






前言:做码农这么多年,我也读过很多开源软件或者框架的源码,在我看来,Redis是我看过写得最优美、最像一件艺术品的软件,正如Redis之父自己说的那样,他宁愿以一个糟糕的艺术家身份而不是一名好程序员被别人记住,我认为他不仅做到了,而且还是一个非常高超的艺术家。记得当年看源码时,我不禁发出感叹:原来用C语言也可以写出如此美妙、优雅的代码来!
Redis经过十多年的发展,几乎是所有公司必不可少的中间件了,要么用其做缓存,要么做数据统计,或者分布式锁,有些电商还会用Redis做购物车(突然让我想起来,那是在2019年,前东家,当时我们用的是codis搭的Redis集群,Redis集群挂了,导致大促时大家都操作不了购物车,这家把老板急的,现在还印象深刻,哈哈。)。Redis之所以如此受到欢迎,主要还是得益于其丰富的数据结构和较高的性能。Redis官方给出了单机的Redis性能,在忽略带宽影响的前提下,Redis的单机QPS可达到10万QPS。下图是使用Redis benchmark做的性能测试:
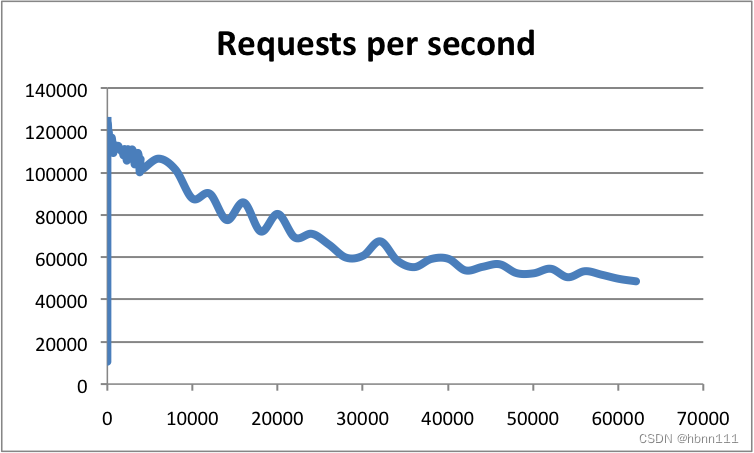
Redis的卓越性能主要原于以下几个方面:
- 使用内存进行数据读写;
- IO多路复用,复用思想提高请求处理能力;
- 后台线程处理耗时任务,异步线程不阻塞主线程;
- IO多线程,进一步提升网络请求处理性能;
1、使用内存
多数情况下我们编写的计算机任务都是IO密集型的,80%甚至更多的时间都是在处理各种IO,磁盘IO,网络IO等等,Redis为了提升读写性能,让主线程的所有读写完全是在内存中进行,从而不需要数据磁盘和内核缓冲区之间的拷贝,我认为这是其性能较好的最重要原因。
虽然Redis使用内存存储,但和Memcached不同的是,Redis是支持持久化的,即内存中的数据是可以持久化到磁盘文件中,从而可保证在断电重启后恢复数据以及支持主从复制。Redis的持久化包含RDB以及AOF持久化两种。
RDB类似Mysql基于Row模式的binlog,即存储的是数据本身,是一种数据快照,RDB在全量复制以及断电恢复中非常有用,由于都是数据,所以恢复较快。Redis生成RDB文件的过程并不是在主进程中完成,其会fork出一个子进程来完成RDB文件生成,并不会阻塞主进程,此外其还充分利用了写时复制(COW)的机制,fork的子进程依然会和父进程共享物理内存,因此不会影响主进程处理命令的性能(这里不考虑内存等因素的影响),实现命令是bgsave。
AOF(Append only file),文件记录格式类似于Mysql的基于statment记录的binlong,即记录的是执行命令,当然其只会记录写命令,读命令不会记录。当执行完写命令后,会直接返回客户端,随后主线程还是会将命令写入到AOF文件中,这个过程不会影响当前命令,但会影响下一个命令,因为其是在主进程中进行的。写完AOF之后,实际上此时数据是在PageCache中(我在之前的Linux零拷贝技术浅谈中介绍过),随后Redis可以主动地将数据刷盘,比如每秒刷一次(fsync,这个也是后台线程处理的),也可以同步刷,但会影响性能,也可以直接不管,由操作系统刷盘。
另外一个需要提的是AOF的重写,AOF如果不断地追加命令,会导致文件过大,因此为了缩小AOF的文件,会进行重写,重写的目的是将命令进行整合,比如对同一个Key的写命令整合成一个,从而缩小文件大小。重写的操作也是通过子进程完成的,并不会阻塞主进程。
2、Redis的I/O多路复用
Redis采用单线程IO多路复用来实现高并发,即著名的Reactor单线程模式,默认会使用epoll机制,通过回调函数、红黑树、mmap机制等各种骚操作提升请求处理能力。其中epoll_create用来创建epoll对象,epoll_ctl用于将就绪事件添加到epoll对象中,epoll_wait会检查对象中是否存在就绪事件,如果有就会把数据拷贝从内核拷贝到用户空间。

具体的关于多路复用和Reactor模式的介绍可以看我之前的文章:IO多路复用介绍; Java的NIO及Netty 。
这里可能你有疑问,为啥Redis另辟蹊径,只使用单线程的IO多路复用,这也无法充分发挥多核的优势啊?无法使用是多核是真的,但Redis由于本身使用内存读写数据,因此多数情况下瓶颈并不在CPU上,且使用单线程读写数据并不需要考虑线程安全性,不必加锁,一定程度简化了Redis的复杂度,这也算是作者做的一种权衡。可是,聪明的你,可能还会继续持怀疑态度,如果执行命令耗时较长不会阻塞吗? 网络请求过大时,网络IO还是会阻塞啊? 是的,对待这两个问题,Redis在后续版本中都给了解决方案,对应的就是第三和第四小节。
