






摘要
提出一个新的模型做图片分类
现在的计算机视觉系统:先有一个固定的。提前已经定义好的物体类别的集合,模型去预测这些已经提前定义好的类别,完成模型训练(限制性的监督信号,限制了模型本省的泛化)
本文:直接从文本中得到监督信号(语言描述这个物体,这个视觉模型就有可能能够识别到这个物体)
训练过程:给一些图片,给一些句子,模型需要去判断哪一个句子和图片配对
本文采用多模态的对比学习完成训练(图片加文本)
1 引言
直接从原始数据里去预训练一个模型,在nlp领域取得了成功(bert,gpt)。大规模的没有标注的数据效果优于有标注的数据。
视觉领域:在imageNet上预训练一个模型
从数据入手,收集了超级大的图像文本配对的数据集
迁移学习效果和模型大小呈正相关
结果:clip做的是迁移学习和泛化性能。
讲了一些相关工作
2 方法
方法的核心:利用自然语言的监督信号来训练一个比较好的自然模型
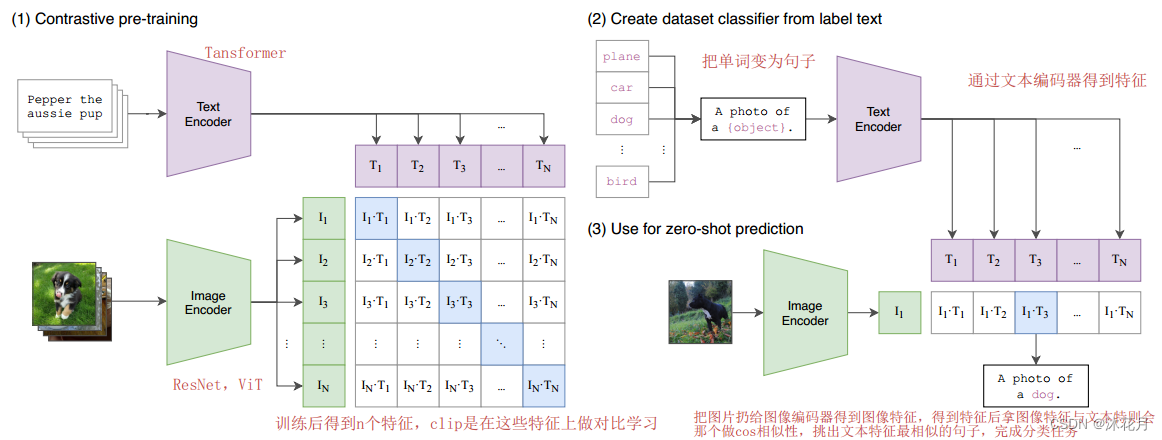
(1)对比学习预训练
模型的输入是图片和文字的配对,图片通过ResNet或者ViT编码器获得图片的特征,对于句子来说呢,可以通过一个文本的Transformer编码器获得文本的特征。clip就是在这些特征上去做对比学习。
对比学习:只需要正样本和负样本的定义,配对的图片文本对就是正样本,其他就是负样本,也就是说正样本有n个,那么负样本有n*n-n个。
clip经过预训练后可以得到视觉和文本上的特征,并没有在分类的任务上做训练和微调。没有分类头
(2)从标签文本创建数据集分类器
clip如何做zero shot的推理(识别没有见过的实体):prompt template
1.先把单词变为句子,经过一个之前预训练的文本编码器后,得到n个文本特征
为什么不直接用单词去得到特征呢?
因为在预训练时,模型也是将图片和句子进行配对,那么在推理的时候,把文本变成单词,那么这样看到的文本额预训练时不一样,效果下降。
(3)使用zero shot推理
把图片扔给预训练好的图片编码器,得到图片的特征。去跟所有的文本特征做cosine similarity(相似性),得到图片特征相似的文本特征,把相应的文本句子挑选出来,得到分类结果。
3 实验
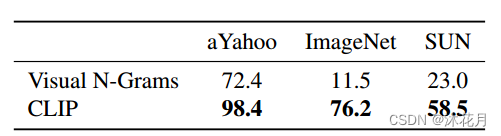
clip(使用了transformer)与Visual N-Grams(没有transformer)相比,在三个数据集上的结果
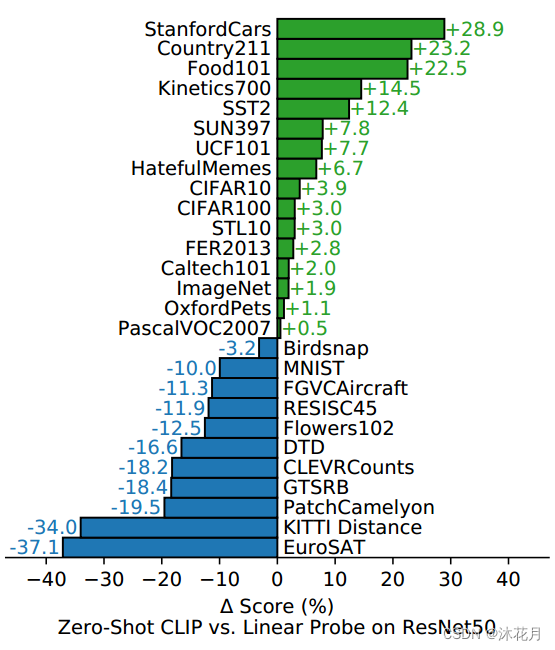
clip相比于ResNet50在不同数据集上的表现















 5577
5577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









