它们仍然可以很好地工作。 在这种情况下,我们绝对不想裁剪,所以这很好。 所以你会看到这个看起来有点奇怪的宽,对吧?那是因为他是像这样被压扁的。
这里,我想再看一下数据加载器。
数据加载器 [ 1:33:04 ]
您已经知道在模型数据对象内部,我们有很多东西,包括训练数据加载器和训练数据集。 关于数据加载器的主要知识是它是一个迭代器,每次你从中获取下一次迭代的东西时,你都会得到一个小批量。 你得到的小批量是你要求的任何大小,默认情况下批量大小是 64。在 Python 中,你从迭代器中获取下一个东西的方式是使用 next ,next(md.trn_dl)。但你不能这样做。 你不能这么说的原因是你需要说“现在开始一个新的时代”。 通常,不仅在 PyTorch 中,对于任何 Python 迭代器,您都需要说“请从序列的开头开始”。 说你这样做是为了使用 iter(md.trn_dl)这将抓住一个迭代器 md.trn_dl——特别是我们稍后会了解到,这意味着这个类必须定义一个 __iter__方法返回一些不同的对象,然后有一个 __next__方法。
如果您只想抓取一批,这就是您的操作方式( x:自变量, y:因变量):
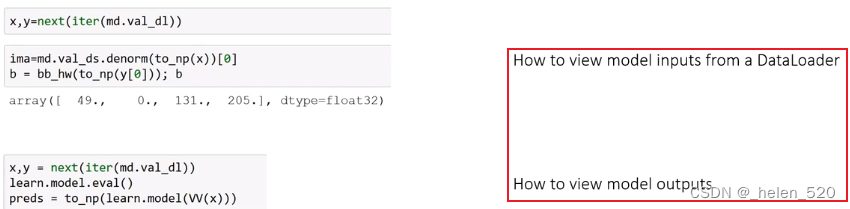
我们不能直接发送给 show_image[ 1:35:30 ]。 例如, x不是 numpy 数组,不在 CPU 上,而且形状全错( 3x224x224)。 此外,它们不是介于 0 和 1 之间的数字,因为所有标准 ImageNet 预训练模型都希望我们的数据已经标准化为具有零均值和 1 标准差。

如您所见,已经对输入进行了大量处理,以准备将其传递给预训练模型。 所以我们有一个函数叫做 denorm用于非规范化并修复维度顺序等。由于非规范化取决于变换 [ 1:37:52 ],并且数据集知道用于创建它的变换,所以这就是你必须这样做的原因 md.val_ds.denorm并在将小批量转换为 numpy 数组后传递:
show_img(md.val_ds.denorm(to_np(x))[0]); 使用 ResNet34 进行训练 [ 1:38:36 ]
我们有意删除了前几个点和最后几个点 [ 1:38:54 ],因为最后几个点通常会射向无穷远,以至于你什么都看不到,所以这通常是个好主意。 但是当您的小批量很少时,这不是一个好主意。 当您的 LR 查找器图如上所示时,您可以在每一端要求更多点(您也可以使批量大小非常小):
learn.lr_find曲线,为了找下降速度最快的学习率,大约在:2e-2的位置。
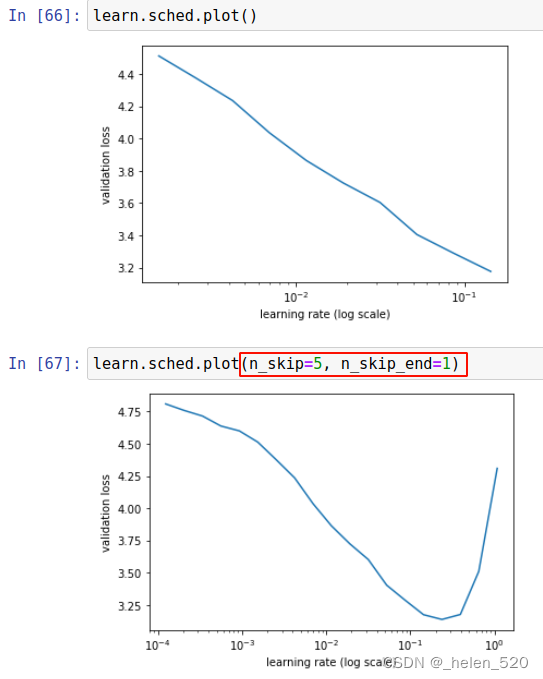
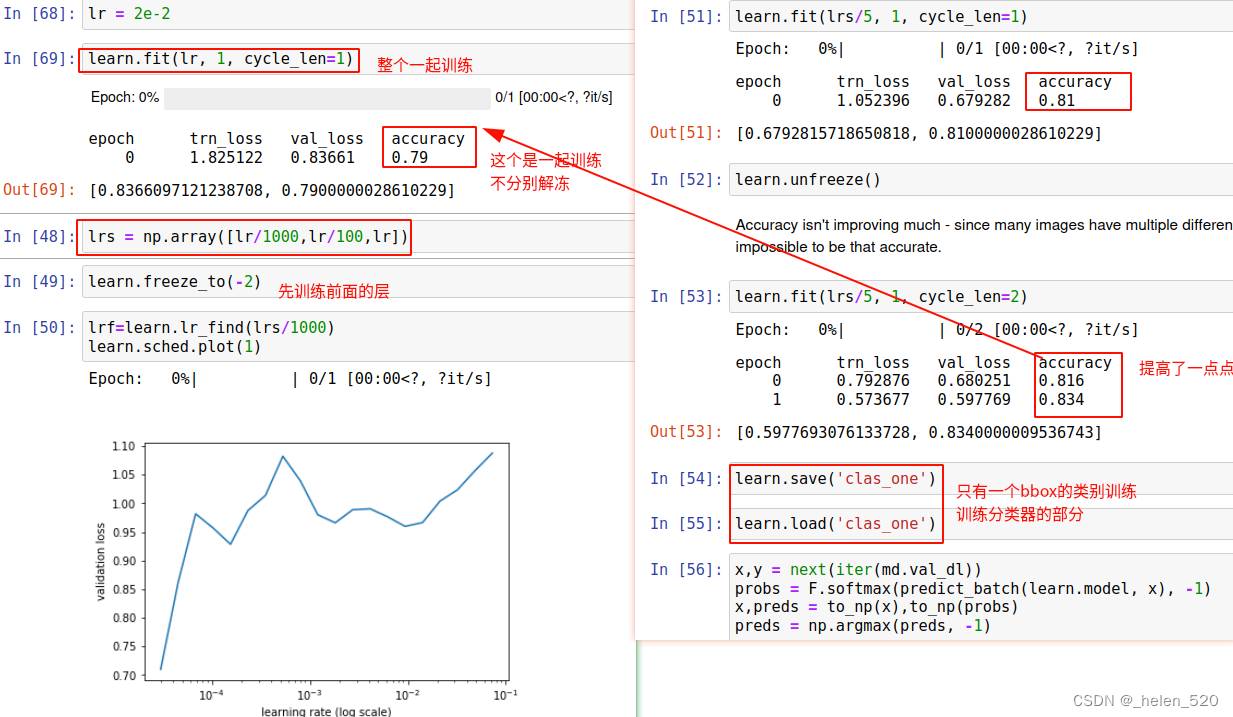
准确性并没有提高多少——因为许多图像有多个不同的对象,所以不可能做到那么准确。
让我们看看分类的结果 [ 1:40:48 ]
如何理解不熟悉的代码:
- 逐步运行每一行代码,打印出输入和输出。
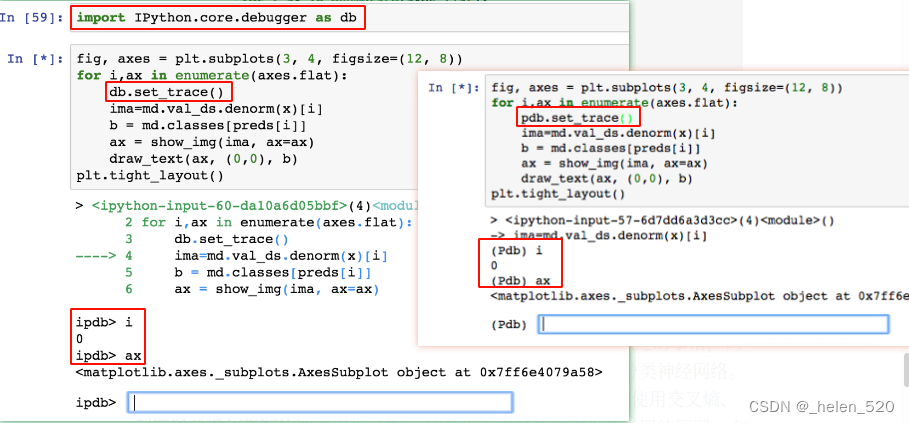
方法1 [ 1:42:28 ]:您可以获取循环的内容,复制它,在其上方创建一个单元格,粘贴它,取消缩进,设置 i=0并将它们全部放在单独的单元格中。
方法 2 [ 1:43:04 ]:使用 Python 调试器 。您可以使用 python 调试器 pdb逐步执行代码。
pdb.set_trace()设置断点%debug跟踪错误的魔法(发生异常后)