下面是我在网上发现一个清晰得描述Redis的IO多路复用实现机制得示意图(来自飞哥,开发内功修炼):

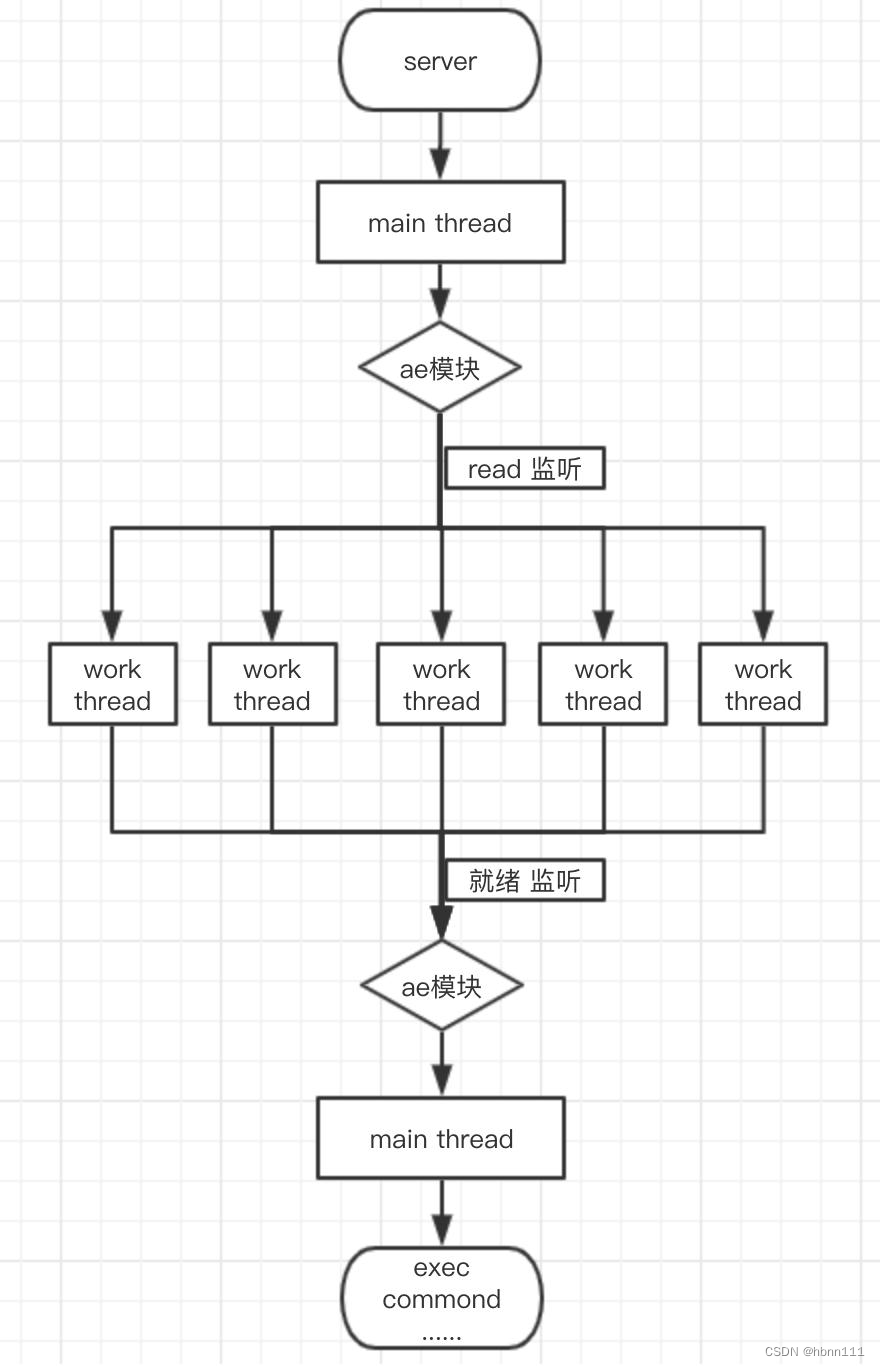
Redis服务端的处理流程:
- Redis 服务启动调用main函数,initServer主要进行主线程事件循环aeCreateEventLoop,注册 acceptTcpHandler 函数,等待新连接到来。看到eventLoop大家应该熟悉,在Netty中你也会看到的,这是IO多路复用的核心;
- 客户端和服务端建立Socket连接;
- Redis Server多路复用接收请求并调用acceptTcpHandler 函数,最终调用 readQueryFromClient 命令读取并解析客户端连接;
- 客户端发送请求,触读就绪事件,主线程调用 readQueryFromClient 读取客户端命令,,并写入querybuf 读入缓冲区;
- 接着调用 processInputBuffer,随后调用 processCommand 执行命令;
- 执行命令后,将响应数据写入到对应客户端的写缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到 client->reply 链表上去,最后把 client 添加进一个 LIFO 队列 clients_pending_write;
- 在事件(文件或定时)循环中,主线程执行 beforeSleep --> handleClientsWithPendingWrites,遍历 clients_pending_write 队列,调用 writeToClient 把 客户端写出缓冲区里的数据发送到客户端,如果写出缓冲区还有数据遗留,则注册 sendReplyToClient 命令回复处理器到该连接的写就绪事件,等待客户端可写时在事件循环中再继续回写剩余的响应数据。
接下来具体看看Redis的实现,入口是src/server.c的main函数。
1、这个函数会进行环境设置、初始化参数、数据恢复等等一系列操作。
int main(int argc, char **argv) {
initServer();
aeMain(server.el);
aeDeleteEventLoop(server.el);
return 0;
}
initServer用于创建epoll,注册定时和文件事件,这是Redis的最重要两类事件。
- 文件事件(file event):Redis客户端通过socket与Redis服务器连接,而文件事件就是服务器对套接字操作的抽象。例如,客户端发了一个GET命令请求,对于Redis服务器来说就是一个文件事件。Redis的协议本身发送的是文本。
- 时间事件(time event):服务器定时或周期性执行的事件。例如,定期执行RDB持久化。
//创建epoll对象
server.el = aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR);
epoll对象创建过程:
aeEventLoop *aeCreateEventLoop(int setsize) {
aeEventLoop *eventLoop;
int i;
if (aeApiCreate(eventLoop) == -1) goto err;
return eventLoop;
}
重要的就是这句aeApiCreate,其用于创建实际的epoll对象。
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
//露出真面目了
state->epfd = epoll_create(1024);
eventLoop->apidata = state;
return 0;
}
2、随后开始注册回调行数,initServer中注册的函数acceptTcpHandler,当有新连接到来时,该函数会被执行。
//注册定时事件,用于执行后台一些业务,如定时清理
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
serverPanic("Can't create event loop timers.");
exit(1);
}
//创建文件事件处理器,用于处理tcp连接。
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
再看一下aeCreateFileEvent函数:
