






OpenPose 介绍
姿势识别模型(OpenPose)指的是识别图片中的人物,并且对人物的各个部位进行识别,例如头部、肩膀、肘部,并进行连线最终生成一个线条图。
OpenPose 处理流程分为以下 3 步
- 预处理,图片调整为 368 * 368,颜色归一化
- 输入 OpenPose 的神经网络,网络输出两个数组,第一个是 193838(分类数 * 高度 * 宽度)代表 19 个分类,第二个是 PAFs 的分类 (38 * 368 * 368),19 个分类的X、Y 向量坐标,共计 38 个通道,数组中保存的值是分类的概率。
- 将身体部位输出结果按照每个部位形成一个点,根据 PAFs 中的信息对链接进行计算,并将图像尺寸恢复为原有图像大小
数据准备(数据集以及数据加载)
对于 OpenPose 模型,在数据准备中,有一个特别的步骤,要通过掩码方式将训练数据集和验证数据集中,对于那些没有提供标注信息的人物,要把任务涂黑,否则会对模型学习有很大影响。在训练过程中,损失函数会忽略这些被掩码覆盖(涂黑)的数据。
# 导入软件包
import json
import os
import os.path as osp
import numpy as np
import cv2
from PIL import Image
from matplotlib import cm
import matplotlib.pyplot as plt
%matplotlib inline
import torch.utils.data as data
创建图像数据、标注数据
def make_datapath_list(rootpath):
"""
创建学习、验证的图像数据、标注数据、掩码数据的文件路径列表。
"""
#读取标注数据的JSON文件
json_path = osp.join(rootpath, 'COCO.json')
with open(json_path) as data_file:
data_this = json.load(data_file)
data_json = data_this['root']
num_samples = len(data_json)
train_indexes = []
val_indexes = []
for count in range(num_samples):
if data_json[count]['isValidation'] != 0.:
val_indexes.append(count)
else:
train_indexes.append(count)
#保存图像数据的文件路径
train_img_list = list()
val_img_list = list()
for idx in train_indexes:
img_path = os.path.join(rootpath, data_json[idx]['img_paths'])
train_img_list.append(img_path)
for idx in val_indexes:
img_path = os.path.join(rootpath, data_json[idx]['img_paths'])
val_img_list.append(img_path)
#保存掩码数据的文件路径
train_mask_list = []
val_mask_list = []
for idx in train_indexes:
img_idx = data_json[idx]['img_paths'][-16:-4]
anno_path = "./data/mask/train2014/mask_COCO_tarin2014_" + img_idx+'.jpg'
train_mask_list.append(anno_path)
for idx in val_indexes:
img_idx = data_json[idx]['img_paths'][-16:-4]
anno_path = "./data/mask/val2014/mask_COCO_val2014_" + img_idx+'.jpg'
val_mask_list.append(anno_path)
#保存标注数据
train_meta_list = list()
val_meta_list = list()
for idx in train_indexes:
train_meta_list.append(data_json[idx])
for idx in val_indexes:
val_meta_list.append(data_json[idx])
return train_img_list, train_mask_list, val_img_list, val_mask_list, train_meta_list, val_meta_list
#确认执行结果(实际执行时间大约为10秒)
train_img_list, train_mask_list, val_img_list, val_mask_list, train_meta_list, val_meta_list = make_datapath_list(
rootpath="./data/")
val_meta_list[24]
index = 24
# 画像
img = cv2.imread(val_img_list[index])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()
# 掩码
mask_miss = cv2.imread(val_mask_list[index])
