







Given two words (start and end), and a dictionary, find all shortest transformation sequence(s) from start to end, such that:
- Only one letter can be changed at a time
- Each intermediate word must exist in the dictionary
For example,
Given:
start = "hit"
end = "cog"
dict = ["hot","dot","dog","lot","log"]
Return
[
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]
]
Note:
- All words have the same length.
- All words contain only lowercase alphabetic characters.
用了一天的时间终于把它AC掉了,不容易啊,太难了,也证明了自己的能力还是不行。总结一下这道题的思路:
基本的思路依然延续Word Ladder的思想,用‘a’~‘z’替换字符串中的每一个值来判断字符串和字典中字符串之间的关系,如果一次替换后的字符串出现字典中,那么说明这个字符串和替换后对应字典中字符串之间的距离为1,这样就节省了创建邻接矩阵的时间,这个还是一个很不错的想法。
其次就是本题的特色了,不仅要求出ladder的长度,还要知道ladder的每一阶是什么,也就是记录下搜索路径。记录搜索路径的话就是DFS了。如何知道路径呢,那么就要创建搜索树。如何创建搜索树呢?按照传统的BFS的思路,访问一个节点就将这个节点设置为visited的,那么当所有的节点都visited之后,这颗树就成了,那么是否有问题呢?用图说明问题
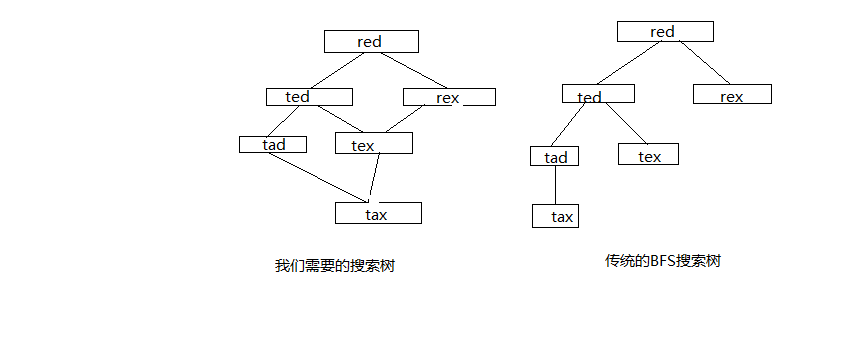
是否观察到区别?
传统的BFS搜索的节点只有一个确定的父节点,而我们需要的搜索树会出现多个父节点因此,传统的BFS的改良,我们使用两个队列来记录访问的过程,一个就是传统BFS算法所用的队列queue,然后这里还要使用一个额外的队列LevelElements,这个队列就是从上一层得到的下一层的元素,可以重复,如第二层是ted,rex,那么访问过这一层之后得到的LevelElements就是[tad,tex,tex],然后去重加入queue中。这就是改进的搜索树。
至于树节点之间的关系,我们使用一个map,记录访问到的每一个节点和节点的parent节点。
DFS过程中,由于已经有了每一个节点的parent节点,那么搜索树的形状就知道了,所以用DFS就可以得到所有的路径。至于路径的保存问题,我们使用一个LinkedList 类型tmp列表,搜索到一个节点,就将它加入tmp,离开它的时候从tmp中移除。这样当搜索到start的时候tmp就是一个完整的路径了,然后深度copy tmp,加入总路径记录的list中。
至此,整个算法思想介绍完毕了,算法是自己一边度娘一边自己写,花费的时间虽然很多,但是还是很高兴的,终于AC过了。
这道题DFS和BFS结合的还是很完美的。
public class Solution {
public List<List<String>> findLadders(String start, String end, Set<String> dict) {
List<List<String>> list = new LinkedList<List<String>>();
//特殊情况
if (start == null || end == null)
return list;
if (isOneWordDiff(start, end)){
List<String> l = new ArrayList<String>();
l.add(start);
l.add(end);
list.add(l);
return list;
}
dict.add(start);//即使字典已经包含start和end也无所谓
dict.add(end);
/*********主要涉及的数据结构***********/
Queue<String> queue = new LinkedList<String>();//访问队列,用来记录访问的顺序,里面可能存在了多层的元素
Queue<String> levelElements = new LinkedList<String>();//记录通过上层可以访问到的所有的元素,可能会有重复,这个队列只保存一层里的数据,不会保存多层元素
Map<String,Set<String>> parent = new HashMap<String,Set<String>>();//使用map记录访问节点和访问节点的父节点,由于有可能有多个parent所以使用Set来存储
Set<String> visited = new HashSet<String>();
/************************************************/
//List<String> parent = new ArrayList<String>();//存储end的parent
StringBuilder sb = null;//重复修改字符串并且是单线程使用StringBuilder
int level = 0;//某一层的元素数
//int len = 0;
queue.offer(start);
visited.add(start);
level++;
parent.put(start,new HashSet<String>());//start的parent为""
Set<String> parentSet = null;
//parentSet.add("");
//System.out.println(parent);
boolean flag = false;//找到了end所在的len层,那么当len层的所有元素都出队之后就可以结束了
while(!queue.isEmpty())
{
//len++;
int count = 0;
//int nextLevel = 0;
while(count < level){//控制出队的个数,len层出队
String tmp = queue.poll();
if(end.equals(tmp)){//找到了end,如果找到了end,说明end的parent已经存到了map里,因此可以退出循环,而不用管是否队空
flag = true;
break;
}else{
//将能够进行一次转换就到字典里的string加到队列,也就是离tmp最近的
