






最近翻看了数据结构与算法有关书籍,总结了八种常用的排序算法,在这里跟大家一起分析总结:
1.简单选择排序
常用于取序列中最大最小的几个数时。
(如果每次比较都交换,那么就是交换排序;如果每次比较完一个循环再交换,就是简单选择排序。)
遍历整个序列,将最小的数放在最前面。
遍历剩下的序列,将最小的数放在最前面。
重复第二步,直到只剩下一个数。

具体代码:
//简单选择排序
public void selectSort( int [] a ){
int len=a.length;
for(int i=0;i<len;i++){ //循环次数
int value=a[i];
int position=i;
for(int j=i+1;j<len;j++){ //找到最小的值和位置
if(a[j]<value){
value=a[j];
position=j; //记录最小值产生的位置,以便交换
}
}
a[position]=a[i]; //进行交换
a[i]=value;
}
}2.直接插入排序
直接插入排序(Straight Insertion Sorting)的基本思想:在要排序的一组数中,假设前面(n-1) [n>=2] 个数已经是排好顺序的,现在要把第n个数插到前面的有序数中,使得这n个数也是排好顺序的。如此反复循环,直到全部排好顺序。
首先设定插入次数,即循环次数,for(int i=1;i<length;i++),1个数的那次不用插入。
设定插入数和得到已经排好序列的最后一个数的位数。insertNum和j=i-1。
从最后一个数开始向前循环,如果插入数小于当前数,就将当前数向后移动一位。
将当前数放置到空着的位置,即j+1。

具体代码:
//插入排序
public void insertSort(int [] src){
int insertNum; //要插入的数
for(int i = 1; i<src.length ; i++){
insertNum = src[i];
int j = i-1;
while(j>=0 && src[j]> insertNum){
src[j+1] = src[j]; //要插入的那个数的原空间空余,这里可以用来向后移动
j--;
}
src[j+1] = insertNum; //找到位置插入当前元素
}
}3.希尔排序
希尔排序(Shell’s Sort)是插入排序的一种,是直接插入排序算法的一种更高版本的改进版本。
- 把记录按步长gap分组,对每组记录采用直接插入排序方法进行排序;
- 随着步长逐渐减小,所分成的组包含的记录越来越多;
当步长值减小到1时,整个数据合成一组,构成一组有序记录,完成排序;
如图:

具体代码:
//希尔排序
public static void shellSort(int [] src){
//定义步长step
for(int step = src.length/2 ;step > 0 ; step = step/2){ //步长每次缩小为 步长/2 直到步长<=0为止
for(int i = step ; i<src.length ; i++){ //控制遍历区间右侧元素
int values = src[i];
int j;
for(j = i - step ; j>=0 && src[j]>src[j+step] ; j-=step){ //控制遍历区间左侧元素
src[j+step] = src[j]; //如果左侧元素大于右侧元素则将两元素进行交换
}
src[j+step] = values; //此时的src[j+step]的值为区间左侧元素的值,因为for循环中执行了j-=step
}
}
}4.冒泡排序
冒泡排序应该是我们比较熟悉的一种排序算法了:
将序列中所有元素两两比较,将大的数向后冒,小的数向前跑。
将剩余序列中所有元素两两比较,将大的数向后冒,小的数向前跑。
重复第二步,直到只剩下一个数。