mask_miss = cv2.cvtColor(mask_miss, cv2.COLOR_BGR2RGB)
plt.imshow(mask_miss)
plt.show()
# 合成
blend_img = cv2.addWeighted(img, 0.4, mask_miss, 0.6, 0)
plt.imshow(blend_img)
plt.show()
# 导入数据处理类和数据增强类
from utils.data_augumentation import Compose, get_anno, add_neck, aug_scale, aug_rotate, aug_croppad, aug_flip, remove_illegal_joint, Normalize_Tensor, no_Normalize_Tensor
class DataTransform():
"""
图像、蒙版和注释的预处理类。
它在学习和推理过程中表现不同。
数据增强是在学习过程中进行的。
"""
def __init__(self):
self.data_transform = {
'train': Compose([
get_anno(), # 将 JSON 中的注释存储到字典中
add_neck(), # 更改注释数据的顺序并添加更多颈部注释数据
aug_scale(), # 缩放
aug_rotate(), # 旋转
aug_croppad(), # 裁剪
aug_flip(), # 水平翻转
remove_illegal_joint(), # 删除图像中突出的注释
no_Normalize_Tensor()
]),
'val': Compose([
# 本书省略验证
])
}
def __call__(self, phase, meta_data, img, mask_miss):
"""
Parameters
----------
phase : 'train' or 'val'
指定预处理模式。
"""
meta_data, img, mask_miss = self.data_transform[phase](
meta_data, img, mask_miss)
return meta_data, img, mask_miss
# 动作确认
# 图像读取
index = 24
img = cv2.imread(val_img_list[index])
mask_miss = cv2.imread(val_mask_list[index])
meat_data = val_meta_list[index]
#图像预处理
transform = DataTransform()
meta_data, img, mask_miss = transform("train", meat_data, img, mask_miss)
# 画像表示
img = img.numpy().transpose((1, 2, 0))
plt.imshow(img)
plt.show()
# Mask显示
mask_miss = mask_miss.numpy().transpose((1, 2, 0))
plt.imshow(mask_miss)
plt.show()
# 在合成RGB后
img = Image.fromarray(np.uint8(img*255))
img = np.asarray(img.convert('RGB'))
mask_miss = Image.fromarray(np.uint8((mask_miss)))
mask_miss = np.asarray(mask_miss.convert('RGB'))
blend_img = cv2.addWeighted(img, 0.4, mask_miss, 0.6, 0)
plt.imshow(blend_img)
plt.show()
from utils.dataloader import get_ground_truth
# 图片加载
index = 24
img = cv2.imread(val_img_list[index])
mask_miss = cv2.imread(val_mask_list[index])
meat_data = val_meta_list[index]
# 图像预处理
meta_data, img, mask_miss = transform("train", meat_data, img, mask_miss)
img = img.numpy().transpose((1, 2, 0))
mask_miss = mask_miss.numpy().transpose((1, 2, 0))
# OpenPose注释数据生成
heat_mask, heatmaps, paf_mask, pafs = get_ground_truth(meta_data, mask_miss)
# 画像表示
plt.imshow(img)
plt.show()
# 检查左肘部的热图
# 原始图像
img = Image.fromarray(np.uint8(img*255))
img = np.asarray(img.convert('RGB'))
# 左肘
heat_map = heatmaps[:, :, 6] # 6是左肘
heat_map = Image.fromarray(np.uint8(cm.jet(heat_map)*255))
heat_map = np.asarray(heat_map.convert('RGB'))
heat_map = cv2.resize(
heat_map, (img.shape[1], img.shape[0]), interpolation=cv2.INTER_CUBIC)
