










决策树:
ID3算法:
1、香农熵:
如果待分类的事务可能划分在多个分类中,则
x
i
的信息定义为:
![]()
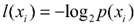 ,
其中
p
(
x
i
)
选择该分类的概率。
,
其中
p
(
x
i
)
选择该分类的概率。
,
其中
p
(
x
i
)
选择该分类的概率。
熵定义为信息的期望值,计算公式为:![]()
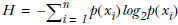 ,当熵越高时,说明不同类型的数据越多,数据集集合无序程度越高。
,当熵越高时,说明不同类型的数据越多,数据集集合无序程度越高。
,当熵越高时,说明不同类型的数据越多,数据集集合无序程度越高。
选择dataSet数据集中最后一项分类(
featVec[-
1
])的香农熵计算,代码实现如下:
- import math
- def calcShannonEnt(dataSet):
- numEntries = len(dataSet)
- labelCounts = {}
- for featVec in dataSet:
- currentLabel = featVec[-1]
- labelCounts[currentLabel] = labelCounts.get(currentLabel, 0) + 1
- shannonEnt = 0.0
- for key in labelCounts:
- prob = float(labelCounts[key])/numEntries
- shannonEnt -= prob * math.log(prob,2)
- return shannonEnt
2、按给定的特征划分数据集:
- def splitDataSet(dataSet, axis, value):
- retDataSet = []
- for featVec in dataSet:
- if featVec[axis] == value:
- reducedFeatVec = featVec[:axis]
- reducedFeatVec.extend(featVec[axis+1:])
- retDataSet.append(reducedFeatVec)
- return retDataSet
有点类似Excel中的筛选功能,如下图等价于
featVec[1] == 'prescript'
筛选后的矩阵列表
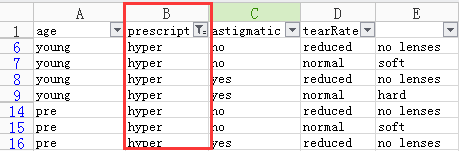
步骤1:选择包含某个字段的列进行筛选(
if
featVec[axis] == value
)
步骤2:Excel自动得到第X列中包含‘value’的矩阵列表,但python需要进行切片和组合,如下:
- reducedFeatVec = featVec[:axis]
- reducedFeatVec.extend(featVec[axis+1:])
- retDataSet.append(reducedFeatVec)
tips:list.append 和 list.extend 的区别,两者都是在列表末尾添加元素:
>>> a = [1,2,3]
>>> b = [4,5,6]
>>> a.append(b)
>>> a
[1, 2, 3, [4, 5, 6]]
>>> b = [4,5,6]
>>> a.append(b)
>>> a
[1, 2, 3, [4, 5, 6]]
如果执行append方法,则列表得到第四个元素,而第四个元素也是一个列表
>>> a = [1,2,3]
>>> a.extend(b)
>>> a
[1, 2, 3, 4, 5, 6]
>>> a.extend(b)
>>> a
[1, 2, 3, 4, 5, 6]
使用extend方法,则得到一个包含a和b所有元素的列表
3、选择最好的数据集划分方式:
要求1:数据必须是一种有列表元素组成的列表,而且所有的列表元素都要具有相同的数据长度;
要求2:数据的最后一列或者每个实例的最后一个元素是当前实例的类别标签。
- def chooseBestFeatureToSplit(dataSet):
- numFeatures = len(dataSet[0]) - 1
- baseEntropy = calcShannonEnt(dataSet)
- bestInfoGain = 0.0; bestFeature = -1
- #创建唯一的分类标签列表
- for i in range(numFeatures):
- featList = [example[i] for example in dataSet]
- uniqueVals = set(featList)
- newEntropy = 0.0
- #计算每种划分方式的信息熵
- for value in uniqueVals:
- subDataSet = splitDataSet(dataSet, i, value)
- prob = len(subDataSet)/float(len(dataSet))
- newEntropy += prob * calcShannonEnt(subDataSet)
- infoGain = baseEntropy - newEntropy
- #计算最好的信息增益
- if (infoGain > bestInfoGain):
- bestInfoGain = infoGain
- bestFeature = i
- return bestFeature
4、创建树:
生成直方图,选出出现次数最多的类别,代码如下:
- def majorityCnt(classList):
- classCount={}
- for vote in classList:
- if vote not in classCount.keys(): classCount[vote] = 0
- classCount[vote] += 1
- sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
- return sortedClassCount[0][0]
用递归的方式创建树,代码如下:
- def createTree(dataSet,labels):
- classList = [example[-1] for example in dataSet]
- if classList.count(classList[0]) == len(classList):
- return classList[0] #类别完全相同则停止继续划分
- if len(dataSet[0]) == 1: #遍历完所有特征时返回出现次数最多的
- return majorityCnt(classList)
- bestFeat = chooseBestFeatureToSplit(dataSet)
- bestFeatLabel = labels[bestFeat]
- myTree = {bestFeatLabel:{}}
- del(labels[bestFeat])
- featValues = [example[bestFeat] for example in dataSet]
- uniqueVals = set(featValues)
- for value in uniqueVals:
- subLabels = labels[:] #得到列表包含的所有属性值
- myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
- return myTree
4、决策树存储:
递归算法运行太慢,所以需要把生成的决策树进行保存,存储&读取代码如下:
- def storeTree(inputTree,filename):
- import pickle
- fw = open(filename,'w')
- pickle.dump(inputTree,fw)
- fw.close()
- def grabTree(filename):
- import pickle
- fr = open(filename)
- return pickle.load(fr)















 1487
1487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