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData)
{
//关键的两句
aeFileEvent *fe = &eventLoop->events[fd];
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return AE_ERR;
fe->mask |= mask;
if (mask & AE_READABLE) fe->rfileProc = proc;
if (mask & AE_WRITABLE) fe->wfileProc = proc;
fe->clientData = clientData;
return AE_OK;
}
aeApiAddEvent会将文件描述符添加到epoll队列中,实际上调用的就是epoll_ctl。至此,Server初始化基本完成。
接着执行aeMain过程,进入死循环:
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
aeProcessEvents(eventLoop, AE_ALL_EVENTS|
AE_CALL_BEFORE_SLEEP|
AE_CALL_AFTER_SLEEP);
}
}
aeProcessEvents调用epoll_wait阻塞,等待事件就绪。
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
//这里是调用epoll_wait阻塞
numevents = aeApiPoll(eventLoop, tvp);
for (j = 0; j < numevents; j++) {
// 从已就绪队列中获取事件
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
//如果是读事件,并且有读回调函数
fe->rfileProc()
//如果是写事件,并且有写回调函数
fe->wfileProc()
}
}
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
// 等待事件
aeApiState *state = eventLoop->apidata;
epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
...
}
这里具体实现机制取决于系统支持哪些,如果不支持epoll,默认会使用select。

假如现在有新连接到来了,此时会调用已注册的acceptTCPHandler函数,我们看下其具体处理流程。
acceptTCPHandler:
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
while(max--) {
//调用accept接收连接
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
acceptCommonHandler(connCreateAcceptedSocket(cfd),0,cip);
}
}
2、然后执行acceptCommonHandler
static void acceptCommonHandler(connection *conn, int flags, char *ip) {
//创建Redis客户端
if ((c = createClient(conn)) == NULL) {
connClose(conn); /* May be already closed, just ignore errors */
return;
}
}
3、创建连接客户端
client *createClient(connection *conn) {
client *c = zmalloc(sizeof(client));
/* passing NULL as conn it is possible to create a non connected client.
* This is useful since all the commands needs to be executed
* in the context of a client. When commands are executed in other
* contexts (for instance a Lua script) we need a non connected client. */