sb = new StringBuilder(tmp);//重复修改字符串并且是单线程使用StringBuilder
for(int i = 0 ; i < tmp.length(); i++){
char c = sb.charAt(i);
//parentSet = parent.get(tmp);
for(char j = 'a' ; j <= 'z' ; j ++){
if(j == c){
continue;
}else{
sb.setCharAt(i,j);
if(dict.contains(sb.toString()) && !visited.contains(sb.toString())){
levelElements.offer(sb.toString());
if(parent.containsKey(sb.toString())){
parentSet = parent.get(sb.toString());
parentSet.add(tmp);
}else{
//queue.offer(sb.toString());
parentSet = new HashSet<String>();
parentSet.add(tmp);
parent.put(sb.toString(),parentSet);
}
}
}
}
sb.setCharAt(i,c);
}
}
count++;
}
if(flag){
break;
}
level = 0;
//System.out.println(levelElements);
while(!levelElements.isEmpty()){
String tmp = levelElements.poll();
if(!visited.contains(tmp)){
queue.offer(tmp);
level++;
visited.add(tmp);
}
}
//System.out.println(queue);
//break;
}
if(!parent.containsKey(end)){
return list;
}
//System.out.println(parent);
List<String> tmp = new LinkedList<String>();//用来构造路径
buildPath(list,tmp,parent,start,end);
return list;
}
private boolean isOneWordDiff(String a, String b) {
int diff = 0;
for (int i = 0; i < a.length(); i++) {
if (a.charAt(i) != b.charAt(i)) {
diff++;
if (diff >= 2)
break;
}
}
return diff == 1;
}
public void buildPath(List<List<String>> list,List<String> tmp,Map<String,Set<String>> parent,String start,String s){
if(s.equals(start)){
tmp.add(0,s);
List<String> l = new LinkedList<String>();
for(int i = 0; i < tmp.size(); i ++){//深度复制
l.add(tmp.get(i));
}
//l.add(0,start);
list.add(l);
tmp.remove(s);
}
Set<String> set = parent.get(s);//获得s的父亲
for(String s1: set){
tmp.add(0,s);
buildPath(list,tmp,parent,start,s1);
tmp.remove(s);
}
}
}
Runtime: 888 ms
这个运行时间挺不错的,提交了多次得到了这个时间 ,时间不一定,有时候能到700多ms。
,时间不一定,有时候能到700多ms。
自己的测试代码
import java.util.*;
public class Solution {
public static void main(String[] args){
Solution solution = new Solution();
String start = "qa";
String end = "sq";
String[] s = {"si","go","se","cm","so","ph","mt","db","mb","sb","kr","ln","tm","le","av","sm","ar","ci","ca","br","ti","ba","to","ra","fa","yo","ow","sn","ya","cr","po","fe","ho","ma","re","or","rn","au","ur","rh","sr","tc","lt","lo","as","fr","nb","yb","if","pb","ge","th","pm","rb","sh","co","ga","li","ha","hz","no","bi","di","hi","qa","pi","os","uh","wm","an","me","mo","na","la","st","er","sc","ne","mn","mi","am","ex","pt","io","be","fm","ta","tb","ni","mr","pa","he","lr","sq","ye"};
Set<String> dict = new HashSet<String>();
for(int i = 0 ; i < s.length; i ++){
dict.add(s[i]);
}
//System.out.println(solution.findLadders(start,end,dict));
solution.findLadders(start,end,dict);
//System.out.println(dict);
}
public List<List<String>> findLadders(String start, String end, Set<String> dict) {
List<List<String>> list = new LinkedList<List<String>>();
//特殊情况
if (start == null || end == null)
return list;
if (isOneWordDiff(start, end)){
List<String> l = new ArrayList<String>();
l.add(start);
l.add(end);
list.add(l);
