







检验数据逻辑错误大体可分为:输入的选项不符合、录入错误。
一、输入的选项不符合
eg:每行中为零的数据不能超过3个
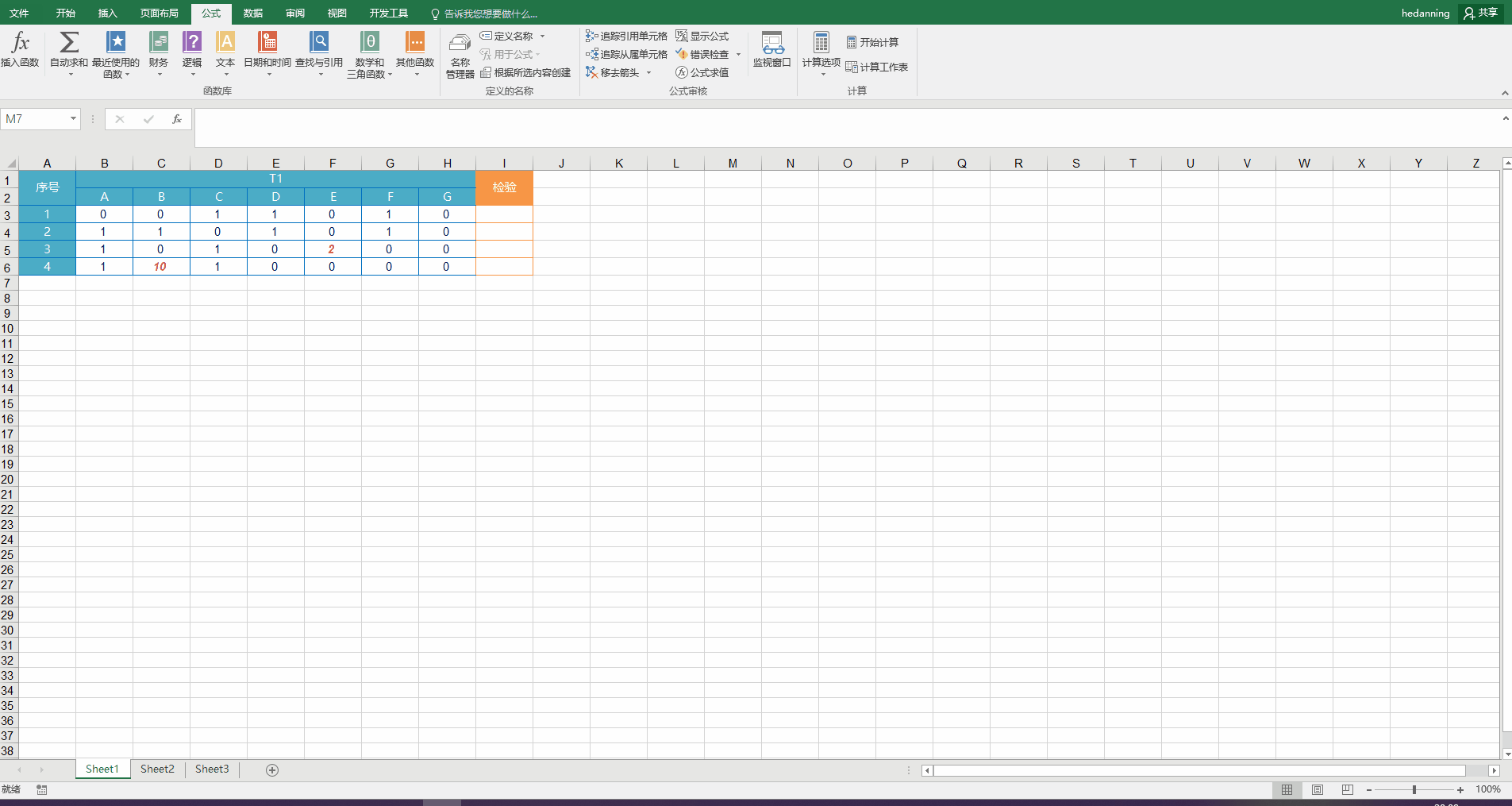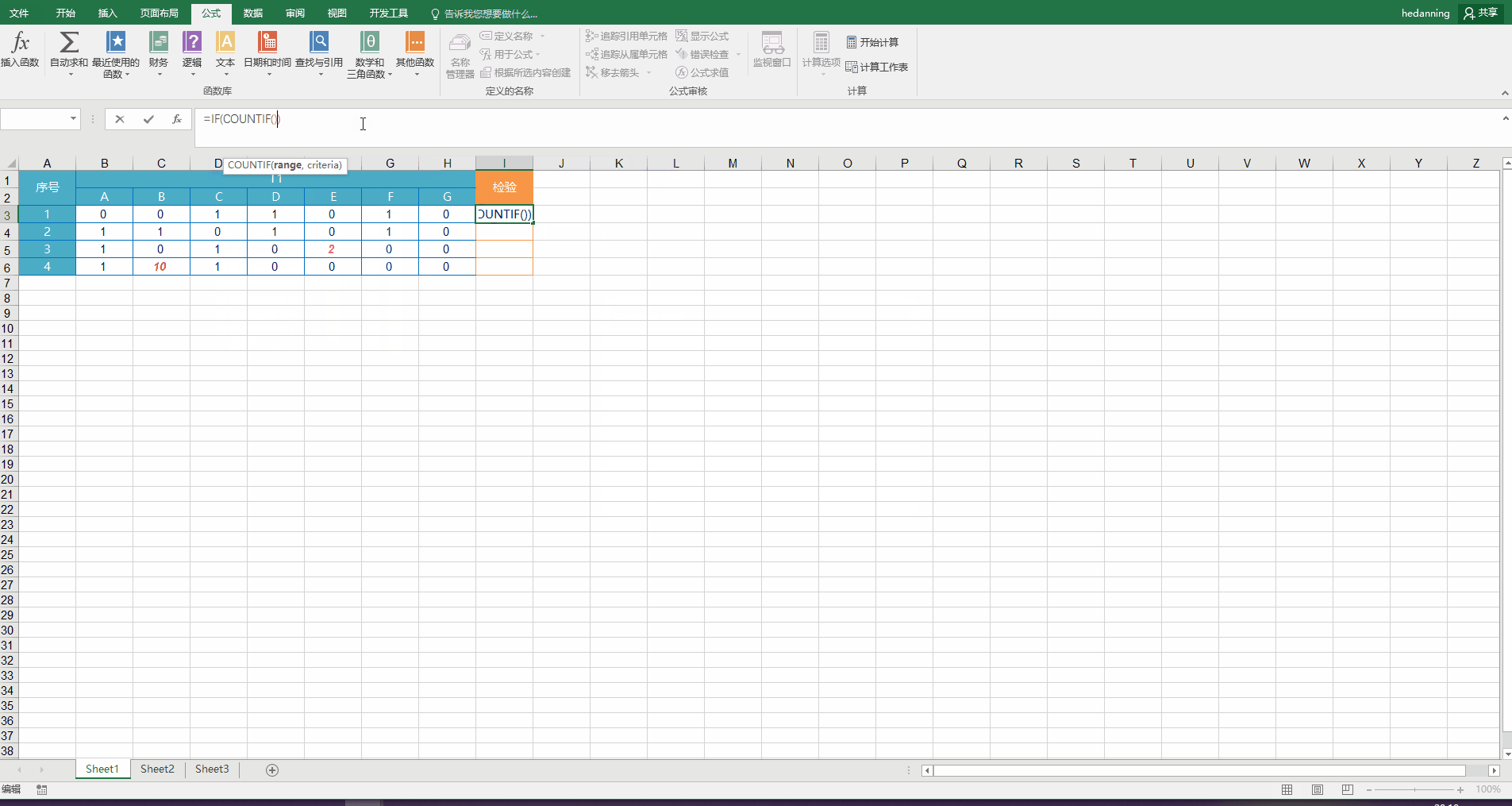