# 注意:热图图像尺寸为1/8,因此请放大。
# 合成与显示
blend_img = cv2.addWeighted(img, 0.5, heat_map, 0.5, 0)
plt.imshow(blend_img)
plt.show()
```
```
# 左手腕
heat_map = heatmaps[:, :, 7] # 7是左手腕
heat_map = Image.fromarray(np.uint8(cm.jet(heat_map)*255))
heat_map = np.asarray(heat_map.convert('RGB'))
heat_map = cv2.resize(
heat_map, (img.shape[1], img.shape[0]), interpolation=cv2.INTER_CUBIC)
# 合成与显示
blend_img = cv2.addWeighted(img, 0.5, heat_map, 0.5, 0)
plt.imshow(blend_img)
plt.show()
```
```
# 确认 PAF 到左肘和左手腕
paf = pafs[:, :, 24] # 24连接左肘和左手腕
paf = Image.fromarray(np.uint8((paf)*255))
paf = np.asarray(paf.convert('RGB'))
paf = cv2.resize(
paf, (img.shape[1], img.shape[0]), interpolation=cv2.INTER_CUBIC)
# 合成与显示
blend_img = cv2.addWeighted(img, 0.3, paf, 0.7, 0)
plt.imshow(blend_img)
plt.show()
```
```
# 只显示PAF
paf = pafs[:, :, 24] #24连接左肘和左手腕
paf = Image.fromarray(np.uint8((paf)*255))
paf = np.asarray(paf.convert('RGB'))
paf = cv2.resize(
paf, (img.shape[1], img.shape[0]), interpolation=cv2.INTER_CUBIC)
plt.imshow(paf)
```
创建 dataset
```
from utils.dataloader import get_ground_truth
class COCOkeypointsDataset(data.Dataset):
"""
创建 MSCOCO 的 Cocokeypoints 数据集的类。继承PyTorch的Dataset类。
Attributes
----------
img_list : 列表
用于保存图像路径列表
anno_list : 列表
用于保存标注数据路径列表
phase : 'train' or 'test'
指定是学习还是训练。
transform : object
预处理类的实例
"""
def __init__(self, img_list, mask_list, meta_list, phase, transform):
self.img_list = img_list
self.mask_list = mask_list
self.meta_list = meta_list
self.phase = phase
self.transform = transform
def __len__(self):
'''返回图像的张数'''
return len(self.img_list)
def __getitem__(self, index):
img, heatmaps, heat_mask, pafs, paf_mask = self.pull_item(index)
return img, heatmaps, heat_mask, pafs, paf_mask
def pull_item(self, index):
'''获取图像的张量形式的数据、标注、掩码'''
#1.读取图像数据
image_file_path = self.img_list[index]
img = cv2.imread(image_file_path) #[高度][宽度][颜色BGR]
#2.读取掩码数据和标注数据
mask_miss = cv2.imread(self.mask_list[index])
meat_data = self.meta_list[index]
#3.图像的预处理
meta_data, img, mask_miss = self.transform(
self.phase, meat_data, img, mask_miss)
#4.获取正确答案标注数据
mask_miss_numpy = mask_miss.numpy().transpose((1, 2, 0))
heat_mask, heatmaps, paf_mask, pafs = get_ground_truth(
meta_data, mask_miss_numpy)
#5.掩码数据是RGB格式的(1,1,1)或(0,0,0),因此对其进行降维处理
#掩码数据在被遮盖的部分的值为0,其他部分的值为1
heat_mask = heat_mask[:, :, :, 0]
paf_mask = paf_mask[:, :, :, 0]
#6.由于通道在末尾,因此对顺序进行调整
# 例:paf_mask:torch.Size([46, 46, 38])
# → torch.Size([38, 46, 46])
paf_mask = paf_mask.permute(2, 0, 1)