创建边界框 [ 1:52:51 ] how to locate the largest object in each image?
在最大的对象周围创建一个边界框可能看起来像是您以前没有做过的事情,但实际上它完全是您以前做过的事情。 我们可以创建回归而不是分类神经网络。 分类神经网络是具有 sigmoid 或 softmax 输出的神经网络,我们使用交叉熵、二元交叉熵或负对数似然损失函数。 这基本上就是使它成为分类器的原因。 如果我们最后没有 softmax 或 sigmoid 并且我们使用均方误差作为损失函数,那么它现在是一个预测连续数字而不是类别的回归模型。 我们也知道我们可以有多个输出,比如行星竞赛(多重分类)。 如果我们结合这两个想法并进行多列回归multiple column regression呢?
这就是您将其视为可微编程的地方。 这不像“我如何创建边界框模型?” 但它更像是:
- 我们需要四个数字,因此,我们需要一个有 4 个激活的神经网络 x,y,x0,y0
- 对于损失函数,当它较低时意味着四个数字更好的函数是什么? 我们不适用sigmoid函数,而是使用均方损失函数!
而已。 让我们试试看。
Bbox Only [ 1:55:27 ]
现在我们将尝试找到最大对象的边界框。 这只是一个有 4 个输出的回归。 所以我们可以使用带有多个“标签”的 CSV。 如果您记得第 1 部分中进行多标签分类,则您的多个标签必须用空格分隔,并且文件名用逗号分隔。
令continuous=True告诉 fastai 这是一个回归问题,这意味着它不会一次性对标签进行编码,而是使用 MSE 作为默认的 loss function。
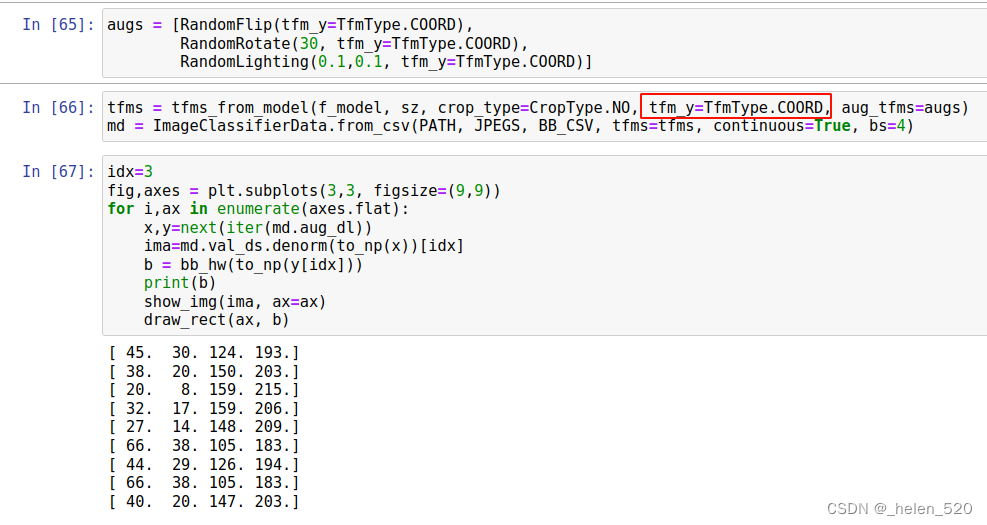
请注意,我们必须告诉变换构造函数transform我们的标签是坐标coordinates,以便它可以正确处理变换。
此外,我们使用 CropType.NO 是因为我们想将矩形图像“挤压”成正方形,而不是中心裁剪,这样我们就不会意外裁剪掉一些对象。 (这在诸如 imagenet 之类的东西中问题不大,其中有一个要分类的对象,而且它通常很大并且位于中心位置)。
我们将看看 TfmType.COORD下周,但现在,请意识到当我们进行缩放和数据增强时,这需要发生在边界框上,而不仅仅是图像。
bbox随着图像的变化要跟着变化,就是这个差别。
让我们基于 ResNet34 [ 1:56:57 ] 创建一个卷积网络:
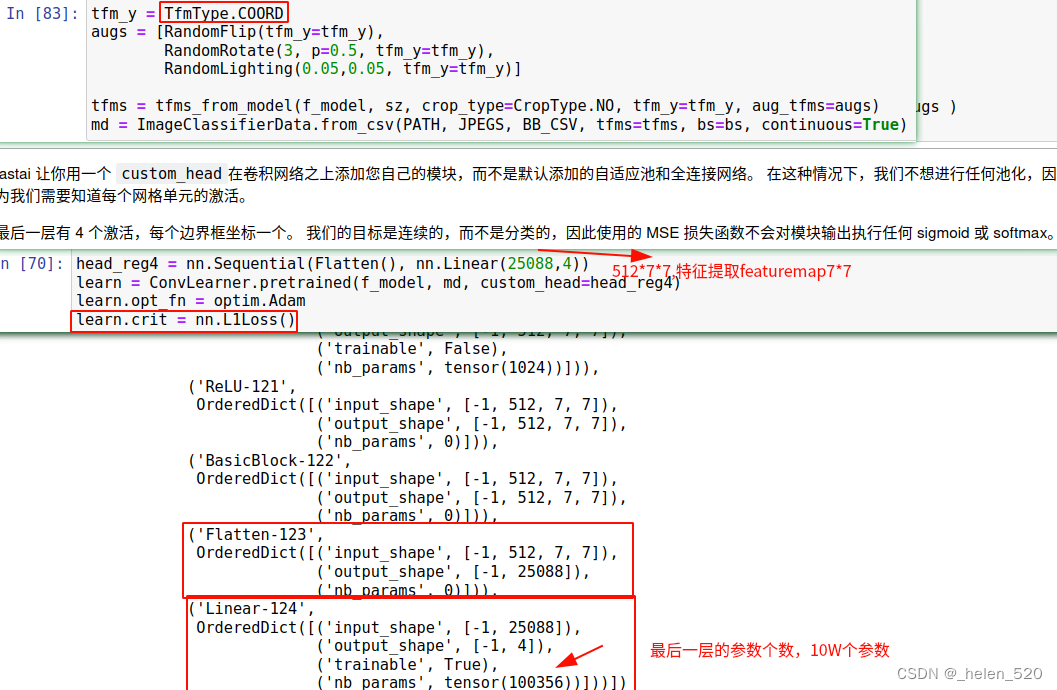
fastai 让您使用 custom_head在卷积网络CNN之上添加您自己的模块,而不是默认添加的自适应池adaptivepool和全连接网络。 在这种情况下,我们不想进行任何池化,因为我们需要知道每个网格单元的激活。
最后一层有 4 个激活,每个边界框坐标一个。 我们的目标是连续的,而不是分类的,因此使用的 MSE 损失函数不会对模块输出执行任何 sigmoid 或 softmax。
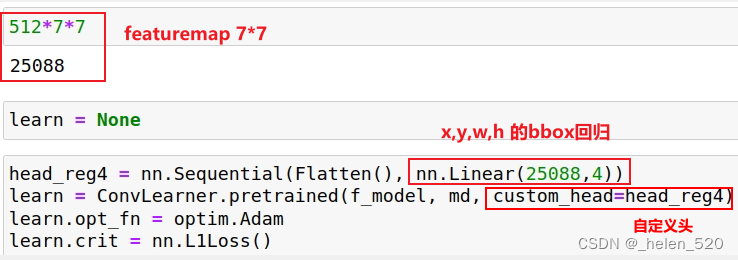
Flatten(): 通常上一层有7x7x512在 ResNet34 中,因此将其展平为长度为 25088 的单个向量L1Loss[ 1:58:22 ]:不是将平方误差相加,而是将误差的绝对值相加。 这通常是您想要的,因为将平方误差相加确实会过多地惩罚错误。 所以 L1Loss 通常更适合使用。
看看结果 [ 1:59:18 ]
我们将在下周对此进行更多修改。 在这堂课之前,如果有人问你“你知道如何创建边界框模型吗?”,你可能会说“不,没有人教过我这个”。 但问题实际上是:
- 你能创建一个有 4 个连续输出的模型吗? 是的。
- 如果这 4 个输出接近 4 个其他数字,你能创建一个更低的损失函数吗? 是的
然后你就完成了。
当你往下看时,它开始看起来有点糟糕——只要我们有多个目标,结果就看起来有点糟糕。 这并不奇怪。 总的来说,它做得很好。

lesson9 目标检测
- fastai2018 part2 lesson8-9是目标检测专题。但是dl2的jupyter notebook全是基于fastai0.7的版本的。
- jav将这些在fastai1的版本中实现了,并进行了优化,有三个版本v1,v2,v3三个版本,还加上了新的数据增强的方法。
- SSD Object Detection in V1 - #14 by joseadolfo - fastai users - Deep Learning Course Forums
- Howard 教授在 2018 年高级课程(第 2 部分)中展示了 SSD Single Shot Object Detection 的示例。这是一个非常有趣但很复杂的笔记本;不幸的是,它是用 Fastai V0.7 编写的。
- 我已将 SSD 笔记本移植到 Fastai V1 中,效果非常好。您可以在我的 GitHub 中找到它,网址为https://colab.research.google.com/github/jav0927/course-v3/blob/master/SSD_Object_Detection.ipynb 212
- 这是课程中最具挑战性的模型,也是一个很好的学习工具。我希望它对社区有价值。在开发模型时,我受到了 Henin 之前工作的启发。
今天,我们将继续学习目标检测,这意味着对于照片中的每个目标,在20个类中,我们将尝试找出目标是什么以及它的边界框是什么。这样我们就可以把这个模型应用到一组新的没有标签的数据中并把这些标签加进去。我们要使用的一般方法是,先从简单开始,然后逐渐将其复杂化。上周我们从一个简单的分类器开始,三行代码分类器。然后我们让它变得稍微复杂一些,把它变成一个没有分类器的边界框。今天,我们要把这两块拼在一起,做成一个分类器外加一个Bbox。所有这些都是针对单个最大的物体,然后从那里开始,我们将构建一些更接近我们最终目标的东西。这是我们的最终目标。
目前应该理解的内容有:① Pathlib、Jason;② 字典;③ 默认字典;④如何跳转fastai源码;⑤ Matplotlib ⑥ lambda函数 ⑦ bbox坐标;⑧ custom head;Bbox回归;⑨ 如何从Dataloader中观察模型输入; ⑩ 如何观察模型的输出
数据增强和边界框 [ 2:58 ]
Awkward rough edges of fastai:
分类器的因变量是分类或二项式。与回归相反,回归的因变量都是连续的。命名有点混乱,但将来会整理出来。在这里,continuous是True因为我们的因变量是边界框的坐标——因此这实际上是一个回归数据。
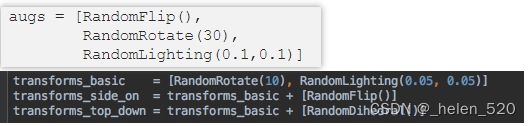
让我们创建一些数据增强 [ 4:40 ]
通常,我们使用 Jeremy 为我们创建的这些快捷方式,但它们只是随机增强的列表。但是您可以轻松创建自己的(如果不是全部的话,大多数都以“随机”开头)。
如您所见,图像旋转并且光照变化,但边界框没有移动并且位于错误的位置[ 6:17 ]。当您的因变量是像素值或以某种方式连接到自变量时,这就是数据扩充的问题——它们需要一起扩充。正如您在边界框坐标中看到的那样[ 115. 63. 240. 311.],我们的图像是 224 x 224 - 所以它既没有缩放也没有裁剪。因变量需要经过所有几何变换作为自变量。
为此 [ 7:10 ],每个转换都有一个可选tfm_y参数:
TrmType.COORD表示y值代表坐标。这需要添加到所有增强以及tfms_from_model负责裁剪、缩放、调整大小、填充等的增强中。
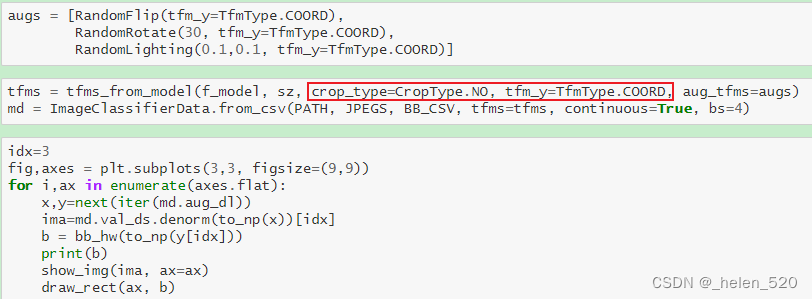
现在,边界框随着图像移动并位于正确的位置。您可能会注意到,有时它看起来很奇怪,就像底行的中间一样。这是我们所拥有的信息的约束。如果物体占据了原始边界框的角落,则图像旋转后您的新边界框需要更大。所以你必须小心不要对边界框进行太高的旋转,因为没有足够的信息让它们保持准确。如果我们在做多边形或分割,我们就不会有这个问题。
所以在这里,我们最多旋转 3 度来避免这个问题 [ 9:14 ]。它也只旋转一半的时间 ( p=0.5)。

