






Zabbix监控平台
监控概念
- 对服务的管理,不能仅限于可用性。
- 还需要服务可以安全、稳定、高效地运行。
- 监控的目的:早发现、早治疗。
- 被监控的资源类型:
- 公开数据:对外开放的,不需要认证即可获取的数据
- 私有数据:对外不开放,需要认证、权限才能获得的数据
Zabbix是什么?
Zabbix是个适用于监控硬件服务器的一款开源的分布式监控方案
- 实施监控的几个方面:
- 数据采集:使用agent(可安装软件的系统上)、SNMP(简单网络管理协议,用于网络设备的数据采集)
- 数据存储:使用mysql数据库
- 数据展示:通过web页面
- 组成部分:
- C/S:数据采集、数据存储
- B/S:数据展示
- 组件:
- MySQL:数据持久化存储
- zabbix-server:数据接收及回写
- zabbix-agent:数据采集
- zabbix-web:数据展示(基于LNMP平台运行的一组PHP代码)
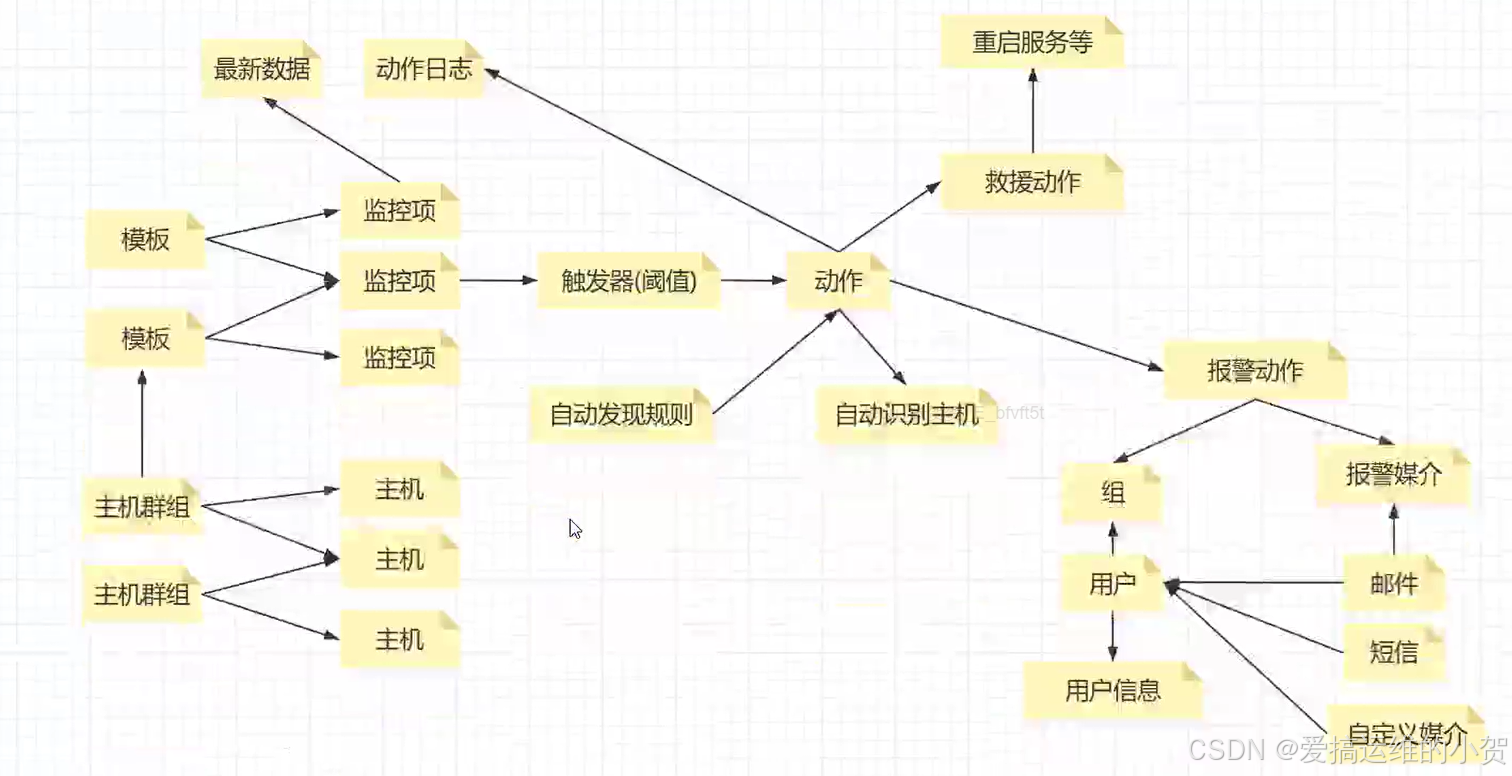
Zabbix核心概念
- 主机: 被监控端,通常是安装了agent的服务器或支持SNMP协议的网络设备
- 主机群组: 主机分类,便于查找监控项:数据采集单位,每个监控项对应一个数据采集点
- 模板: 监控项的分组,便于新增设备时绑定对应的监控项
- 触发器: 定义阈值,表现形式为一个表达式
- 触发器动作: 触发器中定义的闽值被触发后的行为
- 自定义监控项: 语法:UserParameter=键值[*],脚本(shell命令) $1
- 自动发现规则: 定义符合条件的规则
- 自动发现动作: 符合自动发现条件的主机如何处理
- 被动监控:Server向Agent发起连接
- 主动监控:Agent向Server发起连接
- 触发器(trigger)
- 表达式,如内存不足300M,,用户超过30个等
- 当触发条件发生后,会导致一个触发事件
- 触发事件会执行某个动作
- 动作(action)
- 触发器的条件被触发后的行为
- 可以是发送邮件、也可以是重启某个服务等
- 自动发现(Discovery)
- 当Zabbix需要监控的设备越来越多,手动添加监控设备越来越有挑战,此时,可以考虑使用自动发现功能
- 自动发现可以实现:发现主机、添加主机,添加主机到组、链接模板等
Zabbix主被动监控
- 主动和被动都是对被监控端主机而言的
- 默认zabbix采用的是被动监控
- 被动模式:
- server向agent发起索要数据的请求,agent接收到请求后将数据发送给server
- 表现: zabbix-agent服务监听固定端口10050用于连接建立和数据传输
- 主动模式:
- agent按照指定的时间间隔将采集到的数据推送给server
- 表现: zabbix-agent服务不监听固定端口,推送数据时临时启用一个高位端口,传输完成断开连接
- 区别:Server不用每次需要数据都连接Agent,Agent会自己收集数据并处理数据,Server仅需要保存数据即可
Prometheus监控平台
Prometheus是什么?
