









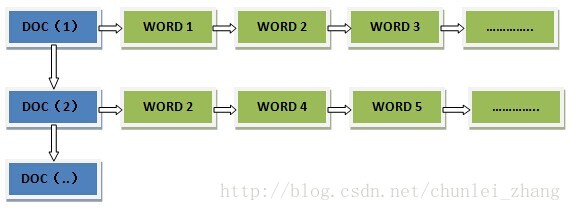
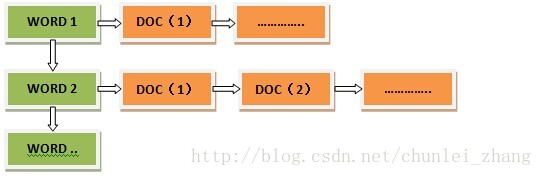
传统的方式(正排索引)是从关键点出发,然后再通过关键点找到关键点代表的信息中能够满足搜索条件的特定信息,既通过KEY寻找VALUE。而Lucene的搜索则是采用了倒排索引的方式,即通过VALUE找KEY。而在中文全文搜索中VALUE就是我们要搜索的单词,存放所有单词的地方叫词典。KEY是文档标号列表(通过文档标号列表我们可以找到出现过要搜索单词VALUE的文档)
正排索引从文档编号找词:
倒排索引是从词找文档编号:
当文档数据来临时,solr会首先对文档数据进行分词,创建索引库和文档数据库。所谓的分词是指:将一段字符文本按照一定的规则分成若干个单词。如下面两篇文档通过solr后如何产生分词存储:

文章中的标点符号可以直接过滤掉,像and、too可以直接过滤掉。形成的分词表表示:

Lucene的倒排索引存储结构为:词项的字符串+词项的文档频率+记录词项的频率信息+记录词项的位置信息+跳跃偏移量。简单的理解可以形成以下结构:
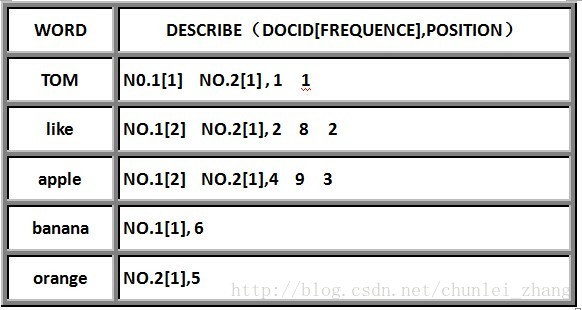
分别表示词,词出现的文档编号,文档中出现的频率和文档中出现的位置。这样当我们对词进行搜索时,会找到该词出现过的所有文档的ID,然后再通过该文档的ID寻找文档的具体内容。
当然,Lucene词典中词的顺序是按照英文字母的顺序排列的,这样就可以采用压缩存储:假设有term,termagancy,termagant,termina四个词。每个字母需要1byte的空间,常规存储一共需要35byte。而压缩存储之后为:"term4agancy8t4inal",一共需要22byte,节省大量的空间。















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