custom_head [ 9:34 ]
llearn.summary()将通过模型运行一小批数据,并打印出每一层的张量大小。如您所见,在Flatten图层之前,张量的形状为 512 x 7 x 7。因此,如果它是 1 阶张量(即单个向量),其长度将为 25088 (512 * 7 * 7),并且这就是为什么我们的自定义标头的输入大小为 25088。输出大小为 4,因为它是边界框坐标。
单个目标检测 [ 10:35 ]
让我们将两者结合起来,创建可以对每个图像中最大的对象进行分类和定位的东西。
训练神经网络需要做三件事:
- 数据
- 网络架构
- 损失函数
1. 提供数据
我们需要一个ModelData对象,其自变量是图像,因变量是边界框坐标和类标签的元组。有几种方法可以做到这一点,但 Jeremy 想出的一种特别懒惰和方便的方法是创建两个 ModelData对象,代表我们想要的两个不同的因变量(一个带有边界框坐标,一个带有类别)。

我们必须denorm先从数据加载器中获取图像,然后才能绘制它们。

2. 选择架构 [ 13:54 ]
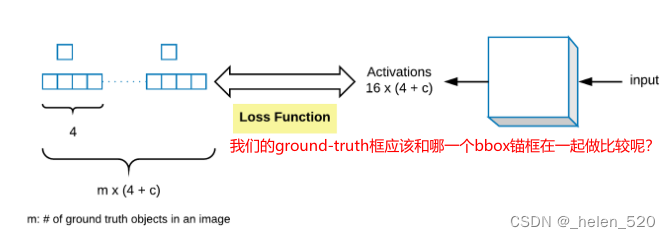
该架构将与我们用于分类器和边界框回归的架构相同,但我们只是将它们结合起来。换句话说,如果我们有c类,那么我们在最后一层需要的激活数是 4 plus c。4 用于边界框坐标和c概率(每类一个)。
这次我们将使用一个额外的线性层,加上一些 dropout,来帮助我们训练一个更灵活的模型。一般来说,我们希望我们的cunstom head能够自行解决问题,如果它连接到的预训练主干pretrained backbone是合适的。所以在这种情况下,我们正在尝试做很多事情——分类器和边界框回归,所以仅仅单个线性层似乎还不够。如果你想知道为什么BatchNorm1d在第一个之后没有ReLU,ResNet 主干已经BatchNorm1d作为它的最后一层。
3. 损失函数 [ 15:46 ]
损失函数需要查看这些4 + len(cats)激活并确定它们是否良好——这些数字是否准确地反映了图像中最大物体的位置和类别。我们知道如何做到这一点。对于前 4 次激活,我们将像之前一样使用 L1Loss(L1Loss 就像一个均方误差——而不是平方误差之和,它使用绝对值之和)。对于其余的激活,我们可以使用交叉熵损失。
问题:作为一般规则,将 BatchNorm 放在 ReLU [ 18:02 ]之前还是之后更好?Jeremy 建议将其放在 ReLU 之后,因为 BathNorm 旨在朝着零均值一标准差的方向发展。因此,如果您将 ReLU 放在它之后,您会将其截断为零,因此无法创建负数。但是如果你把 ReLU 放在 BatchNorm 上,它确实有这个能力,并且给出了稍微好一点的结果。话虽如此,这两种方式都不是什么大不了的事。您会在这部分课程中看到,大多数时候,Jeremy 使用 ReLU 然后 BatchNorm,但有时当他想与论文保持一致时,他会做相反的事情。
ReLU和batch norm的顺序,是CRB好?还是CBR好?最好还是CRB好。因为BN是为了将N(0,1),如果先做BN,ReLU会截断为0的部分,导致负数丢失了。
问题:在 BatchNorm 之后使用 dropout 背后的直觉是什么?BatchNorm 不是已经很好地归一化了 [ 19:12 ] 吗?BatchNorm 在正则化方面做得很好,但如果你回想第 1 部分,当我们讨论我们为避免过度拟合所做的一系列事情时,添加 BatchNorm 就是其中之一,数据增强也是如此。但是你仍然很可能会过度拟合。dropout的一个好处是它有一个参数来说明dropout的数量。dropout参数是非常重要的参数,它决定了正则化的程度,因为它可以让您构建一个很好的大参数化模型,然后决定对其进行正则化的程度。杰里米往往总是从p=0然后当他添加正则化时,他可以更改 dropout 参数,而不必担心是否保存了一个他希望能够将其加载回来的模型,但是如果他在一个中有 dropout 层但在另一个中没有,它将不再加载. 所以这种方式,它保持一致。
现在我们有了输入和目标,我们可以计算 L1 损失并添加交叉熵 [ 20:39 ]:
F.l1_loss(bb_i, bb_t) + F.cross_entropy(c_i, c_t)*20
这是我们的损失函数。交叉熵和 L1 损失可能具有截然不同的规模——在这种情况下,在损失函数中,较大的将占主导地位。在这种情况下,Jeremy 打印出这些值并发现如果我们将交叉熵乘以 20,它们的比例就会大致相同。
在训练时打印出信息很不错,因此我们获取了 L1 损失并将其添加为指标。
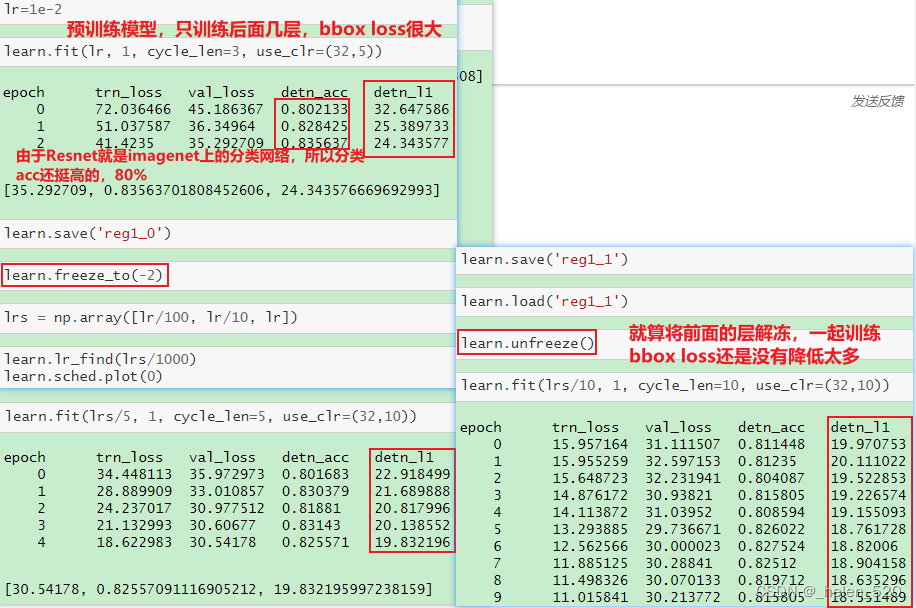
检测精度在 80% 左右,与以前相同。这并不奇怪,因为 ResNet 旨在进行分类,所以我们不希望能够以如此简单的方式改进事物。它当然不是为了做边界框回归而设计的。它实际上是以不关心几何的方式明确设计的——它采用最后 7 x 7 网格的激活并将它们平均在一起,丢弃所有关于一切位置的信息。
resnet网络不是为bbox loss设计的,resnet的网络设计与location位置信息无关。我们只是将最后一层7×7的featuremap平均,然后dropout扔掉了一些。所以,当你只训练最后一层时,bbox loss很糟糕,有24.
同时做bbox回归和分类时,L1loss似乎比只做bbox回归时要好一些。这个不太符合直觉。
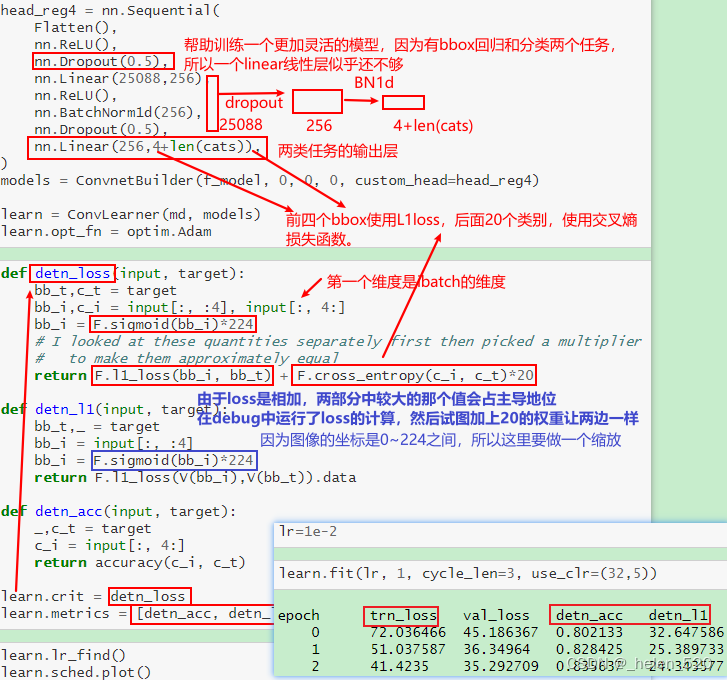