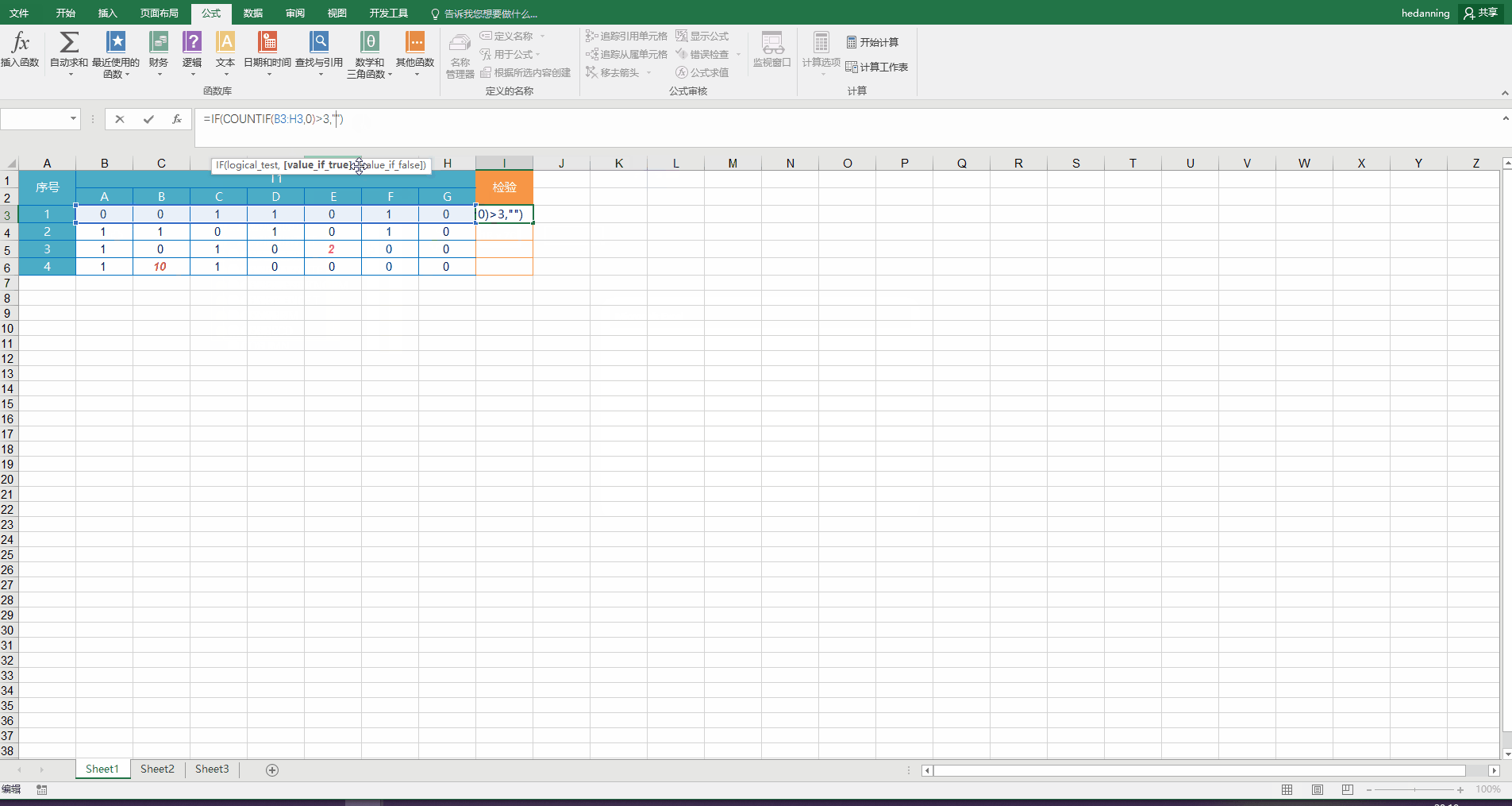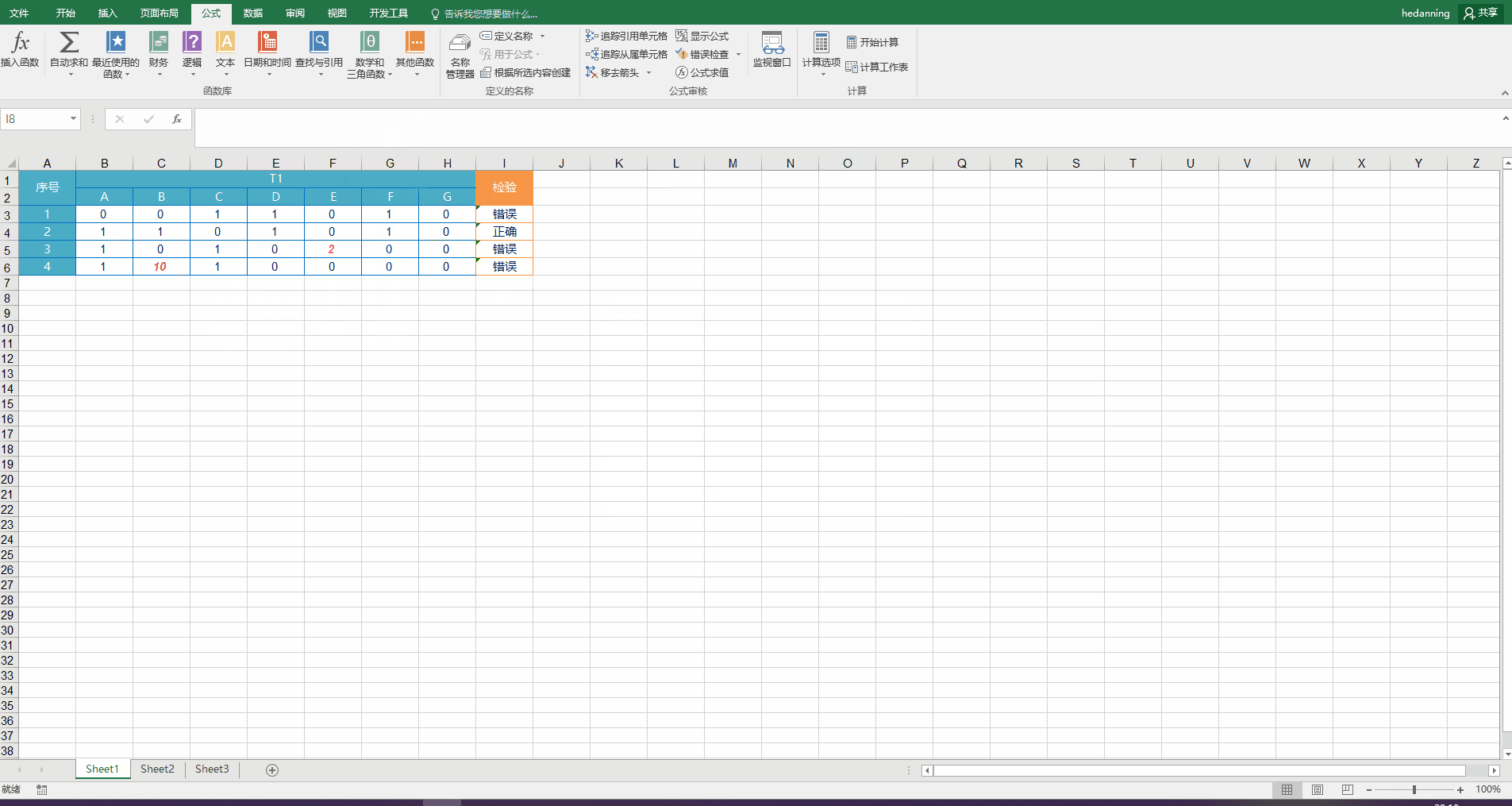
在I3中输入函数 =IF(COUNTIF(B3:H3,0)>3,”错误“,"正确"),回车,然后在I3右下角下拉填充其余行的检验结果。
二、录入错误
检验数据逻辑错误大体可分为:输入的选项不符合、录入错误。
一、输入的选项不符合
eg:每行中为零的数据不能超过3个
在I3中输入函数 =IF(COUNTIF(B3:H3,0)>3,”错误“,"正确"),回车,然后在I3右下角下拉填充其余行的检验结果。
二、录入错误
 214
810
1438
4230
214
810
1438
4230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