heat_mask = heat_mask.permute(2, 0, 1)
pafs = pafs.permute(2, 0, 1)
heatmaps = heatmaps.permute(2, 0, 1)
return img, heatmaps, heat_mask, pafs, paf_mask
```
```
# 确认执行结果
train_dataset = COCOkeypointsDataset(
val_img_list, val_mask_list, val_meta_list, phase="train", transform=DataTransform())
val_dataset = COCOkeypointsDataset(
val_img_list, val_mask_list, val_meta_list, phase="val", transform=DataTransform())
# #读取数据的示例
item = train_dataset.__getitem__(0)
print(item[0].shape) # img
print(item[1].shape) # heatmaps,
print(item[2].shape) # heat_mask
print(item[3].shape) # pafs
print(item[4].shape) # paf_mask
```
数据加载
```
#创建数据加载器
batch_size = 8
train_dataloader = data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = data.DataLoader(
val_dataset, batch_size=batch_size, shuffle=False)
#集中保存到字典型变量中
dataloaders_dict = {"train": train_dataloader, "val": val_dataloader}
#确认执行结果
batch_iterator = iter(dataloaders_dict["train"]) #转换为迭代器
item = next(batch_iterator) #读取第一个元素
print(item[0].shape) # img
print(item[1].shape) # heatmaps,
print(item[2].shape) # heat_mask
print(item[3].shape) # pafs
print(item[4].shape) # paf_mask
```
### OpenPose 网络
OpenPose 共由 7 个模块组成,首先提取图像的Feature 模块,用于数据 heatmaps 和 PAFs 的 stage 模块,stage 模块包括 stage1 到 stage6。Feature 使用的是 VGG-19,输出是原图像的 1/8,最终输出是 128*46*46。Feature 输出的的数据会输入到 Stage1 中,Stage1 中包含两个模块 block1_1和 block1_2,block1_1 输出PAFs 的子网络,block1_2是输出 heatmap的子网络,分别为 38*46*36 和 19*46*46。可以直接试用 stage1 的输出,但是 stage1 的效果非常有限,如果需要更高精度,可以将stage1 的输出与feature 的输出进行合并,并输入到下一个 stage 中。
```
# 导入软件包
import torch
import torch.nn as nn
from torch.nn import init
import torchvision
class OpenPoseNet(nn.Module):
def __init__(self):
super(OpenPoseNet, self).__init__()
#Feature模块
self.model0 = OpenPose_Feature()
#Stage模块
#PAFs部分
self.model1_1 = make_OpenPose_block('block1_1')
self.model2_1 = make_OpenPose_block('block2_1')
self.model3_1 = make_OpenPose_block('block3_1')
self.model4_1 = make_OpenPose_block('block4_1')
self.model5_1 = make_OpenPose_block('block5_1')
self.model6_1 = make_OpenPose_block('block6_1')
#confidence heatmap部分
self.model1_2 = make_OpenPose_block('block1_2')
self.model2_2 = make_OpenPose_block('block2_2')
self.model3_2 = make_OpenPose_block('block3_2')
self.model4_2 = make_OpenPose_block('block4_2')
self.model5_2 = make_OpenPose_block('block5_2')
self.model6_2 = make_OpenPose_block('block6_2')
def forward(self, x):
"""定义正向传播函数"""
