






近日,谷歌团队在arXiv上发布了新论文《End-to-End Learning of Semantic Grasping》,这篇文章由谷歌成员Eric Jang、Sudheendra Vijayanarasimhan、Julian Ibarz、Sergey Levine和Peter Pastor五人共同完成。
量子位选取论文中关键信息,编译整理分享给大家。

实验介绍
这篇论文首先讨论了机器人的语义抓取任务,即机器人借助单目图像抓取用户指定类别的相应物体。受视觉神经处理模型中双流假说的启发,研究人员提出了一种语义抓取框架,它允许用端对端的方式学习物体识别、分类并设计抓取路线。

△ 工作人员根据用户指定,将测试用的杂物分为16类
受双流假说的启发,研究人员将模型分为“腹流”和“背流”。

△ 背流(绿色)与腹流(紫色)源于视觉皮层的同一区域/维基百科
在这个模型中,腹流负责识别物体类别,背流同时解释正确抓取所需的几何图形关系。测试人员利用机器人自主数据采集能力获取了大量自监督数据集来训练背流,并用半监督学习中的标签传播算法训练腹流,同时佐以适当的人力监督。
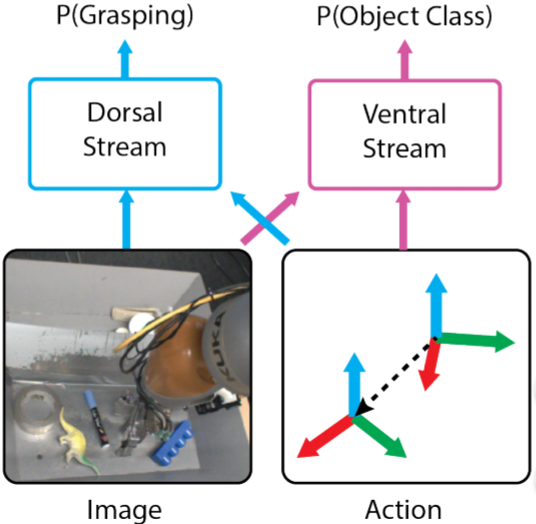
△ 受双流假设的影响,将模型分为了腹流和背流
论文用实验方法展示了改进后的抓取系统方法。当然这不仅仅包含端对端内容,还包括用边界框检测的基线处理方法。不仅如此,还展示了用辅助数据、无语义抓取数据和无掌握操作以及语义标记图像共同训练的模型,这可能会大大提高语义抓取性能。

△ 实验所用的机器人手臂,具有两只手指和单目图像相机
实验结果
在本次实验中,通过让机器人在不同类别的物体中,抓取随机指定的五个物体来评估机器人的语义抓取能力。每次实验重复10次,抓取的物体包含一组30个训练对象和30个未经测试对象。研究人员通过基线比较证明各种架构在决策语义抓取模型中的作用。

△ 对比实验结果统计表
本实验的结果可总结为如下6点:
1)端对端的语义抓取优于传统的检测分类方法
2)双流语义分解预测优于单流模型
3)分离架构的理解能力胜过双支路架构
4)9层含attention的CNN表现胜过16层无attention的CNN
5)辅助语义数据能够增强双流架构的分类表现
6)反映物体分布的辅助语义数据提高了分类抓取的准确性















 959
959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