if (conn) {
connNonBlock(conn);
connEnableTcpNoDelay(conn);
if (server.tcpkeepalive)
connKeepAlive(conn,server.tcpkeepalive);
//画重点
connSetReadHandler(conn, readQueryFromClient);
connSetPrivateData(conn, c);
}
}
上面首先创建了一个读事件。
connSetReadHandler(conn, readQueryFromClient);
4、从客户端读取数据
readQueryFromClient
该函数负责读取客户端命令。
5、调用processCommand执行命令,执行具体操作:
int processCommandAndResetClient(lient *c) {
if (processCommand(c) == C_OK) {
commandProcessed(c);
}
}
注意:Redis处理之后,并不是直接将数据返给客户端,而是先加入到写任务队列,在每次循环,首先进行数据发送。
3、后台线程
上面提到了, 由于Redis的命令是单线程的,那如果某个命令出现了阻塞,就会影响到所有命令的执行。就拿我们公司去年发起的几个事故举例,有几个系统创建了big key,且对big key进行批量操作,这直接导致请求量较高时,Redis出现了严重的阻塞。这也是为什么使用Redis时,我们要禁止耗时操作,包括执行keys ,flush,执行批量操作,创建big key等。
为了解决Redis内置命令的一些耗时操作影响主线程,自Redis4.0之后,Redis增加了异步线程的支持,使得一些比较耗时的任务可以在后台异步线程执行,不必再阻塞主线程。之前del和flush等都会阻塞主线程,现在的ulink,flushal async, flushdb async等操作都不会再阻塞。
异步线程是通过Redis的bio实现,即Background I/O,不是我们大家经常说的阻塞IO啊,哈哈。
Redis在启动时,在后台会初始化三个后台线程。
void InitServerLast() {
bioInit();
initThreadedIO();
set_jemalloc_bg_thread(server.jemalloc_bg_thread);
server.initial_memory_usage = zmalloc_used_memory();
}
bioInit就是具体启动后台线程过程。启动的线程主要包括:
#define BIO_CLOSE_FILE 0 /* Deferred close(2) syscall. */
#define BIO_AOF_FSYNC 1 /* Deferred AOF fsync. */
#define BIO_LAZY_FREE 2 /* Deferred objects freeing. */
即用来关闭文件描述符、AOF持久化以及惰性删除。这三个线程是完全独立的,互不干涉。每个线程都会有一个工作队列,用于生产和消费任务。图片来源小林coding:

for (j = 0; j < BIO_NUM_OPS; j++) {
void *arg = (void*)(unsigned long) j;
if (pthread_create(&thread,&attr,bioProcessBackgroundJobs,arg) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize Background Jobs.");
exit(1);
}
bio_threads[j] = thread;
}
主线程负责把相关任务添加到对应线程的队列中,在添加和移除队列中都会加锁,防止并发问题。比如惰性删除的过程,即我们使用UNLINK,flushDB,flushall等命令时。
//添加任务到对应线程队列中,添加过程会加锁
void bioCreateBackgroundJob(int type, void *arg1, void *arg2, void *arg3) {
struct bio_job *job = zmalloc(sizeof(*job));
//加锁
pthread_mutex_lock(&bio_mutex[type]);
//将任务加到队列尾部
listAddNodeTail(bio_jobs[type],job);
pthread_mutex_unlock(&bio_mutex[type]);