#Feature模块
out1 = self.model0(x)
# Stage1
out1_1 = self.model1_1(out1) #PAFs部分
out1_2 = self.model1_2(out1) # confidence heatmap部分
# CStage2
out2 = torch.cat([out1_1, out1_2, out1], 1) #用一维的通道进行合并
out2_1 = self.model2_1(out2)
out2_2 = self.model2_2(out2)
# Stage3
out3 = torch.cat([out2_1, out2_2, out1], 1)
out3_1 = self.model3_1(out3)
out3_2 = self.model3_2(out3)
# Stage4
out4 = torch.cat([out3_1, out3_2, out1], 1)
out4_1 = self.model4_1(out4)
out4_2 = self.model4_2(out4)
# Stage5
out5 = torch.cat([out4_1, out4_2, out1], 1)
out5_1 = self.model5_1(out5)
out5_2 = self.model5_2(out5)
# Stage6
out6 = torch.cat([out5_1, out5_2, out1], 1)
out6_1 = self.model6_1(out6)
out6_2 = self.model6_2(out6)
#保存每个Stage的结果,以用于损失计算
saved_for_loss = []
saved_for_loss.append(out1_1) #PAFs部分
saved_for_loss.append(out1_2) # confidence heatmap部分
saved_for_loss.append(out2_1)
saved_for_loss.append(out2_2)
saved_for_loss.append(out3_1)
saved_for_loss.append(out3_2)
saved_for_loss.append(out4_1)
saved_for_loss.append(out4_2)
saved_for_loss.append(out5_1)
saved_for_loss.append(out5_2)
saved_for_loss.append(out6_1)
saved_for_loss.append(out6_2)
#最后输出PAFs的out6_1和confidence heatmap的out6_2,以及
#保存着用于损失计算的每个Stage的PAFs和heatmap的saved_for_loss变量
# out6_1:torch.Size([minibatch, 38, 46, 46])
# out6_2:torch.Size([minibatch, 19, 46, 46])
# saved_for_loss:[out1_1, out_1_2, ・・・, out6_2]
return (out6_1, out6_2), saved_for_loss
```
Feature 模块
```
class OpenPose_Feature(nn.Module):
def __init__(self):
super(OpenPose_Feature, self).__init__()
#使用VGG−19开头的10个卷积层
#第一次执行时,由于需要载入模型的权重参数,因此所需执行时间较长
vgg19 = torchvision.models.vgg19(pretrained=True)
model = {}
model['block0'] = vgg19.features[0:23] #到VGG-19开头的10个卷积层为止
#再准备两个新的卷积层
model['block0'].add_module("23", torch.nn.Conv2d(
512, 256, kernel_size=3, stride=1, padding=1))
model['block0'].add_module("24", torch.nn.ReLU(inplace=True))
model['block0'].add_module("25", torch.nn.Conv2d(
256, 128, kernel_size=3, stride=1, padding=1))
model['block0'].add_module("26", torch.nn.ReLU(inplace=True))
self.model = model['block0']
def forward(self, x):
outputs = self.model(x)
return outputs
```
Stage 模块
```
def make_OpenPose_block(block_name):
"""
根据配置参数变量创建OpenPose的Stage模块的block
这里使用的不是nn.Module,而是nn.Sequential
"""
#1. 创建配置参数的字典型变量blocks,并用其创建网络
#从一开始就设置好全部模式的字典,创建时只使用block_name参数指定的值
blocks = {}
# Stage 1
blocks['block1_1'] = [{'conv5_1_CPM_L1': [128, 128, 3, 1, 1]},
{'conv5_2_CPM_L1': [128, 128, 3, 1, 1]},