有趣的是,当我们同时做准确率(分类)和边界框时,L1 似乎比我们只做边界框回归时要好一点 [ 22:46]。如果这对你来说是违反直觉的,那么这将是本课之后要考虑的主要事情之一,因为这是一个非常重要的想法。这个想法是这样的——弄清楚图像中的主要对象是什么,这是一个困难的部分。然后找出边界框的确切位置以及它是什么类在某种程度上是容易的部分。因此,当你有一个单一的网络同时说明对象是什么以及对象在哪里时,它将共享有关查找对象的所有计算。所有共享计算都非常高效。当我们在类和位置中反向传播错误时,这就是所有有助于计算找到最大对象的信息。所以任何时候你有多个任务,它们共享一些关于这些任务需要做什么来完成他们的工作的概念,他们很可能应该至少共享网络的某些层。今天晚些时候,我们将研究一个模型,其中除了最后一层之外,大部分层都是共享的。
这是结果 [ 24:34 ]。和以前一样,当图像中有单个主要对象时,它会做得很好。
一个网络同时做bbox回归和分类,这两个任务将共享所有的计算(backbone),这些共享计算都非常高效。分类的计算和bbox误差在方向传播过程中会互相帮助。
所以任何时候当你有多个任务,这些任务共享一些概念,这些任务需要做什么来完成它们的工作,很可能它们应该共享至少一些网络层。
多标签分类 [ 25:29 ]
我们希望继续构建比上一个模型稍微复杂一些的模型,这样如果某些东西停止工作,我们就能准确地知道它在哪里坏了。以下是上一个笔记本中的函数:
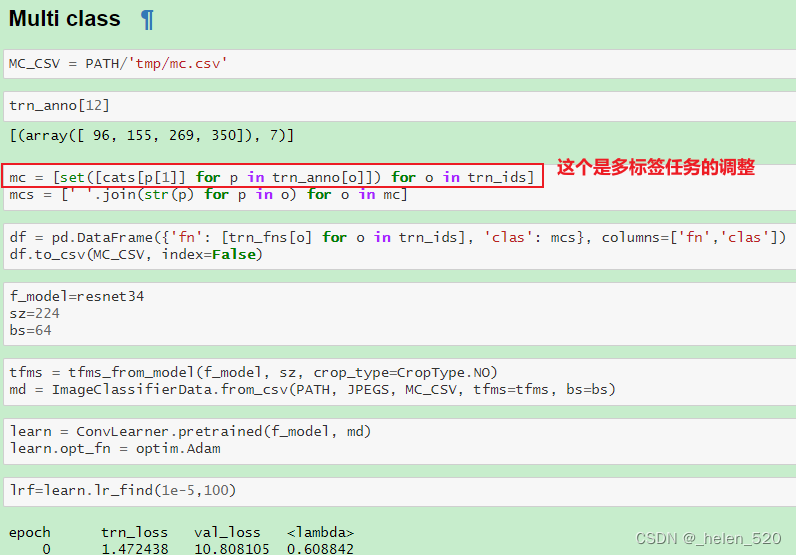
一位学生指出,通过使用 Pandas,我们可以做的事情比使用collections.defaultdict和分享这个要点要简单得多。你对 Pandas 了解得越多,你就越经常意识到它是解决许多不同问题的好方法。
问题:当您在较小的模型上逐步构建时,您是否将它们重用为预训练的权重?还是你把它扔掉然后从头开始重新训练[ 27:11 ]?当 Jeremy 这样做时,他通常会倾向于扔掉,因为重复使用预先训练的权重会引入不必要的复杂性。然而,如果他试图达到可以训练真正大图像的程度,他通常会从小得多的开始,并经常重复使用这些权重。
SSD 和 YOLO [ 29:10 ]
我们有一个输入图像,它通过一个卷积网络输出一个大小为4+c维的向量c=len(cats)。这为我们提供了一个针对单个最大对象的对象检测器。现在让我们创建一个可以找到 16 个对象的对象。这样做的明显方法是采用最后一个线性层,而不是有4+c输出,我们可以有16x(4+c)输出。这给了我们 16 组类概率和 16 组边界框坐标。然后我们只需要一个损失函数来检查这 16 组边界框是否正确地表示了图像中最多 16 个对象(稍后我们将进入损失函数)。
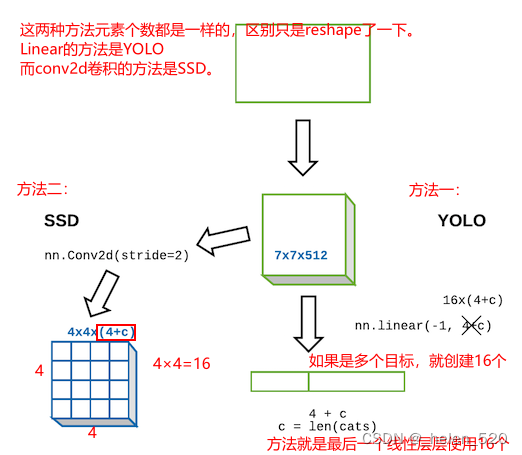
第二种方法不是使用nn.linear,如果相反,我们从我们的 ResNet 卷积骨干网中提取并添加一个nn.Conv2d步幅为 2 [ 31:32 ] 的方法?这将给我们一个4x4x[# of filters]张量 - 在这里让4x4x(4+c)我们得到一个张量,其中元素的数量正好等于我们想要的元素数量。现在,如果我们创建一个损失函数,它采用4x4x(4+c)张量并将其映射到图像中的 16 个对象,并检查每个对象是否被这些4+c激活正确表示,这也可以。事实证明,这两种方法实际上都在使用 [ 33:48 ]。输出是来自完全连接的线性层的一个大长向量的方法被一类模型使用,称为YOLO(你只看一次),在其他地方,卷积激活的方法被模型使用,这些模型从称为SSD(单次检测器)的东西开始。由于这些东西在 2015 年底出现的时间非常相似,所以事情非常转向 SSD。所以今天早上,YOLO 版本 3出来了,现在正在做 SSD,这就是我们要做的。我们还将了解为什么这也更有意义。
- Part 2 Lesson 9 wiki - #375 by chloews - Part 2 & Alumni (2018) - fast.ai Course Forums
- https://forums.fast.ai/t/part-2-lesson-9-wiki/14028/375
- 这个就是SSD的网络架构。
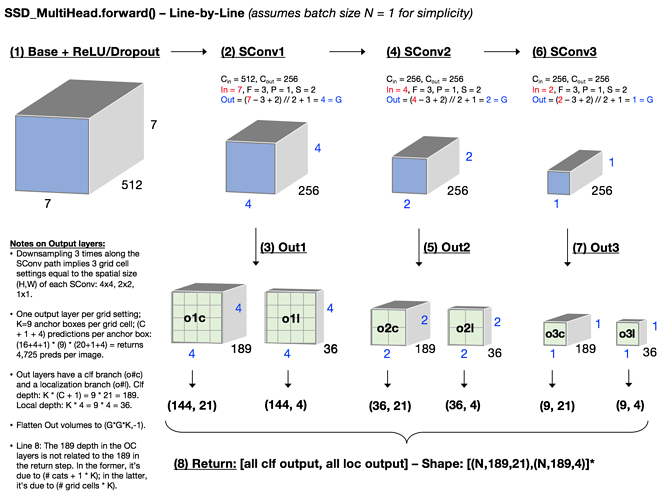
锚框 anchor box [ 35:04 ]
让我们假设我们有另一个Conv2d(stride=2)然后我们会有2x2x(4+c)张量。基本上,它正在创建一个看起来像这样的网格:
这就是第二个额外conv stride= 2 的激活几何形状。请记住,stride= 2的卷积对激活几何的作用与步幅 1 卷积后跟最大池化(假设填充没问题)相同。
让我们谈谈我们可以在这里做什么 [ 36:09 ]。我们希望这些网格单元中的每一个都负责在图像的该部分中找到最大的对象。
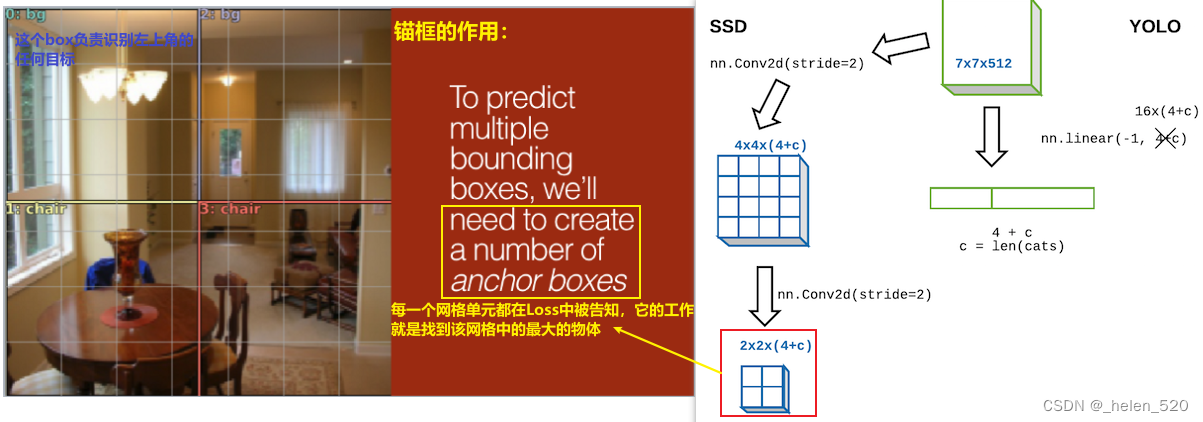
感受野 [ 37:20 ]
为什么我们关心我们希望每个卷积网格单元负责查找图像对应部分中的东西的想法?
- 原因是因为那个卷积网格单元的感受野。基本思想是,在整个卷积层中,这些张量的每一部分都有一个感受野,这意味着输入图像的哪一部分负责计算该单元格。就像生活中的所有事物一样,查看这一点的最简单方法是使用 Excel [ 38:01 ]。Excel的下载地址为:https://github.com/fastai/fastai1/blob/master/courses/dl2/xl/dl-examples.xlsx
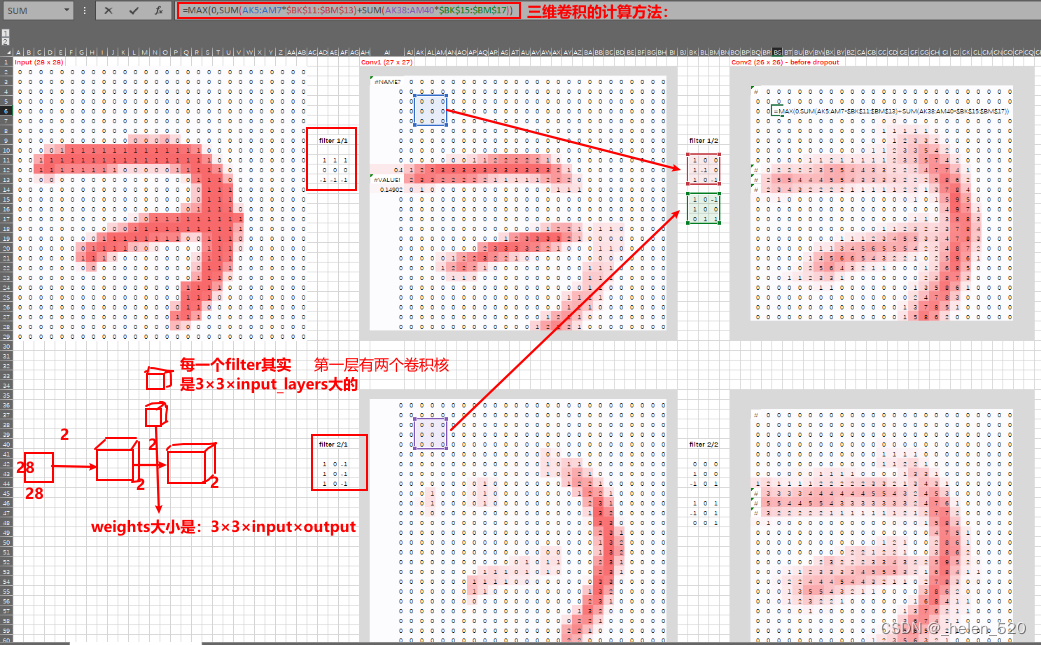
进行一次激活(在本例中是在 maxpool 层),让我们看看它是从哪里来的 [ 38:45 ]。在 excel 中,您可以执行公式 → 跟踪先例Trace。一直追溯到输入层,您可以看到它来自图像的这 6 x 6 部分(以及滤波器)。更重要的是,中间部分有很多权重从外面的其他cell只有一个重量出来。所以我们把这个 6 x 6 的cell称为我们选择的一个激活元的感受野。
这个maxpool的激活元,来自2×2的卷积层,2×2的卷积层,来自上一层的4×4的卷积层,4×4的卷积层来自上一层6×6的输入层。

