




 本文详细介绍了广度优先搜索算法,包括其工作原理、伪代码实现,以及时间复杂度和空间复杂度分析。此外,文中列举了BFS在多个IT领域的实际应用,如索引构建、GPS导航等。
本文详细介绍了广度优先搜索算法,包括其工作原理、伪代码实现,以及时间复杂度和空间复杂度分析。此外,文中列举了BFS在多个IT领域的实际应用,如索引构建、GPS导航等。
广度优先搜索
遍历意味着访问图的所有节点。广度优先遍历或广度优先搜索是一种用于搜索图或树数据结构的所有顶点的递归算法。
广度优先搜索算法
标准 BFS 实现将图的每个顶点归入以下两个类别之一:
1、访问过
2、未访问过
该算法的目的是将每个顶点标记为已访问,同时避免循环。
该算法的工作原理如下:
1、首先将图的任意一个顶点放在队列的后面。
2、取出队列的最前面的项目并将其添加到访问列表中。
3、创建该顶点的相邻节点的列表。将不在访问列表中的添加到队列的后面。
4、继续重复步骤 2 和 3,直到队列为空。
该图可能有两个不同的断开部分,因此为了确保覆盖每个顶点,我们还可以在每个节点上运行 BFS 算法。
广度优先搜索示例
让我们通过一个例子来看看广度优先搜索算法是如何工作的。我们使用具有 5 个顶点的无向图。
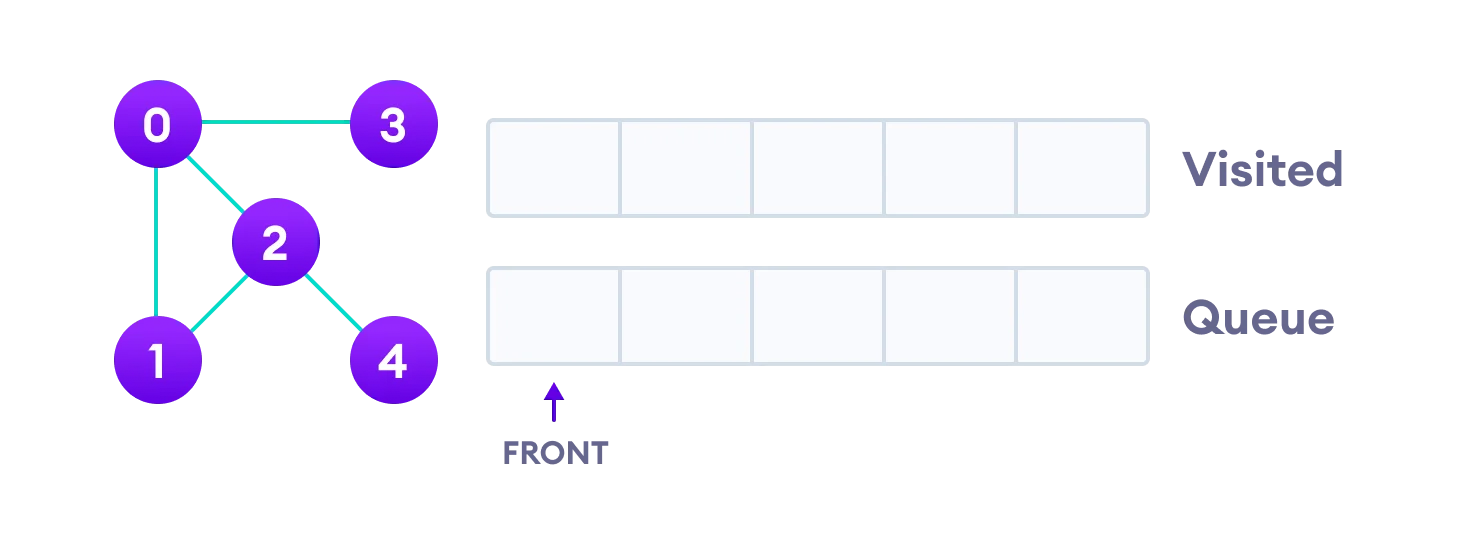 具有 5 个顶点的无向图
具有 5 个顶点的无向图
我们从顶点 0 开始,BFS 算法首先将其放入 Visited 列表中,并将其所有相邻顶点放入堆栈中。
 访问起始顶点并将其相邻顶点添加到队列中
访问起始顶点并将其相邻顶点添加到队列中
接下来,我们访问队列前面的元素(即 1)并访问其相邻节点。由于 0 已经被访问过,所以我们访问 2。

访问起始节点0的第一个邻居,即1
顶点 2 在 4 中有一个未访问的相邻顶点,因此我们将其添加到队列的后面并访问位于队列前面的 3。
 访问之前添加到队列中的 2 以添加其邻居
访问之前添加到队列中的 2 以添加其邻居

4 仍在队列中
队列中只剩下 4 个节点,因为 3 的唯一相邻节点(即 0)已经被访问过。我们参观它。
 访问队列中最后剩余的项目以检查它是否有未访问的邻居
访问队列中最后剩余的项目以检查它是否有未访问的邻居
由于队列为空,我们就完成了图的广度优先遍历。
广度优先搜索伪代码
create a queue Q
mark v as visited and put v into Q
while Q is non-empty
remove the head u of Q
mark and enqueue all (unvisited) neighbours of u
广度优先搜索算法的代码及其示例如下所示。代码已被简化,以便我们可以专注于算法而不是其他细节。
# BFS algorithm in Python
import collections
# BFS algorithm
def bfs(graph, root):
visited, queue = set(), collections.deque([root])
visited.add(root)
while queue:
# Dequeue a vertex from queue
vertex = queue.popleft()
print(str(vertex) + " ", end="")
# If not visited, mark it as visited, and
# enqueue it
for neighbour in graph[vertex]:
if neighbour not in visited:
visited.add(neighbour)
queue.append(neighbour)
if __name__ == '__main__':
graph = {0: [1, 2], 1: [2], 2: [3], 3: [1, 2]}
print("Following is Breadth First Traversal: ")
bfs(graph, 0)
BFS算法复杂度
BFS算法的时间复杂度用 的形式表示O(V + E),其中V是节点数,E 是边数。
该算法的空间复杂度为O(V)。
BFS算法应用
1、通过搜索索引建立索引
2、用于 GPS 导航
3、路径寻找算法
4、在 Ford-Fulkerson 算法中找到网络中的最大流量
5、无向图中的循环检测
6、在最小生成树中



















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