{'conv5_3_CPM_L1': [128, 128, 3, 1, 1]},
{'conv5_4_CPM_L1': [128, 512, 1, 1, 0]},
{'conv5_5_CPM_L1': [512, 38, 1, 1, 0]}]
blocks['block1_2'] = [{'conv5_1_CPM_L2': [128, 128, 3, 1, 1]},
{'conv5_2_CPM_L2': [128, 128, 3, 1, 1]},
{'conv5_3_CPM_L2': [128, 128, 3, 1, 1]},
{'conv5_4_CPM_L2': [128, 512, 1, 1, 0]},
{'conv5_5_CPM_L2': [512, 19, 1, 1, 0]}]
# Stages 2 - 6
for i in range(2, 7):
blocks['block%d_1' % i] = [
{'Mconv1_stage%d_L1' % i: [185, 128, 7, 1, 3]},
{'Mconv2_stage%d_L1' % i: [128, 128, 7, 1, 3]},
{'Mconv3_stage%d_L1' % i: [128, 128, 7, 1, 3]},
{'Mconv4_stage%d_L1' % i: [128, 128, 7, 1, 3]},
{'Mconv5_stage%d_L1' % i: [128, 128, 7, 1, 3]},
{'Mconv6_stage%d_L1' % i: [128, 128, 1, 1, 0]},
{'Mconv7_stage%d_L1' % i: [128, 38, 1, 1, 0]}
]
blocks['block%d_2' % i] = [
{'Mconv1_stage%d_L2' % i: [185, 128, 7, 1, 3]},
{'Mconv2_stage%d_L2' % i: [128, 128, 7, 1, 3]},
{'Mconv3_stage%d_L2' % i: [128, 128, 7, 1, 3]},
{'Mconv4_stage%d_L2' % i: [128, 128, 7, 1, 3]},
{'Mconv5_stage%d_L2' % i: [128, 128, 7, 1, 3]},
{'Mconv6_stage%d_L2' % i: [128, 128, 1, 1, 0]},
{'Mconv7_stage%d_L2' % i: [128, 19, 1, 1, 0]}
]
#取出block_name参数的配置参数字典
cfg_dict = blocks[block_name]
#2.将配置参数的内容保存到列表变量layers中
layers = []
#创建从0层到最后一层的网络
for i in range(len(cfg_dict)):
for k, v in cfg_dict[i].items():
if 'pool' in k:
layers += [nn.MaxPool2d(kernel_size=v[0], stride=v[1],
padding=v[2])]
else:
conv2d = nn.Conv2d(in_channels=v[0], out_channels=v[1],
kernel_size=v[2], stride=v[3],
padding=v[4])
layers += [conv2d, nn.ReLU(inplace=True)]
#3.将layers传入Sequential
#但是,由于最后的ReLU是不需要的,因此在那之前截止
net = nn.Sequential(*layers[:-1])
#4.设置初始化函数,对卷积层进行初始化
def _initialize_weights_norm(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.normal_(m.weight, std=0.01)
if m.bias is not None:
init.constant_(m.bias, 0.0)
net.apply(_initialize_weights_norm)
return net
#定义模型
net = OpenPoseNet()
net.train()
#生成伪数据
batch_size = 2
dummy_img = torch.rand(batch_size, 3, 368, 368)
#计算
outputs = net(dummy_img)
print(outputs)
```
### 可视化网络
安装 tensorboardX 实现网络可视化,通过将网络模型转为graph 文件,启动tensorboardX,并通过浏览器查看。
```
#安装
pip install tensorflow
pip install tensorboardx
```
```
# 导入软件包
import torch
from utils.openpose_net import OpenPoseNet
#准备网络模型
net = OpenPoseNet()
net.train()
from tensorboardX import SummaryWriter
#2.准备用于保存到tbX文件夹中的writer
#如果tbX文件夹不存在,就自动创建
writer = SummaryWriter("./tbX/")
#3.创建用于传递给网络的伪数据
batch_size = 2
dummy_img = torch.rand(batch_size, 3, 368, 368)
##4.针对OpenPose的实例net,将伪数据
#dummy_img传入时的graph保存到writer中