请注意,感受野不仅仅是说它是这个bbox,而且bbox的中心有更多的依赖关系 [ 40:27 ] 当理解架构和理解为什么卷积网络以它们的方式工作时,这是一个至关重要的概念.
因为这个3×3的kernel的中心赋予了更高的权重。
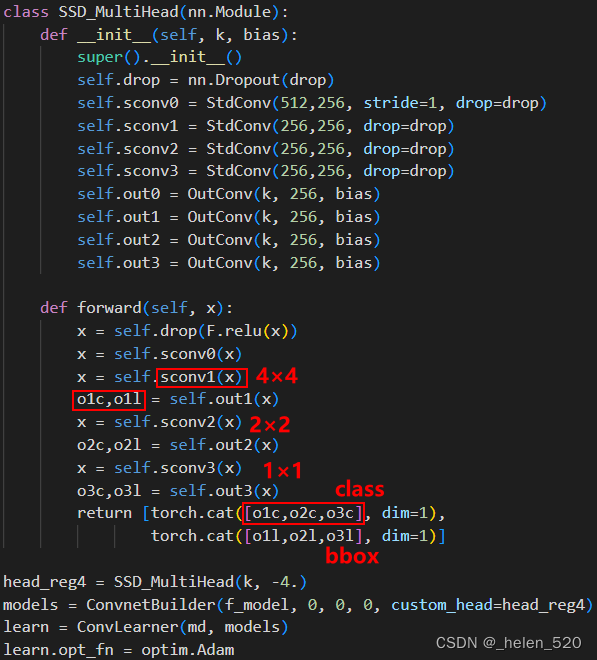
网络架构 [ 41:18 ]
架构是,我们将有一个 ResNet 主干,然后是一个或多个 2D 卷积(目前是一个),这将为我们提供一个4x4网格。

SSD_Head
- 我们从 ReLU 和 dropout 开始
- 然后stride 1卷积。我们从 stride 1 卷积开始的原因是因为它根本不会改变几何结构——它只是让我们添加了一个额外的计算层。它让我们不仅可以创建一个线性层,而且现在我们的自定义头部中还有一个小型迷你神经网络。
StdConv上面定义了——它执行卷积、ReLU、BatchNorm 和 dropout。您看到的大多数研究代码都不会定义这样的类,而是一次又一次地编写整个代码。不要那样。重复的代码会导致错误和理解不佳。 - 步幅 2 卷积 [ 44:56 ]
- 最后,第 3 步的输出是
4x4传递给OutConv.OutConv有两个单独的卷积层,每个都是步幅 1,所以它不会改变输入的几何形状。- 其中一个分类网络的输出:是类数的长度(暂时忽略
k,+1用于“背景”——即没有检测到对象), - 另一个是bbox回归任务:长度是 4。
- 而不是有一个输出的单个 conv 层
4+c,让我们有两个卷积层,并在列表中返回它们的输出。
这允许这些层稍微专业化。我们谈到了这个想法,当你有多个任务时,它们可以共享层,但它们不必共享所有层。
在这种情况下,我们创建分类器和创建和创建边界框回归这两个任务共享除了最后一层之外的每一层。
- 其中一个分类网络的输出:是类数的长度(暂时忽略
- 最后,我们将卷积展平,因为 Jeremy 编写了损失函数以期望展平张量,但我们可以完全重写它以不这样做。
loss函数是两个任务相加,把输出flatten展平就可以了。然后计算loss,就是两个任务一起做 。
Fastai 编码风格[ 42:58 ]
初稿于本周发布。它非常倾向于说明性编程的概念,即编程代码应该是可以用来向理解您的编码方法的人解释一个想法的东西,理想情况下就像数学符号一样容易。这个想法可以追溯到很长一段时间,但在 1979 年的图灵奖演讲中,可能是杰里米最伟大的计算机科学英雄肯·艾弗森 (Ken Iverson) 对它进行了最好的描述。他早在 1964 年之前就一直在研究它,但 1964 年是他发布的这种称为 APL 的编程方法的第一个示例,25 年后,他获得了图灵奖。然后,他将接力棒传给了儿子埃里克·艾弗森。Fastai 风格指南是对其中一些想法的尝试。
损失函数 [ 47:44 ]
损失函数需要查看这 16 组激活中的每一个,每组都有四个边界框坐标和c+1类概率,并决定这些激活是靠近还是远离图像中最靠近该网格单元的对象. 如果什么都没有,那么它是否正确地预测了背景。事实证明这很难做到。
-
。为了预测多个bbox,我们需要建立一系列的锚框。
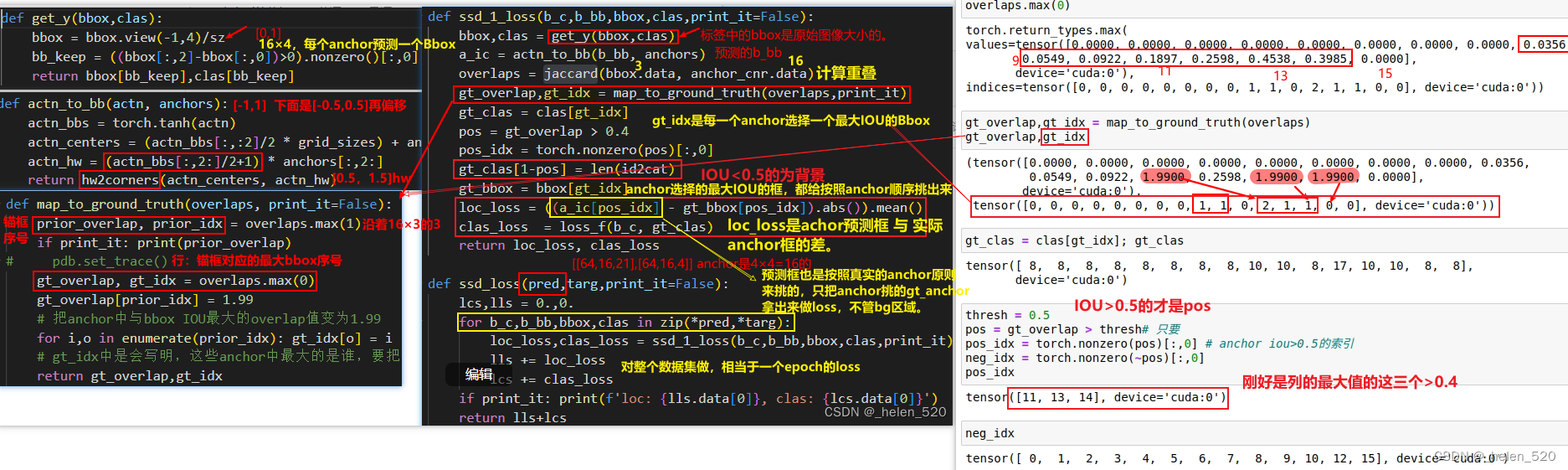
- 几点值得注意的地方:
- ① 在Location loss的计算中,首先是pos_idx,真实的bbox与anchor box做IOU,anchor每行的最大IOU的bbox,作为比较基础。
- ② 将预测框16×4,这16个框只挑出来anchor重叠的那几个框。
- ③ gt_bbox是将真实的bbox重新投影到这些anchor indx中。
- ④ 然后再做差,就是loss。
- 这里面:只有pos_indx的部分,会拿来做loss差;即尽量使得其拟合正确。是不管bg背景区域的!!
- 而且,这里的loc_loss和clas_loss是直接相加的,ssd_loss的return是直接相加的,并没有像之前一样还加权啥的。
匹配问题 [ 48:43 ]
如何设计一个Loss函数,来同时进行分类和bbox回归,既考虑类别,又考虑bbox回归的误差小?
首先简化为2×2的版本,对4×4进行下采样。
- 损失函数需要获取图像中的每个对象并将它们与这些卷积网格单元之一匹配,以说“这个网格单元负责这个特定的对象”,然后它可以继续说“好的,有多接近” 4个坐标以及类概率的接近程度
这是我们的目标 [ 49:56 ]:

