







利用pymupdf编辑修改pdf
本文背景
为了修改pdf的文本, 在pymupdf官方手册查了一通,没看到明显的说明,然后到github的讨论区看了发现了修改pdf的方案,在此记录一下
参考链接: https://github.com/pymupdf/PyMuPDF/discussions/1019
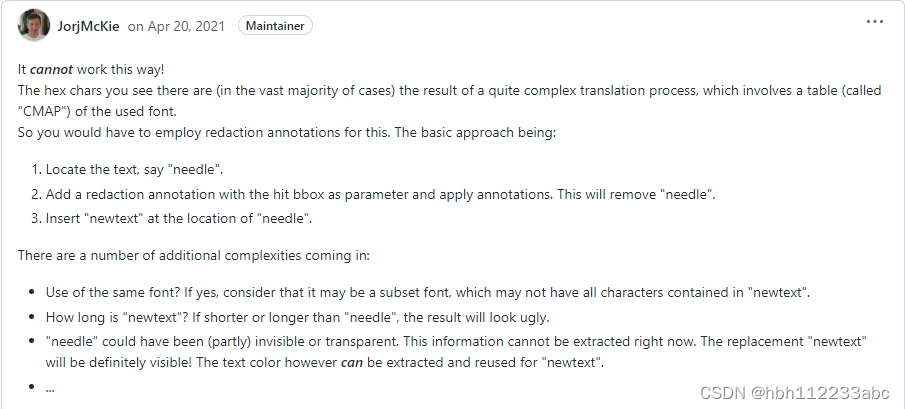
主要方法:
- 找到需要替换的文本块,然后添加修订注释(redaction annotation)
- 添加注释后,步骤1的文本块会被删除
- 在原位置添加新的文本块
注意事项:
- 字体问题: 要考虑被替换的文本块和新的文本块字体是否一致,否则可能看起来跟上下文显得突兀
- 文本长度问题: 最好文本长度差不多,不然可能跟周围的文本块有重叠或者留白太多
- 如果原文本是隐藏文本或者透明的, 文件信息是提取不到它的这个属性,新插入的文本将是可见的
修改PDF实践
1. 删除某些文本块
根据前文说明,我们发现使用修订注释可以删除文本块的,因此我们可以利用该方法进行一些文本块的删除操作,具体示例如下:
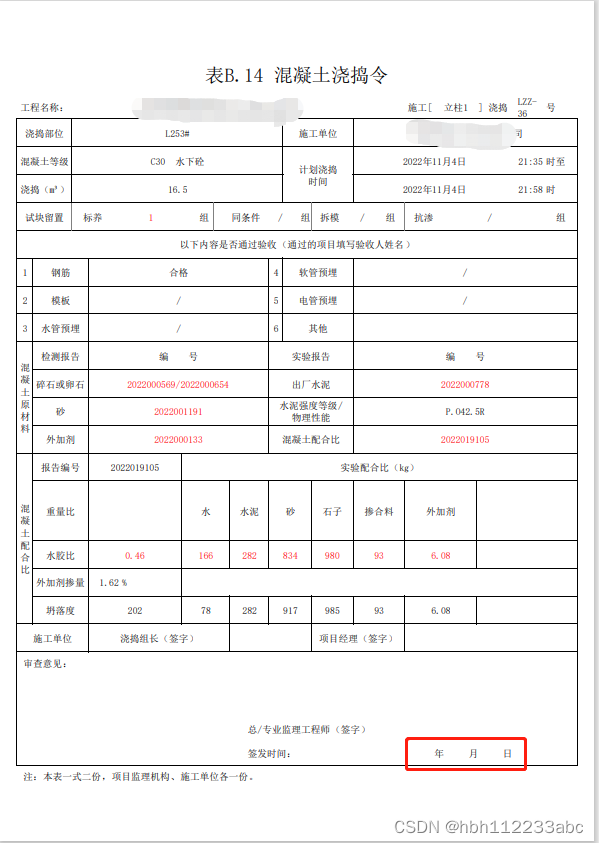
- 原文件如下,其中**" 年 月 日"**是我要删除的文本块
- 相关代码
import fitz
doc = fitz.open("PDF文件路径")
page = doc.load_page(0)
# 遍历文本块,找到对应的文本块
def find_textbox(page:fitz.Page,keyword:str)->dict:
info = page.get_text('dict')
for block in info['blocks']:
for line in block['lines']:
for span in line['spans']:
text = span.get('text','').replace(' ','')
if text == keyword:
return span
target = find_textbox(page,'年月日')
page.add_redact_annot(target['bbox'])
page.apply_redactions()
doc.save("保存文件路径")
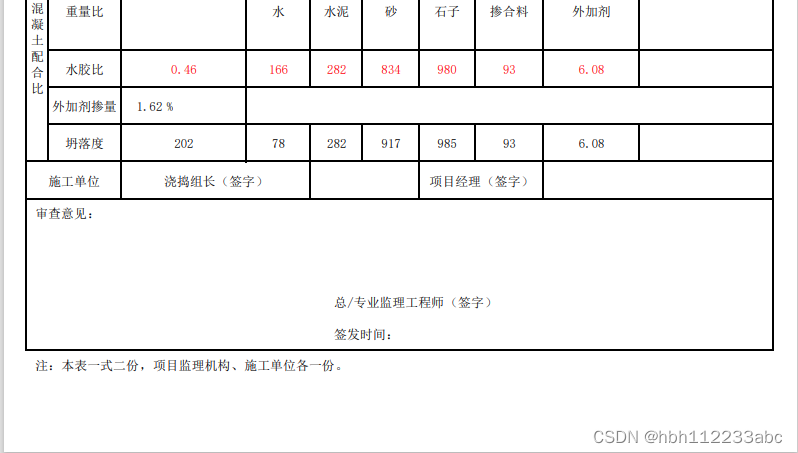
- 删除效果如下:
2. 修改文本块
修改文本块,就是在添加修订注释后,增加文本块即可
代码如下:
import fitz
doc = fitz.open("PDF文件路径")
page = doc.load_page(0)
# 遍历文本块,找到对应的文本块
def find_textbox(page:fitz.Page,keyword:str)->dict:
info = page.get_text('dict')
for block in info['blocks']:
for line in block['lines']:
for span in line['spans']:
text = span.get('text','').replace(' ','')
if text == keyword:
return span
target = find_textbox(page,'年月日')
page.add_redact_annot(target['bbox'],'今夕复何夕',fontname='china-s',fontsize=target['size'])
page.apply_redactions()
doc.save("保存文件路径")