writer.add_graph(net, (dummy_img, ))
writer.close()
```
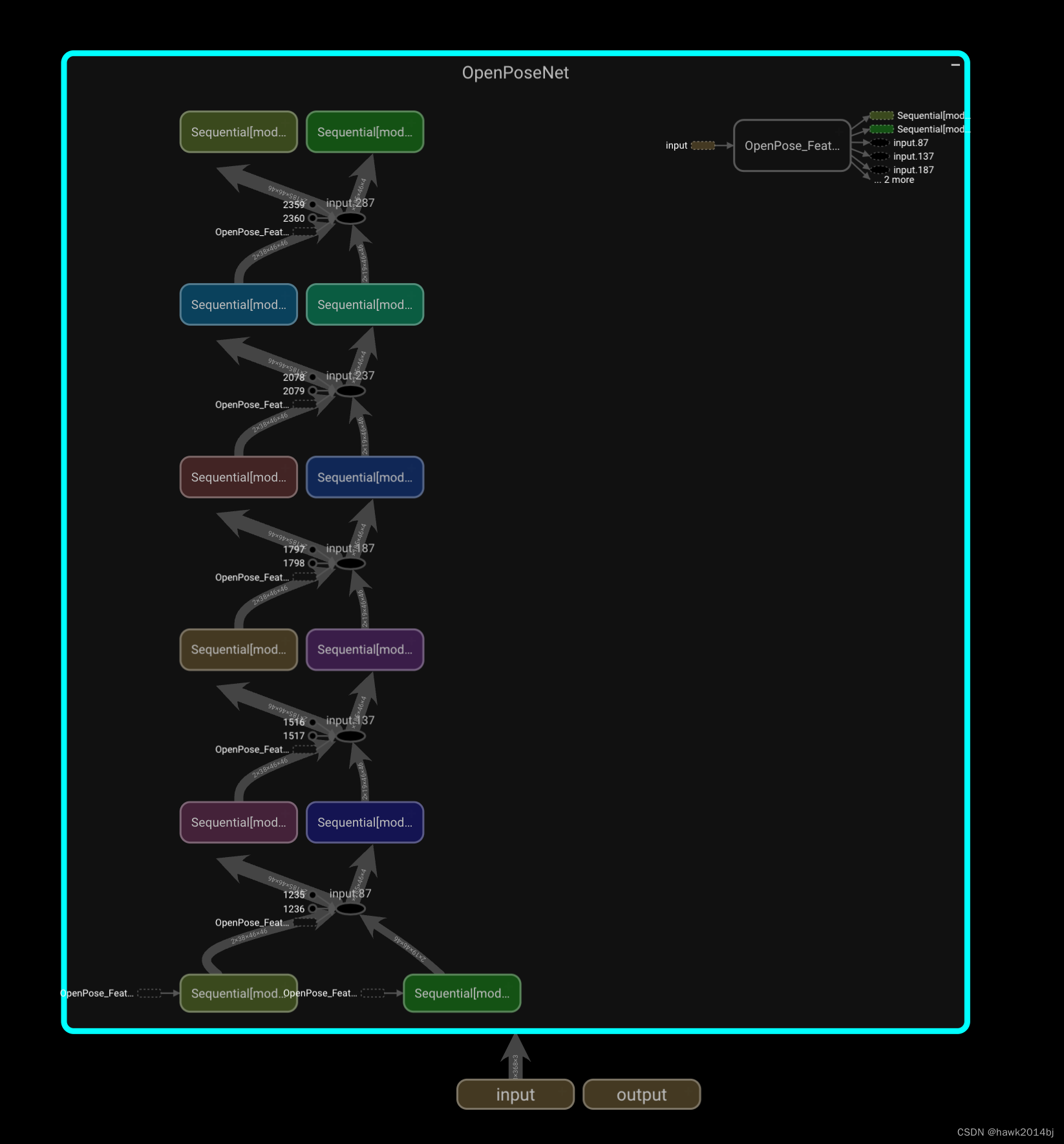
启动 tensorboard --logdir="./tbX/" 通过浏览器访问http://localhost:6006,如下图
### 训练、验证模型
定义损失函数,OpenPose 属于回归问题,所以这里使用是最为常用的均方差函数。
```
# 导入软件包
import random
import math
import time
import pandas as pd
import numpy as np
import torch
import torch.utils.data as data
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 初期設定
# Setup seeds
torch.manual_seed(1234)
np.random.seed(1234)
random.seed(1234)
from utils.dataloader import make_datapath_list, DataTransform, COCOkeypointsDataset
#创建MS COCO的文件路径列表
train_img_list, train_mask_list, val_img_list, val_mask_list, train_meta_list, val_meta_list = make_datapath_list(
rootpath="./data/")
#生成Dataset
#需要注意的是,在本书中由于考虑到数据量的问题,在这里train是用val_list生成的
train_dataset = COCOkeypointsDataset(
val_img_list, val_mask_list, val_meta_list, phase="train", transform=DataTransform())
#这次进行的是简单的学习,不需要创建验证数据
# val_dataset = CocokeypointsDataset(val_img_list, val_mask_list, val_meta_list, phase="val", transform=DataTransform())
#创建DataLoader
batch_size = 32
train_dataloader = data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True)
# val_dataloader = data.DataLoader(
# val_dataset, batch_size=batch_size, shuffle=False)
#集中保存到字典型变量中
# dataloaders_dict = {"train": train_dataloader, "val": val_dataloader}
dataloaders_dict = {"train": train_dataloader, "val": None}
from utils.openpose_net import OpenPoseNet
net = OpenPoseNet()
#设置损失函数
class OpenPoseLoss(nn.Module):
"""这是OpenPose的损失函数类"""
def __init__(self):
super(OpenPoseLoss, self).__init__()
def forward(self, saved_for_loss, heatmap_target, heat_mask, paf_target, paf_mask):
"""
损失函数的计算
Parameters
----------
saved_for_loss : OpenPoseNet 输出(列表)
heatmap_target : [num_batch, 19, 46, 46]
正确答案部分的标注信息
heatmap_mask : [num_batch, 19, 46, 46]
heatmap图像的mask mask
paf_target : [num_batch, 38, 46, 46]
正确答案的PAFs的标注信息
paf_mask : [num_batch, 38, 46, 46]
PAFs图像的mask
Returns
-------
loss : 张量
损失值
"""
total_loss = 0
#以Stage为单位进行计算
for j in range(6):
# 对于PAFs和heatmaps,被掩码的部分将被忽略(paf_mask=0等)
# PAFs
pred1 = saved_for_loss[2 * j] * paf_mask
gt1 = paf_target.float() * paf_mask
# heatmaps
pred2 = saved_for_loss[2 * j + 1] * heat_mask
gt2 = heatmap_target.float()*heat_mask
total_loss += F.mse_loss(pred1, gt1, reduction='mean') + \
F.mse_loss(pred2, gt2, reduction='mean')
return total_loss
criterion = OpenPoseLoss()
optimizer = optim.SGD(net.parameters(), lr=1e-2,
