






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
线性回归概念
回归的目的是通过已知变量预测未知变量,而线性回归通过两个或多个变量之间的线性关系来进行预测。
线性回归代码实现
#数据预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#定义特征和目标变量
dataset = pd.read_csv('studentscores.csv')
X = dataset.iloc[ : , :1].values
Y = dataset.iloc[ : , 1].values
#拆分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,
test_size=1/4,
random_state=0)
dataset.head()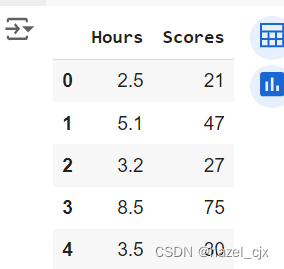
#简单线性回归模型
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor = regressor.fit(X_train, Y_train)#预测结果
Y_pred = regressor.predict(X_test)#训练集可视化
plt.scatter(X_train, Y_train, color='r')
plt.plot(X_train, regressor.predict(X_train), color='b')
plt.show()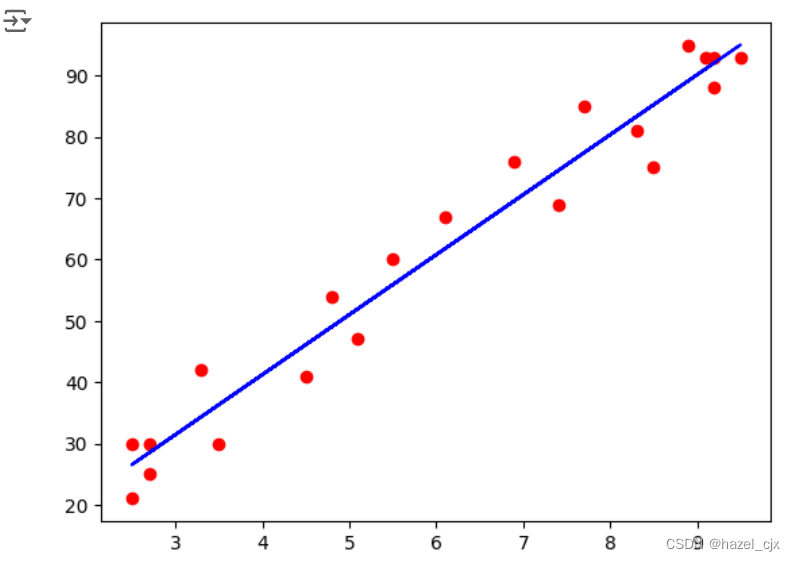
#训练集预测结果可视化
plt.scatter(X_test, Y_test, color='r')
plt.plot(X_test, regressor.predict(X_test), color='b')
plt.show()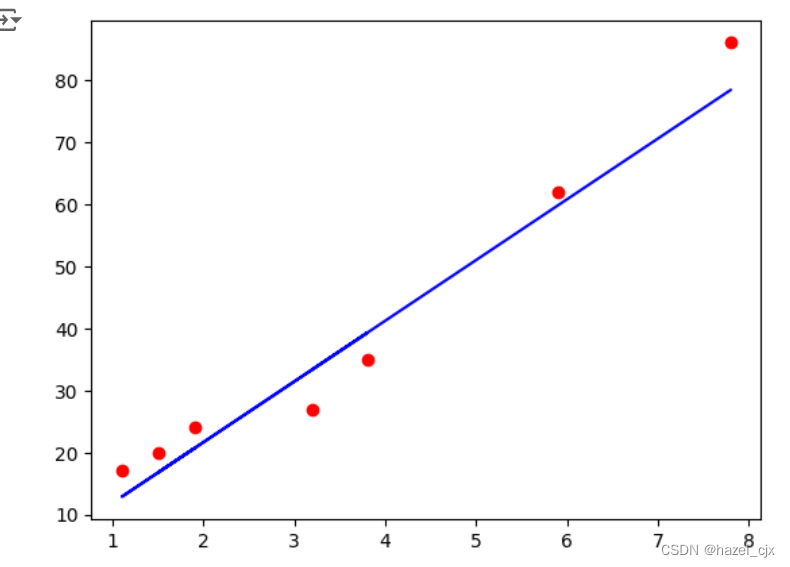
任务:使用LinearRegression,通过鸢尾花花瓣长度预测花瓣宽度
1. 数据预处理
#获取数据方法一(同教案)
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names = ['花萼-length', '花萼-width', '花瓣-length', '花瓣-width', 'class']
dataset = pd.read_csv(url, names=names)
dataset#获取数据方法二(seaborn built-in datasets)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#定义特征X和目标变量y
iris = sns.load_dataset('iris')
X = iris.iloc[ : , 2:3].values #花瓣长度
y = iris.iloc[ : , -2:-1].values #花瓣宽度 #y=iris.iloc[:,3]
#拆分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=42)
#iris.head()
iris 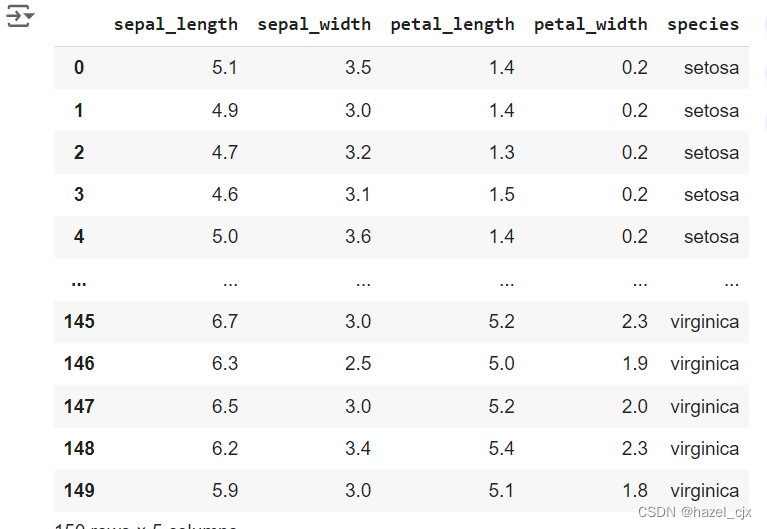
2. 简单线性回归模型
from sklearn.linear_model import LinearRegression
regressor = LinearRegression() #创建线性回归模型