}
接下来就是后台线程会从对应队列中取出任务执行:
void *bioProcessBackgroundJobs(void *arg) {
struct bio_job *job;
unsigned long type = (unsigned long) arg;
sigset_t sigset;
switch (type) {
case BIO_CLOSE_FILE:
redis_set_thread_title("bio_close_file");
break;
case BIO_AOF_FSYNC:
redis_set_thread_title("bio_aof_fsync");
break;
case BIO_LAZY_FREE:
redis_set_thread_title("bio_lazy_free");
break;
}
4、IO多线程
上面已提到Redis主要采用单线程IO多路复用实现高并发,后来为了处理耗时比较长的任务,Redis4.0引入了BackGround I/O线程。本身Redis的瓶颈并不是在于CPU,而是内存和网络IO。在一定程度上通过扩容即可。但是业务量不断扩大时,网络IO的瓶颈就体现出来了。这个时候使用多线程处理还是挺香的,可以充分发挥多核的优势,因此Redis6.0就引入了多线程。
不过,这里强调一点,Redis引入了多线程,仅仅是用来网络读写,Redis命令的执行还是通过主线程顺序执行,这主要是为了减少Redis操作的复杂度等方面。
上面在说启动Background IO时,说到了InitServerLast,里面有个initThreadedIO,这个就是初始化线程IO的过程。
初始化线程IO的实现:
void initThreadedIO(void) {
server.io_threads_active = 0; /* We start with threads not active. */
/* Spawn and initialize the I/O threads. */
for (int i = 0; i < server.io_threads_num; i++) {
/* Things we do for all the threads including the main thread. */
io_threads_list[i] = listCreate();
//第一个是主线程,创建完continue
if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */
//worker线程注册回调函数。
pthread_t tid;
pthread_mutex_init(&io_threads_mutex[i],NULL);
setIOPendingCount(i, 0);
pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */
//创建线程,并注册回调函数IOThreadMain
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
io_threads[i] = tid;
}
}
看上面代码,第一个是主线程,其他的都是Worker Thread。
一个图形可以反映上面的实现:
从上面示意图可以看出来,IO处理已经由直线的单线程IO多路复用,改成多线程的IO多路复用处理,在网络IO处理中充分发挥多核的优势。
接下来具体看一下他是怎么实现多线程处理的。其实请求处理流程还是和上面的一致,只是在readQueryFromClient有所不同。
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
/* Check if we want to read from the client later when exiting from
* the event loop. This is the case if threaded I/O is enabled. */
if (postponeClientRead(c)) return;
...
}
如果是开启了线程IO,PostoneClientRead会把事件加入到队列中,待主线程分配给工作线程执行。
/* Return 1 if we want to handle the client read later using threaded I/O.
* This is called by the readable handler of the event loop.