momentum=0.9,
weight_decay=0.0001)
#创建用于训练模型的函数
def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs):
#确认是否能够使用GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("使用的设备:", device)
#将网络载入GPU中
net.to(device)
#如果网络结构比较固定,则开启硬件加速
torch.backends.cudnn.benchmark = True
#图像的张数
num_train_imgs = len(dataloaders_dict["train"].dataset)
batch_size = dataloaders_dict["train"].batch_size
#设置迭代计数器
iteration = 1
#epoch循环
for epoch in range(num_epochs):
#保存开始时间
t_epoch_start = time.time()
t_iter_start = time.time()
epoch_train_loss = 0.0 #epoch的损失和
epoch_val_loss = 0.0 #epoch的损失和
print('-------------')
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('-------------')
#每轮epoch的训练和验证循环
for phase in ['train', 'val']:
if phase == 'train':
net.train() #将模型设置为训练模式
optimizer.zero_grad()
print('(train)')
#这次跳过验证处理
else:
continue
# net.eval() #将模型设置为验证模式
# print('-------------')
# print('(val)')
#从数据加载器中将小批量逐个取出进行循环处理
for imges, heatmap_target, heat_mask, paf_target, paf_mask in dataloaders_dict[phase]:
#如果小批量的尺寸为1,会导致批次正规化处理失败,因此需要避免
if imges.size()[0] == 1:
continue
#如果GPU可以使用,则将数据输送到GPU中
imges = imges.to(device)
heatmap_target = heatmap_target.to(device)
heat_mask = heat_mask.to(device)
paf_target = paf_target.to(device)
paf_mask = paf_mask.to(device)
#初始化optimizer
optimizer.zero_grad()
#正向传播计算
with torch.set_grad_enabled(phase == 'train'):
#由于(out6_1, out6_2)是不使用的,因此用_ 代替
_, saved_for_loss = net(imges)
loss = criterion(saved_for_loss, heatmap_target,
heat_mask, paf_target, paf_mask)
#训练时进行反向传播
if phase == 'train':
loss.backward()
optimizer.step()
if (iteration % 10 == 0): #每10次迭代显示一次loss
t_iter_finish = time.time()
duration = t_iter_finish - t_iter_start
print('迭代 {} || Loss: {:.4f} || 10iter: {:.4f} sec.'.format(
iteration, loss.item()/batch_size, duration))
t_iter_start = time.time()
epoch_train_loss += loss.item()
iteration += 1
#验证时
# else:
#epoch_val_loss += loss.item()
#epoch的每个phase的loss和准确率
t_epoch_finish = time.time()
print('-------------')
print('epoch {} || Epoch_TRAIN_Loss:{:.4f} ||Epoch_VAL_Loss:{:.4f}'.format(
epoch+1, epoch_train_loss/num_train_imgs, 0))
print('timer: {:.4f} sec.'.format(t_epoch_finish - t_epoch_start))
t_epoch_start = time.time()
#保存最终的网络
torch.save(net.state_dict(), 'weights/openpose_net_' +
str(epoch+1) + '.pth')
#执行学习和验证处理
num_epochs = 2
train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs)
```















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