具体代码:
//冒泡排序
public void maoPaoSort(int [] src){
int n;
boolean flag = true; //flag用来确定是否还要继续循环
while(flag){
flag = false;
for(int i =0 ; i+1<src.length ; i++ ){
if(src[i]>src[i+1]){ //若相邻两值前者大于后者,则交换位置
n = src[i];
src[i] = src[i+1];
src[i+1] = n;
flag = true;
}
}
}
}5.快速排序
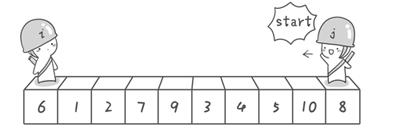
假设我们现在对“6 1 2 7 9 3 4 5 10 8”这个10个数进行排序。首先在这个序列中随便找一个数作为基准数。为了方便,就让第一个数6作为基准数吧。接下来,需要将这个序列中所有比基准数大的数放在6的右边,比基准数小的数放在6的左边,类似下面这种排列:
3 1 2 5 4 6 9 7 10 8
在初始状态下,数字6在序列的第1位。我们的目标是将6挪到序列中间的某个位置,假设这个位置是k。现在就需要寻找这个k,并且以第k位为分界点,左边的数都小于等于6,右边的数都大于等于6。想一想,有办法可以做到这点吗?
方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。先从右往左找一个小于6的数,再从左往右找一个大于6的数,然后交换他们。这里可以用两个变量i和j,分别指向序列最左边和最右边。我们为这两个变量起个好听的名字“哨兵i”和“哨兵j”。刚开始的时候让哨兵i指向序列的最左边(即i=1),指向数字6。让哨兵j指向序列的最右边(即=10),指向数字。
首先哨兵j开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵j先出动,这一点非常重要(请自己想一想为什么)。哨兵j一步一步地向左挪动(即j–),直到找到一个小于6的数停下来。接下来哨兵i再一步一步向右挪动(即i++),直到找到一个数大于6的数停下来。最后哨兵j停在了数字5面前,哨兵i停在了数字7面前。
现在交换哨兵i和哨兵j所指向的元素的值。交换之后的序列如下:
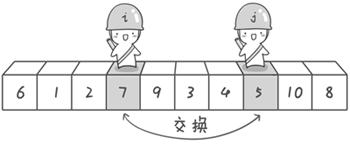
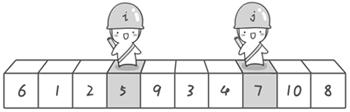
6 1 2 5 9 3 4 7 10 8
到此,第一次交换结束。接下来开始哨兵j继续向左挪动(再友情提醒,每次必须是哨兵j先出发)。他发现了4(比基准数6要小,满足要求)之后停了下来。哨兵i也继续向右挪动的,他发现了9(比基准数6要大,满足要求)之后停了下来。此时再次进行交换,交换之后的序列如下:
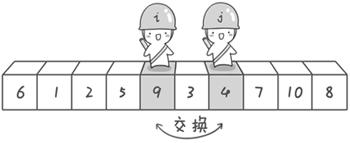
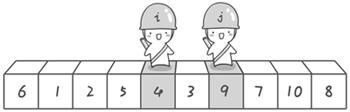
6 1 2 5 4 3 9 7 10 8
第二次交换结束,“探测”继续。哨兵j继续向左挪动,他发现了3(比基准数6要小,满足要求)之后又停了下来。哨兵i继续向右移动,糟啦!此时哨兵i和哨兵j相遇了,哨兵i和哨兵j都走到3面前。说明此时“探测”结束。我们将基准数6和3进行交换。交换之后的序列如下:
3 1 2 5 4 6 9 7 10 8
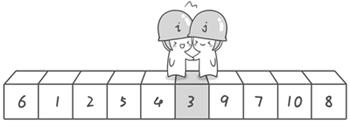
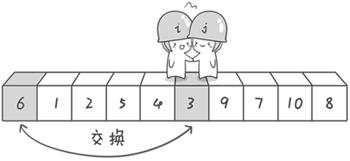
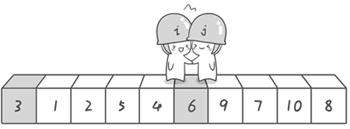
到此第一轮“探测”真正结束。此时以基准数6为分界点,6左边的数都小于等于6,6右边的数都大于等于6。回顾一下刚才的过程,其实哨兵j的使命就是要找小于基准数的数,而哨兵i的使命就是要找大于基准数的数,直到i和j碰头为止。
OK,解释完毕。现在基准数6已经归位,它正好处在序列的第6位。此时我们已经将原来的序列,以6为分界点拆分成了两个序列,左边的序列是“3 1 2 5 4”,右边的序列是“9 7 10 8”。接下来还需要分别处理这两个序列。因为6左边和右边的序列目前都还是很混乱的。不过不要紧,我们已经掌握了方法,接下来只要模拟刚才的方法分别处理6左边和右边的序列即可。现在先来处理6左边的序列现吧。
左边的序列是“3 1 2 5 4”。请将这个序列以3为基准数进行调整,使得3左边的数都小于等于3,3右边的数都大于等于3。好了开始动笔吧
如果你模拟的没有错,调整完毕之后的序列的顺序应该是:
2 1 3 5 4
OK,现在3已经归位。接下来需要处理3左边的序列“2 1”和右边的序列“5 4”。对序列“2 1”以2为基准数进行调整,处理完毕之后的序列为“1 2”,到此2已经归位。序列“1”只有一个数,也不需要进行任何处理。至此我们对序列“2 1”已全部处理完毕,得到序列是“1 2”。序列“5 4”的处理也仿照此方法,最后得到的序列如下:
1 2 3 4 5 6 9 7 10 8
对于序列“9 7 10 8”也模拟刚才的过程,直到不可拆分出新的子序列为止。最终将会得到这样的序列,如下
1 2 3 4 5 6 7 8 9 10
到此,排序完全结束。细心的同学可能已经发现,快速排序的每一轮处理其实就是将这一轮的基准数归位,直到所有的数都归位为止,排序就结束了。
具体代码:
//快速排序
public static void quickSort(int [] src, int start , int end){
int temp,i,j,t;
if(start>end)
return;
temp = src[start];
i = start;
j = end;
while(i<j){
//首先end从右向左移动
while (i<j && src[j]>=temp){
j--;
}
//然后start从左往右开始移动
while (i < j && src[i]<=temp) {
i++;
}
//确定i,j后进行交换
t = src[j];
src[j] = src[i];
src[i] = t;
}
//将基准数与i,j相遇的点进行交换,基准数归位
src[start] = src[i];
src[i] = temp;
quickSort(src, start,j-1);
quickSort(src,j+1,end);
}6.堆排序
对简单选择排序的优化。
将序列构建成大顶堆。
将根节点与最后一个节点交换,然后断开最后一个节点。
重复第一、二步,直到所有节点断开。