3 改进一下
有粉丝留言数字修改错误,今天看了一下,原来写的逻辑是针对文本块基本完全匹配(除了空格),所以如果不修改的话,肯定容易报错了,现在改进了一版,以供参考
import math
from typing import Iterator
import fitz
from pathlib import Path
pdf = Path(__file__).parent / 'file' / 'test_data_config.pdf'
doc = fitz.open(pdf)
page = doc.load_page(0)
def find_textbox(page:fitz.Page,keyword:str)->Iterator[dict]:
"""找到页面的文本块,并返回文本块
Args:
page (fitz.Page): 页面对象
keyword (str): 查找的关键字
Yields:
Iterator[dict]: 文本块生成器
"""
info = page.get_text('dict')
for block in info['blocks']:
for line in block['lines']:
for span in line['spans']:
text = span.get('text','')
if keyword in text:
yield span
def find_replace(page: fitz.Page,search:str,replace:str,count:int=1):
"""查找并替换文本
Args:
page (fitz.Page): 页面对象
search (str): 查找关键字
replace (str): 替换文本
count (int, optional): 替换次数. Defaults to 1.
"""
spans = find_textbox(page,search)
modify = False
for span in spans:
text = span.get('text','')
text = text.replace(search,replace)
scale = math.floor(1/span['ascender']*10)/10
fontsize = round(span['size']*scale,2)
rect = fitz.Rect(span['bbox'])
rect_center = fitz.Point((rect.x0 + rect.x1) / 2, (rect.y0 + rect.y1) / 2)
rect = rect.morph(rect_center,fitz.Matrix(scale,scale))
if span['font'].lower() == 'simsun':
fontname = 'china-ss'
elif span['font'].lower() == 'simhei':
fontname = 'china-s'
else:
fontname = 'china-s'
page.add_redact_annot(
rect,
text,
fontname=fontname,
fontsize=fontsize,
text_color=span['color'],
)
count -= 1
modify = True
if count == 0:
break
if not modify:
print(f'not found {search}')
return
page.apply_redactions()
save_path = pdf.with_name(pdf.stem + '_modify.pdf')
doc.save(save_path)
def test():
find_replace(page,'100','200')

结果如上,还是有点不完美,数字和字母都变成全角的了,字体大小看起来也有差别,主要是跟自带的china-ss字体有关系
如果想要完美一点的话可能要自己添加字体,或者先删除再插入文本框,中英文字体区分一下.


















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