我们的因变量看起来像左边的那个,4x4x(c+1)在这种情况下,我们的最终卷积层将是c=20。然后我们将其展平为向量。我们的目标是提出一个函数,该函数接受一个因变量以及一些最终从模型中出来的特定激活集,如果这些激活不能很好地反映真实边界框,则返回更高的数字;或较低的数字,如果它是一个很好的反射。
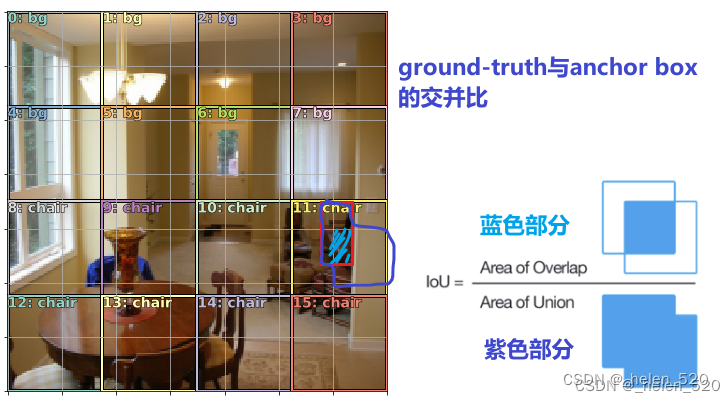
这些bbox,不同的论文称它们为不同的东西。您将听到的三个术语是:锚框、先验框或默认框。我们将坚持使用术语锚框。
我们将为这个损失函数做的是,我们将通过一个匹配问题,我们将获取这 16 个框中的每一个,并查看这三个ground-truth对象中的哪一个与给定正方形 [ 55:21 ]。要做到这一点,我们必须有某种方法来测量重叠量,并且为此提供了一个标准函数,称为Jaccard 指数(IoU)。
- 查看16个anchor box与真实的三个bbox的对应关系,看哪个anchor box与真实的bbox重叠的最多?
- 测量方法是看Jaccard指数:也就是IOU
我们将通过并找到三个对象中的每个对象与 16 个锚框中的每个对象的 Jaccard 重叠 [ 57:11 ]。这将给我们一个3x16矩阵。
以下是我们所有锚框的坐标(中心、高度、宽度):
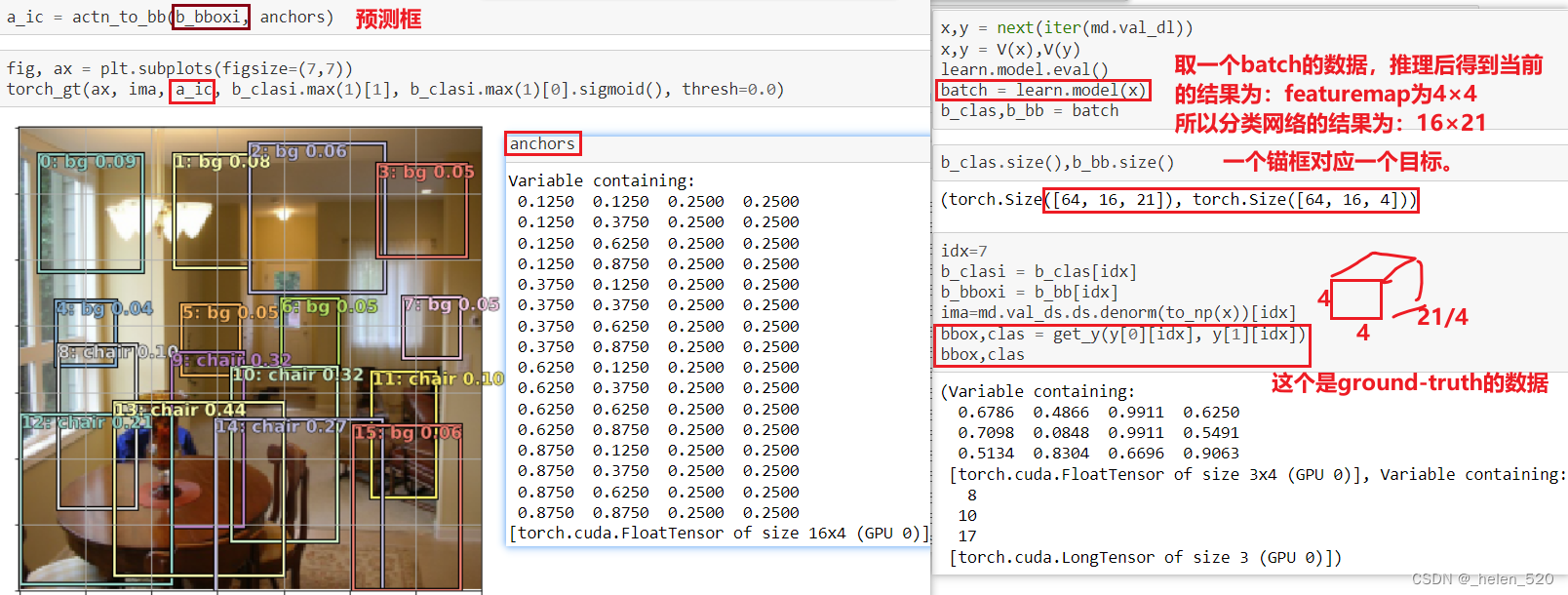
这里特别有趣的是它告诉我们每个网格单元与它重叠最多的真实对象的索引是什么。零在这里有点超载——零可能意味着重叠量为零,或者它的最大重叠与对象索引为零。事实证明这无关紧要,仅供参考。
有一个map_to_ground_truth我们暂时不用担心的函数被调用 [ 59:57 ]。这是超级简单的代码,但考虑起来有点尴尬。基本上,它所做的是以 SSD 论文中描述的方式将这两组重叠组合在一起,将每个锚框分配给一个真实的Bbox。对于其余的锚框,它们被分配给与(按列)至少有 0.5 重叠的任何东西。如果两者都不适用,则认为它是包含背景的单元格。
锚框(行):要么被分配为bbox列的最大IOU;要么被分配IOU>0.5的Bbox序号。其余的锚框都被分配为bg背景。
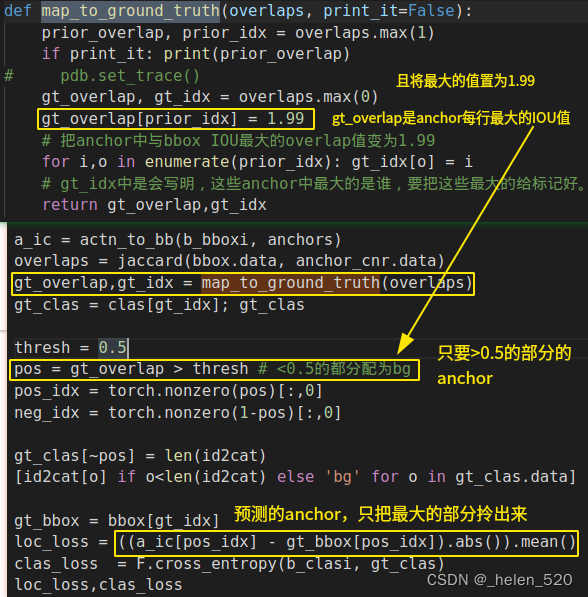
现在您可以看到所有作业的列表 [ 1:01:05 ]。任何有gt_overlap < 0.5分配背景的地方。三个逐行最大锚框具有很高的数量来强制分配。现在我们可以将这些值组合到类中:
然后添加一个阈值0.5,最后得出正在预测的三个类:
这就是匹配阶段 [ 1:02:29 ]。对于 L1 损失,我们可以:
pos_idx = [11, 13, 14]取匹配 ( )的activations 预测框a_ic- 从那些中减去真实边界框 bbox
- 取差值的绝对值
- 取其平均值。
对于分类,我们可以做一个交叉熵:

我们最终会得到 16 个预测的边界框,其中大部分是背景。如果您想知道它根据背景边界框预测了什么,答案是它完全忽略了它。

调整 1. 我们如何解释激活 activation[ 1:04:16 ]?

