






来源:ICML 2021
Introduction
大部分计算机视觉工作都基于预先定义的标签来训练,这种有监督的方式限制了模型的泛化能力和实用性。
NLP领域已经有很多工作可以利用大量语料的数据进行自监督训练(BERT GPT T5等…),这些模型的效果已经超越了人工标记的数据集。本文借鉴NLP中的自监督训练方式,利用网上大规模的图片信息来进行训练从而做计算机视觉的任务。
本文使用CLIP(contrastive language-image pre-training)方式进行训练,利用language作为监督信号来学习视觉特征。不预先定义标签类别,直接利用从互联网爬取的400 million 个image-text pair进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉任务——OCR、动作识别、细粒度分类。举例来说,本文无需利用ImageNet的数据进行训练,就可以达到ResNet-50在该数据集上有监督训练的结果。
Approach
选择自然语言作为监督信息能够给图像一个更细粒度的标签信息,更容易泛化到其它任务上。作者为了得到满意的结果,采用了大模型+大数据的训练方式。作者先收集了一个足够大的图文对数据集(400M),命名为WIT。然后再多个模型(视觉模型从ResNet的各种变体到ViT的各种变体,文本模型采用CBOW或者Text transformer)上进行训练。
为了更加高效的进行训练,作者选择使用对比学习方法进行训练。如下图所示,对角线的特征看作正样本,其它为负样本。
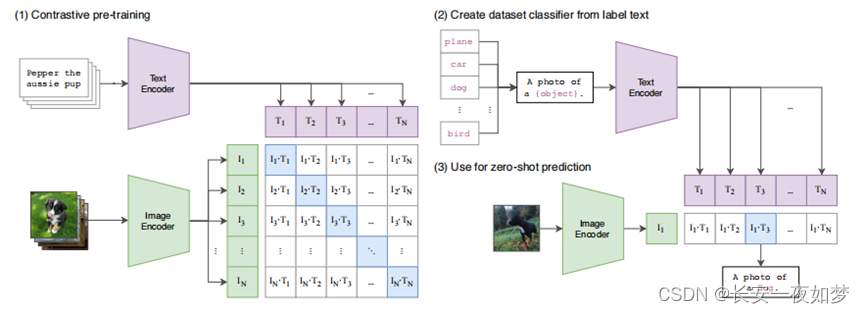
测试时,模型可以很容易的泛化到各种任务中,如分类任务只需要将类别信息补充为一个句子,然后计算与图像的相似度即可。
Experiments
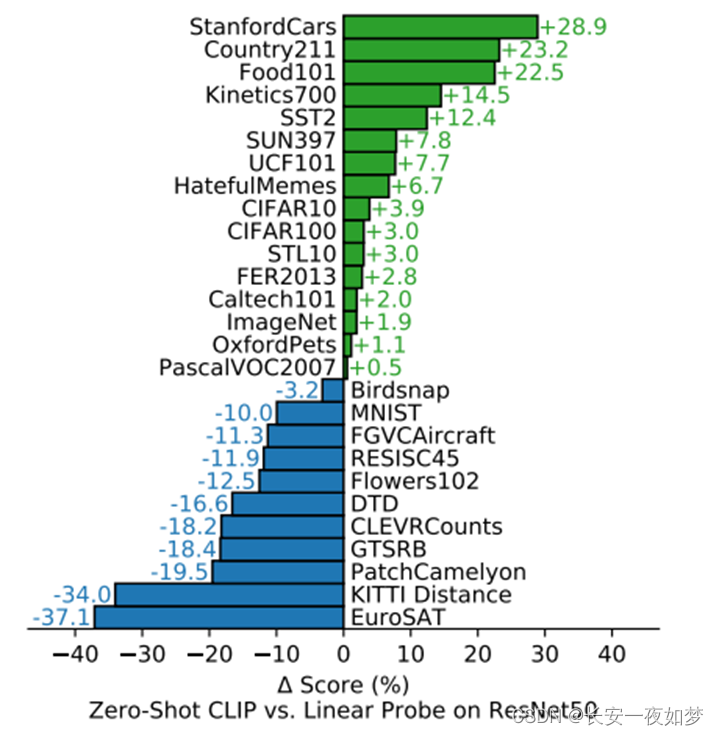
作者做了很多实验,这里只列出分类结果,使用resnet50的Linear Probe(固定预训练模型,只训练FC)和zero-shot(直接迁移)的CLIP作比较。发现,在复杂数据集(如纹理识别、物体计数)上CLIP效果较差,但是在普通数据集上的迁移结果明显要好。
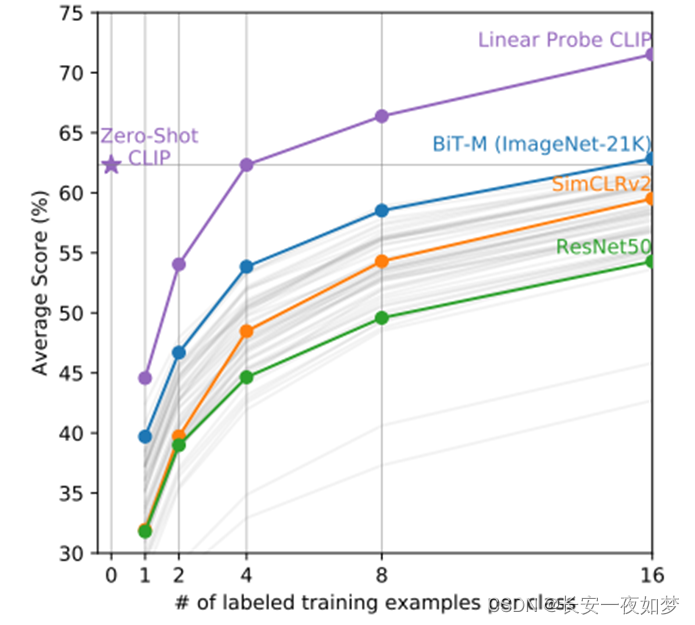
另外当使用有标签数据训练(few-shot)时,可以发现CLIP的结果优于其他模型,证明了CLIP能够提取出更好的特征。















 5568
5568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