具体代码:
//堆排序
public void heapSort(int[] a){
int len=a.length;
//循环建堆
for(int i=0;i<len-1;i++){
//建堆
buildMaxHeap(a,len-1-i);
//交换堆顶和最后一个元素
swap(a,0,len-1-i);
}
}
//交换方法
private void swap(int[] data, int i, int j) {
int tmp=data[i];
data[i]=data[j];
data[j]=tmp;
}
//对data数组从0到lastIndex建大顶堆
private void buildMaxHeap(int[] data, int lastIndex) {
//从lastIndex处节点(最后一个节点)的父节点开始
for(int i=(lastIndex-1)/2;i>=0;i--){
//k保存正在判断的节点
int k=i;
//如果当前k节点的子节点存在
while(k*2+1<=lastIndex){
//k节点的左子节点的索引
int biggerIndex=2*k+1;
//如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if(biggerIndex<lastIndex){
//若果右子节点的值较大
if(data[biggerIndex]<data[biggerIndex+1]){
//biggerIndex总是记录较大子节点的索引
biggerIndex++;
}
}
//如果k节点的值小于其较大的子节点的值
if(data[k]<data[biggerIndex]){
//交换他们
swap(data,k,biggerIndex);
//将biggerIndex赋予k,开始while循环的下一次循环,重新保证k节点的值大于其左右子节点的值
k=biggerIndex;
}else{
break;
}
}
}
}7.归并排序
归并排序是采用分治法的一个非常典型的应用。归并排序的思想就是先递归分解数组,再合并数组。
将数组分解最小之后,然后合并两个有序数组,基本思路是比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
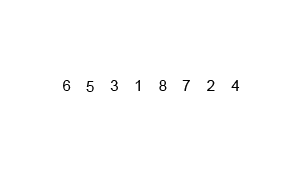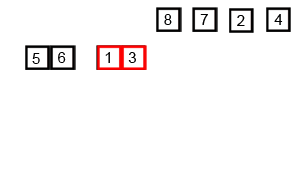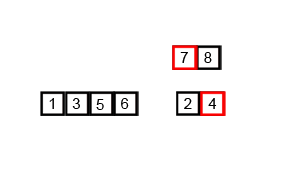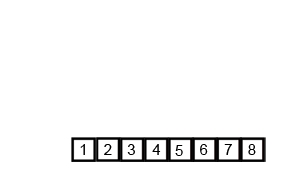
具体代码:
public class Merge
{
public static void main(String[] args)
{
int[] ins = {2,3,5,1,23,6,78,34,23,4,5,78,34,65,32,65,76,32,76,1,9};
int[] ins2 = sort(ins);
for(int in: ins2){
System.out.println(in);
}
}
public static int[] sort(int[] ins){
if(ins.length <=1){
return ins;
}
int num = ins.length/2;
int[] temp=Arrays.copyOfRange(ins, 0, num);
int[] left = sort(Arrays.copyOfRange(ins, 0, num));
int[] right = sort(Arrays.copyOfRange(ins, num, ins.length));
return merge(left,right);
}
public static int[] merge(int[] left, int[] right){
int l=0;
int r=0;
List<Integer> list = new ArrayList<Integer>();
while(l<left.length && r<right.length){
if(left[l] < right[r]){
list.add(left[l]);
l += 1;
}else{
list.add(right[r]);
r += 1;
}
}
if(l>=left.length){
for(int i=r; i<right.length; i++){
list.add(right[i]);
}
}
if(r>=right.length){
for(int i=l; i<left.length; i++){
list.add(left[i]);
}
}
int[] result = new int[list.size()];
for(int i=0; i<list.size(); i++){
result[i] = list.get(i);
}
return result;
}
}
8.基数排序(了解即可)
用于大量数,很长的数进行排序时。
将所有的数的个位数取出,按照个位数进行排序,构成一个序列。
将新构成的所有的数的十位数取出,按照十位数进行排序,构成一个序列。
具体代码:
//基数排序
public void baseSort(int[] a) {
//首先确定排序的趟数;
int max = a[0];
for (int i = 1; i < a.length; i++) {
if (a[i] > max) {
max = a[i];
}
}
int time = 0;
//判断位数;
while (max > 0) {
max /= 10;
time++;
}
//建立10个队列;
List<ArrayList<Integer>> queue = new ArrayList<ArrayList<Integer>>();
for (int i = 0; i < 10; i++) {
ArrayList<Integer> queue1 = new ArrayList<Integer>();
queue.add(queue1);
}
//进行time次分配和收集;
for (int i = 0; i < time; i++) {
//分配数组元素;
for (int j = 0; j < a.length; j++) {
//得到数字的第time+1位数;
int x = a[j] % (int) Math.pow(10, i + 1) / (int) Math.pow(10, i);
ArrayList<Integer> queue2 = queue.get(x);
queue2.add(a[j]);
queue.set(x, queue2);
}
int count = 0;//元素计数器;
//收集队列元素;
for (int k = 0; k < 10; k++) {
while (queue.get(k).size() > 0) {
ArrayList<Integer> queue3 = queue.get(k);
a[count] = queue3.get(0);
queue3.remove(0);
count++;
}
}
}
}总结
一、稳定性:
稳定:冒泡排序、插入排序、归并排序和基数排序
不稳定:选择排序、快速排序、希尔排序、堆排序
二、平均时间复杂度
O(n^2):直接插入排序,简单选择排序,冒泡排序。
在数据规模较小时(9W内),直接插入排序,简单选择排序差不多。当数据较大时,冒泡排序算法的时间代价最高。性能为O(n^2)的算法基本上是相邻元素进行比较,基本上都是稳定的。
O(nlogn):快速排序,归并排序,希尔排序,堆排序。
其中,快排是最好的, 其次是归并和希尔,堆排序在数据量很大时效果明显。
三、排序算法的选择
1.数据规模较小
(1)待排序列基本序的情况下,可以选择直接插入排序;
(2)对稳定性不作要求宜用简单选择排序,对稳定性有要求宜用插入或冒泡
2.数据规模不是很大
(1)完全可以用内存空间,序列杂乱无序,对稳定性没有要求,快速排序,此时要付出log(N)的额外空间。
(2)序列本身可能有序,对稳定性有要求,空间允许下,宜用归并排序
3.数据规模很大
(1)对稳定性有求,则可考虑归并排序。
(2)对稳定性没要求,宜用堆排序
4.序列初始基本有序(正序),宜用直接插入,冒泡

好了,到这里我们就把常用的八种排序算法总结完了,其中选择排序,插入排序,希尔排序,冒泡排序,快速排序是必须能独立敲出来掌握的,其他三种也要能理解其实现思想。大家 加油!














 6233
6233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