* As a side effect of calling this function the client is put in the
* pending read clients and flagged as such. */
int postponeClientRead(client *c) {
if (server.io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ)))
{
c->flags |= CLIENT_PENDING_READ;
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}
接着,在beforeSleep中会调用处理函数,多线程处理read操作。注意下面的函数注解,主线程也会处理一部分网络IO,同时IO线程也会并发处理,主线程会一直等到所有IO线程执行完。
int handleClientsWithPendingReadsUsingThreads(void) {
if (!server.io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
if (tio_debug) printf("%d TOTAL READ pending clients\n", processed);
/* Distribute the clients across N different lists. */
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
/* Give the start condition to the waiting threads, by setting the
* start condition atomic var. */
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
/* Also use the main thread to process a slice of clients. */
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
//阻塞等待所有IO线程执行完毕
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
if (tio_debug) printf("I/O READ All threads finshed\n");
//开始执行命令
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln);
if (c->flags & CLIENT_PENDING_COMMAND) {
c->flags &= ~CLIENT_PENDING_COMMAND;
if (processCommandAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
}
processInputBuffer(c);
}
return processed;
}
主线程阻塞等待所有的工作线程都完成之后,开始串行执行命令,随后IO线程可以并行将数据发送到写任务队列。
下面是work线程的主要处理逻辑:
void *IOThreadMain(void *myid) {
/* The ID is the thread number (from 0 to server.iothreads_num-1), and is
* used by the thread to just manipulate a single sub-array of clients. */
long id = (unsigned long)myid;
char thdname[16];
snprintf(thdname, sizeof(thdname), "io_thd_%ld", id);
redis_set_thread_title(thdname);
redisSetCpuAffinity(server.server_cpulist);
makeThreadKillable();
while(1) {
/* Wait for start */
for (int j = 0; j < 1000000; j++) {
if (getIOPendingCount(id) != 0) break;
}
/* Give the main thread a chance to stop this thread. */
if (getIOPendingCount(id) == 0) {
pthread_mutex_lock(&io_threads_mutex[id]);
pthread_mutex_unlock(&io_threads_mutex[id]);
continue;
}
serverAssert(getIOPendingCount(id) != 0);
if (tio_debug) printf("[%ld] %d to handle\n", id, (int)listLength(io_threads_list[id]));
/* Process: note that the main thread will never touch our list
* before we drop the pending count to 0. */
listIter li;
listNode *ln;
listRewind(io_threads_list[id],&li);
//处理读写
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
//如果是写,执行writeToClient
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0);
//读操作
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
listEmpty(io_threads_list[id]);
setIOPendingCount(id, 0);
if (tio_debug) printf("[%ld] Done\n", id);
}
}
从上面可以看到,IO线程要么同时读,要么同时写,不可同时包含读和写两部分。
通过ITNEXT平台的测试报告中,可以看到在相同机器配置下,加入多线程后,Redis可支持的最大QPS达到 20W/s。

Redis这部分和Memcached的思想有些类似,Memcached也是通过主线程IO多路复用接受连接,并通过一定算法分配到工作线程。但是,最大的不同是,Redis的多线程只是为了处理网络读写,不负责处理具体业务逻辑,命令还是主线程顺序执行的。然而Memcached是Master线程把连接分配给Worker之后,Worker线程就负责把处理后续的所有请求,完全是多线程执行。Redis要想做到这一点,需要做的工作还有很多,尤其是线程安全方面。据说或许要逐步加Key-level的锁,肯定是不断地完善的。
总结
本文主要介绍了redis的高性能解决方案,包括内存、IO多路复用、后台线程以及IO多线程。 不知道后续的Redis发展会是什么样,会不会真的在命令执行中引入多线程?如果引入的话,这对于Redis来说是一次大的改动。我认为很长一段时间不会这么做,这个我们拭目以待吧。 我们看Redis7里面,主要还是对数据结构、持久化、命令等方面做的优化和调整,并没有特别大的改动。自从2020年Redis之父离开了Redis项目后,我感觉Redis的发展路线会有所改变,就像红楼梦的后四十回是高鹗写的,你不能说不好,只能说可能和曹雪芹最开始的整体规划以及结局是不同的。















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