regressor = regressor.fit(X_train, y_train) #使用训练集训练模型3. 预测结果
y_pred = regressor.predict(X_test)4. 可视化 (seaborn)
import seaborn as sns
import matplotlib.pyplot as plt
# 创建一个包含两个子图的图形。1, 2 表示1行2列,figsize 设置图形的大小
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 可视化训练集结果
#plt.figure(figsize=(10, 6))
sns.scatterplot(x=X_train.flatten(), y=y_train.flatten(), color='red', label='Training data', ax=ax1)
sns.lineplot(x=X_train.flatten(), y=regressor.predict(X_train).flatten(), color='blue', label='Regression line', ax=ax1)
ax1.set_title('Training set results')
ax1.set_xlabel('Petal Length')
ax1.set_ylabel('Petal Width')
ax1.legend()
# 可视化测试集结果
#plt.figure(figsize=(10, 6))
sns.scatterplot(x=X_test.flatten(), y=y_test.flatten(), color='red', label='Test data', ax=ax2)
sns.lineplot(x=X_test.flatten(), y=regressor.predict(X_test).flatten(), color='blue', label='Regression line', ax=ax2)
ax2.set_title('Test set results')
ax2.set_xlabel('Petal Length')
ax2.set_ylabel('Petal Width')
ax2.legend()
#调整子图间距并显示图像
plt.tight_layout()
plt.show()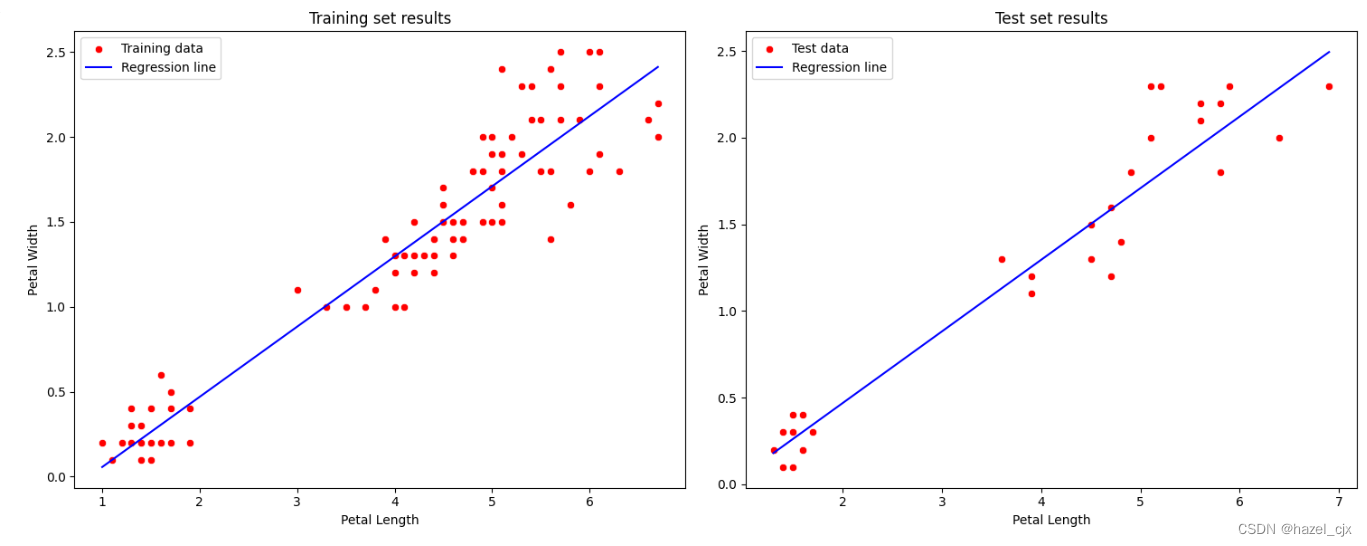
总结
在本周的任务中,学习了简单线性回归模型,并应用该模型对鸢尾花数据集进行了预测实践。具体任务包括以下几个步骤:
学习线性回归模型的基本概念:
了解了什么是回归、线性以及线性回归。回归的目的是通过已知变量预测未知变量,而线性回归通过两个或多个变量之间的线性关系来进行预测。
1. 数据预处理:
- 使用 pandas 读取数据集并进行初步处理。
- 使用 train_test_split 将数据集划分为训练集和测试集,以便后续模型的训练和验证
2. 模型训练:
- 使用 sklearn.linear_model 中的 LinearRegression 模型对训练集数据进行拟合
- 理解了模型的拟合过程以及如何通过训练集数据来优化模型参数
3. 结果预测
- 使用训练好的模型对测试集数据进行预测,并输出预测结果
- 通过预测结果评估模型的性能和准确性
4. 结果可视化
- 使用 matplotlib 对训练集和测试集的预测结果进行可视化,以便更直观地理解模型的表现
- 通过散点图和回归线展示数据点和预测结果的关系
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