我们抓住激活,我们坚持它们tanh(记住tanh它的形状与 sigmoid 相同,只是它被缩放到 -1 和 1 之间),这迫使它在那个范围内。然后我们抓取锚框的实际位置,我们将根据激活值除以 2 ( actn_bbs[:,:2]/2) 来移动它们。换句话说,每个预测的边界框可以从其默认位置移动最多 50% 的网格大小。它的高度和宽度也是如此——它可以是默认大小的0.5~1.5倍。
调整 2. 我们实际上使用二元交叉熵损失而不是交叉熵 [ 1:05:36 ]
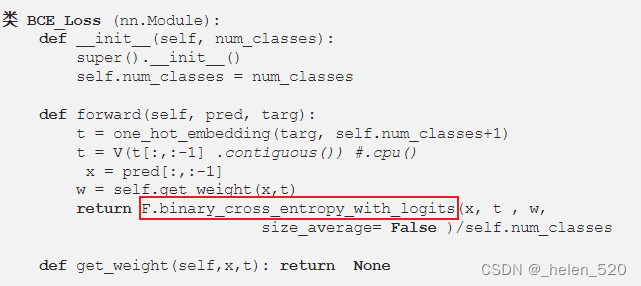
从下面可以看出:背景的anchor box的类别和bbox都不计入到loss函数中的,背景完全被放弃了。所以是随机的,忽略的,不重要的。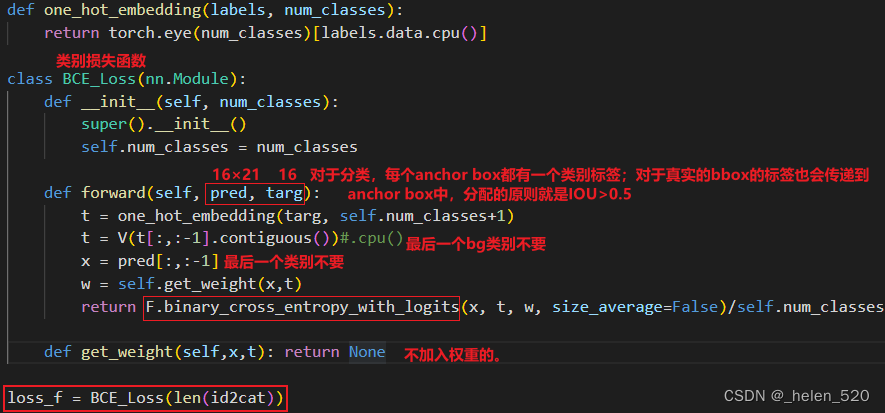
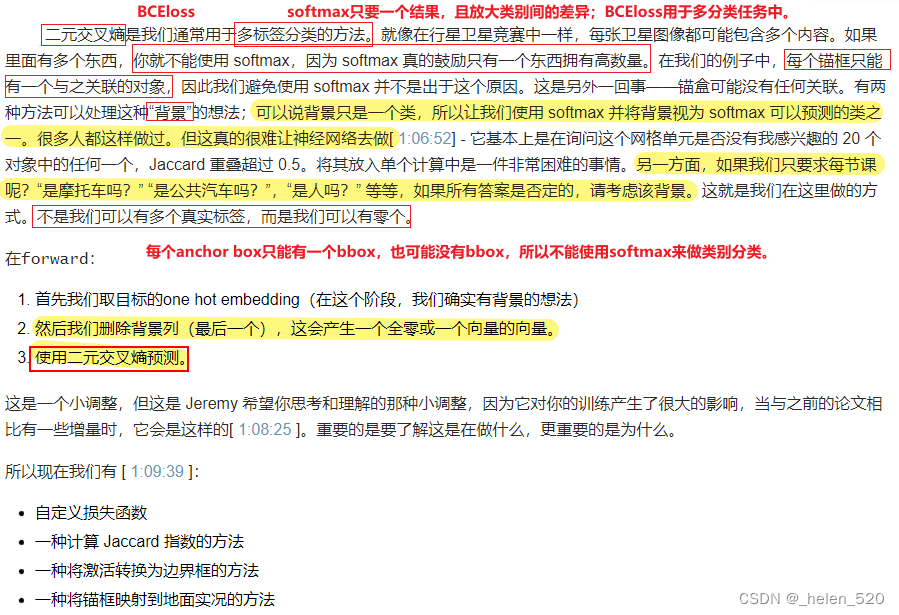
SSD 损失函数 [ 1:09:55 ]
我们设置为标准的ssd_loss函数,它循环遍历小批量中的每个图像并调用ssd_1_loss函数(即一个图像的 SSD 损失)
ssd_1_loss是这一切发生的地方。它从解构bbox和开始clas。让我们仔细看看get_y[ 1:10:38 ]:
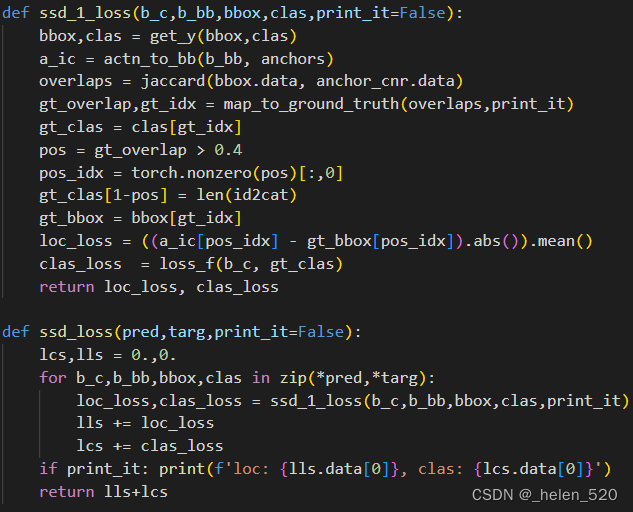
您在 Internet 上找到的许多代码不适用于小批量。它一次只做一件我们不想要的事情。在这种情况下,所有这些函数 ( get_y, actn_to_bb, map_to_ground_truth) 都在工作,而不是一次只处理一个小批量,而是一次处理一大堆ground-truth对象。数据加载器一次被输入一个小批量来执行卷积层。因为我们可以在每个图像中拥有不同数量的ground-truth对象,但张量必须是严格的矩形形状,所以 fastai 会自动用零填充它(任何更短的目标值)[ 1:11:08 ]。这是最近添加的东西并且非常方便,但这确实意味着您必须确保摆脱那些零。所以get_y摆脱任何只是填充的边界框。
- 摆脱填充物
- 将激活转换为边界框anct_to_bb
- 做Jaccard
- 做 map_to_ground_truth
- 检查是否存在大于 0.4~0.5 左右的重叠(不同的论文对此使用不同的值)
- 查找匹配的事物的index索引
- 为不匹配的分配背景类bg
- 然后最后得到定位的 L1 损失,分类的二元交叉熵损失,并返回它们被添加到
ssd_loss
Training [ 1:12:47 ]
在实践中,我们想要去除背景并添加一些概率阈值,但它是在正确的轨道上。盆栽图像,结果并不奇怪,因为我们所有的锚框都很小(4x4 网格)。为了从这里到更准确的东西,我们要做的就是创建更多的锚框。

问题:对于多标签分类,为什么我们不像之前 [ 1:15:20 ] 那样将分类损失乘以一个常数?好问题。这是因为稍后会证明我们不需要。
更多anchors 锚框![ 1:14:47 ]
有 3 种方法可以做到这一点:
- 创建不同大小的锚框(缩放):【0.7,1,1.3】我们在三个缩放级别上有三个纵横比。
- 创建不同纵横比的锚框:1:2,1:1,2:1
- 使用更多的卷积层作为锚框的来源(这些框是随机抖动的,因此我们可以看到重叠的框 [ 1:16:28 ]):
结合这些方法,您可以创建许多锚框(Jeremy 说他不会打印它,但在这里):
一个anchor 9个先验框。
关键概念回顾 [ 1:18:00 ]
- 我们有一个ground-truth向量(一组 4 个边界框坐标和一个类)
- 我们有一个神经网络,它接受一些输入并吐出一些输出激活
- 比较激活和基本事实,计算损失,找到它的导数,并根据导数乘以学习率调整权重。
- 我们需要一个损失函数,它可以获取ground-truth和激活,并吐出一个数字来说明这些激活有多好。为此,我们需要获取每
m个ground-truth,并决定哪一组(4+c)激活负责该对象 [ 1:21:58 ]——我们应该比较哪一组来确定类是否正确和边界框是否正确关闭与否(匹配问题)。 - 由于我们使用的是 SSD 方法,所以我们匹配哪些不是任意的 [ 1:23:18 ]。我们想要匹配的激活集是:锚框的感受野具有真实对象所在位置的最大密度的激活集。
- 损失函数需要是一些一致的任务。如果在第一张图像中,左上角的对象对应于前 4+c 个激活,而在第二张图像中,我们扔东西,突然它现在与最后 4+c 个激活对应,神经网络不知道是什么学习。
- 一旦匹配问题解决了,剩下的就和单目标检测一样了。
架构:
- YOLO——最后一层是全连接的(没有几何的概念)
- SSD——最后一层是卷积层
k(缩放 x 比率)[ 1:29:39 ]
对于每个大小不同的网格单元,我们可以有不同的方向和缩放来表示不同的锚框,这就像概念上的想法一样,每个锚框都与4+c我们模型中的一组激活相关联。所以无论我们有多少锚框,我们都需要有那个(4+c)激活。这并不意味着每个卷积层都需要那么多的激活。因为 4x4 卷积层已经有 16 组激活,2x2 层有 4 组激活,最后 1x1 有一组。所以我们基本上免费得到 1 + 4 + 16。所以我们只需要通过纵横比的数量知道缩放的数量在k哪里。k在其他地方,网格,我们将通过我们的架构免费获得。
模型架构 [ 1:31:10 ]
该模型与我们之前的模型几乎相同。但是我们有许多s= 2 的卷积,它们将带我们进入 4x4、2x2 和 1x1(每个步幅为 2 的卷积在两个方向上将我们的网格大小减半)。
- 在我们进行第一次卷积以达到 4x4 之后,我们将从中获取一组输出,因为我们想要保存 4x4 锚点。
- 一旦我们达到 2x2,我们就抓取另一组现在 2x2 的锚点
- 然后最后我们得到 1x1
- 然后我们将它们连接在一起,这为我们提供了正确的激活次数(每个锚框一个激活)
在这里,我们打印出至少概率为 的那些检测0.2。他们中的一些人看起来很有希望,但其他人则没有那么多。
prefocal打印出来,看看结果:

so,what's wrong??? 所以这里发生的事情会告诉我们很多关于物体检测的历史。
我们需要去看一下目标检测的历史paper,看一下。
物体检测的历史 [ 1:33:43 ]
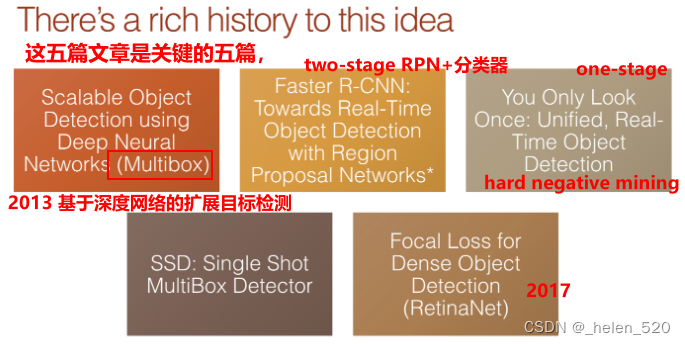
使用深度神经网络的可扩展对象检测 Multibox方法:
- 当人们提到Multibox方法时,他们正在谈论这篇论文。
- 这篇论文提出了一个想法,即我们可以有一个具有这种匹配过程的损失函数,然后你可以使用它来进行对象检测。因此,从那时起,一切都在试图弄清楚如何让它变得更好。
- 与此同时,罗斯·吉尔希克(Ross Girshick)走的是完全不同的方向。他有这两个阶段的过程,第一阶段使用经典的计算机视觉方法来寻找边缘和梯度变化,以猜测图像的哪些部分可能代表不同的对象。然后将它们中的每一个拟合到一个卷积神经网络中,该网络基本上旨在确定这是否是我们感兴趣的对象。
- R-CNN 和 Fast R-CNN 是传统计算机视觉和深度学习的混合体。RPN是用网路的方法替代传统的CV方法。所以有两个网络,一个是RPN网络,一个是分类网络。
- Ross 和他的团队随后所做的是他们采用了 multibox 的想法,并用 conv 网络取代了他们两阶段过程中传统的非深度学习计算机视觉部分。所以现在他们有两个卷积网络:一个用于区域提案(所有可能是对象的东西),第二部分与他早期的工作相同。
YOLO you look only once:统一的实时对象检测
- 在同一时间,这些论文问世了。这两者都做了一些非常酷的事情,即它们实现了与 Faster R-CNN 相似的性能,但只有 1 个阶段。
- 他们采用了 multibox 的想法,并试图弄清楚如何处理混乱的输出。基本的想法是使用,例如,hard negtive mining 负样本挖掘,①他们将通过并找到所有看起来不太好的匹配并将它们丢弃,②使用非常棘手和复杂的数据增强方法,③以及各种黑客。但他们让他们工作得很好。
密集物体检测的焦点损失(RetinaNet)focal loss
- 去年年底发生了一件很酷的事情,这就是所谓的焦点损失。
- 他们实际上意识到了为什么这个乱七八糟的东西不起作用。当我们查看图像时,有 3 种不同粒度的卷积网格(4x4、2x2、1x1)[ 1:37:28 ]。1x1 很可能与某些对象有合理的重叠,因为大多数照片都有某种主要主题。另一方面,在 4x4 网格单元中,16 个锚框中的大多数不会与任何东西有太多重叠。所以如果有人对你说“20 美元的赌注,你认为这个小剪辑是什么?” 而你不确定,你会说“背景”,因为大多数时候,它是背景。
问题:我明白为什么我们有一个 4x4 的感受野网格,每个网格有 1 个锚框来粗略定位图像中的对象。但我认为我缺少的是为什么我们需要多个不同大小的感受野。第一个版本已经包含 16 个感受野,每个感受野都有一个关联的锚框。随着添加,现在有更多的锚框需要考虑。这是因为您限制了感受野可以从其原始大小移动或缩放多少?还是另有原因?[ 1:38:47] 这有点倒退。
Jeremy 进行约束的原因是因为他知道他以后会添加更多的anchor box。但实际上,原因是这些 4x4 网格单元之一和一张图片之间的 Jaccard 重叠,其中占据大部分图像的单个对象永远不会是 0.5。由于对象太大,交集比并集小得多。因此,要使这个总体思路在我们所说的你对重叠超过 50% 的事情负责的情况下发挥作用,我们需要锚框,它会定期有 50% 或更高的重叠,这意味着我们需要有一个各种尺寸、形状和比例。这一切都发生在损失函数中。在所有目标检测中,绝大多数有趣的东西都是损失函数。
- 由于anchor box要与ground-truth box有0.5的重叠,才会有用。
- 但是当目标太大时,4×4的anchor box的IOU重叠太少,
- 所以锚框要在超过0.5重叠下在发挥作用,我们需要很多超过0.5的锚框,这就意味着我们需要各种尺寸、各种形状的锚框。
焦点损失 [ 1:40:38 ]
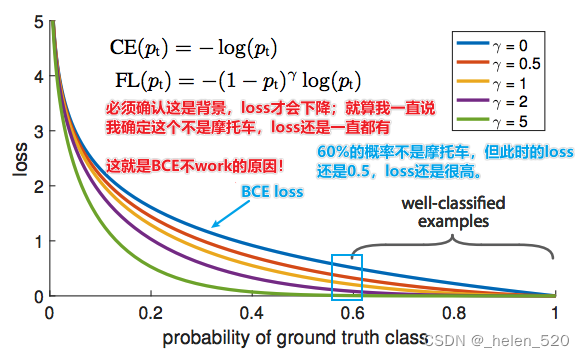
横轴是真实的类别的概率,纵轴是loss函数。
- 关键是第一张照片。蓝线是二元交叉熵损失BCE损失函数。如果答案不是摩托车 [ 1:41:46 ],我用蓝线说“我认为这不是摩托车,我有 60% 的把握”,损失仍然是 0.5 左右,这非常糟糕。因此,如果我们想减少损失,那么对于所有这些实际上是背景的东西,我们必须说“我确定那是背景”,“我确定这不是摩托车、公共汽车或人”——因为如果我不说我们确定不是这些事情中的任何一个,那么我们仍然有loss。
- 只要我不说“我确定是 背景”,都会产生loss。
- 这就是为什么摩托车示例不起作用 [ 1:42:39 ]。因为即使它到达右下角并想说“我认为这是一辆摩托车”,它也没有任何反馈。如果它错了,它就会被杀死。绝大多数时候,它是背景。即使它不是背景,仅仅说“它不是背景”是不够的——你必须说出它是 20 件事中的哪一个。
所以诀窍是试图找到一个看起来更像紫色线的不同损失函数 [ 1:44:00 ]。焦点损失实际上只是一个缩放的交叉熵损失。现在如果我们说“我确定它不是摩托车”,那么损失函数会说“对你有好处!不用担心”[ 1:44:42 ]。
这篇论文的实际贡献是添加(1 − pt)^γ到等式的开头 [ 1:45:06 ],这听起来没什么,但实际上人们多年来一直试图解决这个问题。当你看到这样一篇改变游戏规则的论文时,你不应该假设你将不得不编写数千行代码。很多时候是一行代码,或者单个常量的变化,或者在一个地方添加日志。
关于这篇论文的一些很棒的事情[ 1:46:08 ]:
- 方程式以简单的方式编写
- 他们“重构”
Focal Loss损失函数(超级详细的解读)_BigHao688的博客-CSDN博客_focal loss损失函数
实际上是可以解决正负样本不均衡的问题。
实施焦点损失 [ 1:49:27 ]:
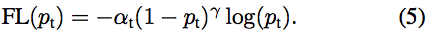
请记住,-log(pt) 是交叉熵损失,而焦点损失只是一个缩放版本。当我们定义二项式交叉熵损失时,您可能已经注意到默认情况下没有权重:
当你调用F.binary_cross_entropy_with_logits,你可以传递权重。由于我们只是想将交叉熵乘以某个东西,我们可以定义get_weight. 以下是焦点损失的全部内容 [ 1:50:23 ]:
如果你想知道为什么 alpha 和 gamma 是 0.25 和 2,那么这篇论文还有一个很棒的地方,因为他们尝试了很多不同的值,发现这些值都很好:
这次情况看起来好多了。所以我们现在的最后一步是基本上弄清楚如何只提取有趣的部分。
非最大抑制 [ 1:52:15 ]
我们要做的就是遍历每一对这些边界框,如果它们重叠超过一定数量,比如 0.5,使用 Jaccard 并且它们都预测相同的类,我们将假设它们是同样的东西,我们将选择p价值更高的东西。
这真是无聊的代码,Jeremy 不是自己写的,而是抄别人的。没有理由特别经历它。
这里还有一些问题需要解决 [ 1:53:43 ]。诀窍是使用称为特征金字塔的东西。这就是我们在第 14 课中要做的。
再谈谈 SSD paper [ 1:54:03 ]
当这篇论文出来的时候,Jeremy 很兴奋,因为这和 YOLO 是出现的第一种单通道高质量目标检测方法。在深度学习世界中,历史不断重复,随着时间的推移,涉及多个不同部分的多次传递,特别是在涉及一些非深度学习部分(如 R-CNN 所做的)的情况下,随着时间的推移,它们总是变成一个单一的端到端深度学习模型。所以我倾向于忽略它们,直到发生这种情况,因为人们已经想出如何将其展示为深度学习模型,一旦他们这样做了,他们通常会更快、更准确地结束。所以 SSD 和 YOLO 真的很重要。
模型为4段。论文非常简洁,这意味着您需要非常仔细地阅读它们。但是,部分原因是,您需要知道要仔细阅读哪些位。他们说“这里我们将证明这个模型的误差界限”的部分,你可以忽略它,因为你不关心证明误差界限。但是这里说的是模型是什么,你需要仔细阅读。
Jeremy 阅读第2.1 节模型[ 1:56:37 ]
如果你直接进入并阅读这样的论文,这 4 段可能毫无意义。但是现在我们已经完成了它,你读了这些,并希望在想“哦,这正是杰里米所说的,只有他们比杰里米更难过,而且话更少 [ 2:00:37 ]。如果你开始阅读一篇论文并“搞什么鬼”,那么诀窍就是开始阅读引文。
Jeremy 阅读匹配策略和训练目标(又名损失函数)[ 2:01:44 ]
一些论文提示 [ 2:02:34 ]
- “训练目标”是损失函数
- 像这样的双条和两个 2 表示均方误差
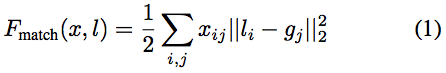
- log(c) 和 log(1-c),以及 x 和 (1-x) 它们都是二进制交叉熵的部分:
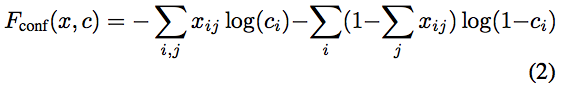
本周,浏览代码并浏览论文,看看发生了什么。请记住 Jeremy 所做的让您更轻松的事情是,他采用了该损失函数,将其复制到一个单元格中并将其拆分,以便每个位都在一个单独的单元格中。然后在每次卖出后,他打印或绘制该值。希望这是一个好的起点。















 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