return list;
}
dict.add(start);//即使字典已经包含start和end也无所谓
dict.add(end);
/*********主要涉及的数据结构***********/
Queue<String> queue = new LinkedList<String>();//访问队列,用来记录访问的顺序,里面可能存在了多层的元素
Queue<String> levelElements = new LinkedList<String>();//记录通过上层可以访问到的所有的元素,可能会有重复,这个队列只保存一层里的数据,不会保存多层元素
Map<String,Set<String>> parent = new HashMap<String,Set<String>>();//使用map记录访问节点和访问节点的父节点,由于有可能有多个parent所以使用Set来存储
Set<String> visited = new HashSet<String>();
/************************************************/
//List<String> parent = new ArrayList<String>();//存储end的parent
StringBuilder sb = null;//重复修改字符串并且是单线程使用StringBuilder
int level = 0;//某一层的元素数
//int len = 0;
queue.offer(start);
visited.add(start);
level++;
parent.put(start,new HashSet<String>());//start的parent为""
Set<String> parentSet = null;
//parentSet.add("");
//System.out.println(parent);
boolean flag = false;//找到了end所在的len层,那么当len层的所有元素都出队之后就可以结束了
while(!queue.isEmpty())
{
//len++;
int count = 0;
//int nextLevel = 0;
while(count < level){//控制出队的个数,len层出队
String tmp = queue.poll();
if(end.equals(tmp)){//找到了end,如果找到了end,说明end的parent已经存到了map里,因此可以退出循环,而不用管是否队空
flag = true;
break;
}else{
//将能够进行一次转换就到字典里的string加到队列,也就是离tmp最近的
sb = new StringBuilder(tmp);//重复修改字符串并且是单线程使用StringBuilder
for(int i = 0 ; i < tmp.length(); i++){
char c = sb.charAt(i);
//parentSet = parent.get(tmp);
for(char j = 'a' ; j <= 'z' ; j ++){
if(j == c){
continue;
}else{
sb.setCharAt(i,j);
if(dict.contains(sb.toString()) && !visited.contains(sb.toString())){
levelElements.offer(sb.toString());
if(parent.containsKey(sb.toString())){
parentSet = parent.get(sb.toString());
parentSet.add(tmp);
}else{
//queue.offer(sb.toString());
parentSet = new HashSet<String>();
parentSet.add(tmp);
parent.put(sb.toString(),parentSet);
}
}
}
}
sb.setCharAt(i,c);
}
}
count++;
}
if(flag){
break;
}
level = 0;
//System.out.println(levelElements);
while(!levelElements.isEmpty()){
String tmp = levelElements.poll();
if(!visited.contains(tmp)){
queue.offer(tmp);
level++;
visited.add(tmp);
}
}
//System.out.println(queue);
//break;
}
if(!parent.containsKey(end)){
return list;
}
//System.out.println(parent);
List<String> tmp = new LinkedList<String>();//用来构造路径
buildPath(list,tmp,parent,start,end);
return list;
}
private boolean isOneWordDiff(String a, String b) {
int diff = 0;
for (int i = 0; i < a.length(); i++) {
if (a.charAt(i) != b.charAt(i)) {
diff++;
if (diff >= 2)
break;
}
}
return diff == 1;
}
public void buildPath(List<List<String>> list,List<String> tmp,Map<String,Set<String>> parent,String start,String s){
if(s.equals(start)){
tmp.add(0,s);
List<String> l = new LinkedList<String>();
for(int i = 0; i < tmp.size(); i ++){//深度复制
l.add(tmp.get(i));
}
//l.add(0,start);
list.add(l);
tmp.remove(s);
}
Set<String> set = parent.get(s);//获得s的父亲
for(String s1: set){
tmp.add(0,s);
buildPath(list,tmp,parent,start,s1);
tmp.remove(s);
}
}
}
一共是51组















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