Prometheus(普罗米修斯):适用于监控云原生领域容器相关指标的一款开源监控方案
- Prometheus是一个开源系统监控和警报工具包,最初由 SoundCloud构建。
- 也是一款监控软件,也是一个时序数据库。Prometheus 将其指标收集并存储为时间序列数据,即指标信息与记录时的时间戳以及称为标签的可选键值对一起存储。
- 主要用在容器监控方面,也可以用于常规的主机监控。
- 使用google公司开发的go语言编写。
- Prometheus是一个框架,可以与其他组件完美结合。
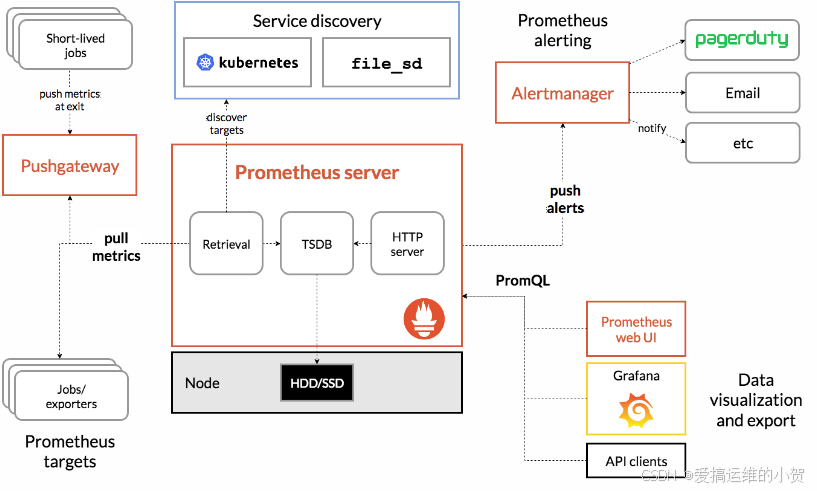
- 组件:
- prometheus-server: 核心组件,负责数据收集、存储和查询。
- xx-exporter: 用于收集各种应用和系统的指标数据,并暴露给 Prometheus 抓取。例如,Node Exporter 用于收集系统级指标,Blackbox Exporter 用于监控外部服务。
- push-gateway: push模式下数据中转站
- Alertmanager: 负责处理告警,可以配置通知规则,并将告警发送到不同的接收器,如邮件、Slack、PagerDuty 等。
- Kubernetes:虽然 Kubernetes 不是 Prometheus 的组件,但 Prometheus 提供了对Kubernetes 集群的监控支持,包括节点、Pod、服务等。
- Grafana:
- Grafana是一款开源的、跨平台的、基于web的可视化工具
- 展示方式:客户端图表、面板插件
- 数据源可以来自于各种源,如prometheus
监控方式
- 拉取:pull。监控端主动向被监控端拉取数据,这样需要被监控端上安装exporters(导出器)作为守护进程
- 推送:push。被监控端主动把数据发给监控端。在prometheus中,被监控端需要安装pushgateway插件,然后运维人员用脚本把监控数据组成键值形式提交给pushgateway,再由它提交给监控端
- 被监控端根据自身运行的服务,可以运行不同的exporter(被监控端安装的、可以与Prometheus通信,实现数据传递的软件)
- exporter列表:Exporters and integrations | Prometheus
自动发现机制
- 自动发现是指Prometheus自动对节点进行监控,不需要手动一个一个去添加,和Zabbix的自动发现、自动注册一个道理
- Prometheus有多种自动发现发现,比如file_sd_configs基于文件自动发现、基于K8S自动发现、基于openstack自动发现、基于consul自动发现等
基于文件自动发现:
- file_sd_configs实现文件级别的自动发现
- 使用文件自动发现功能后,Prometheus会定期检查配置文件是否有更新
- 如果有更新的话就将新加入的节点接入监控,服务端无需重启服务
Alertmanager
- Prometheus服务器中的告警规则向Alertmanager发送告警。然后,Alertmanager管理这些告警,包括静默、抑制、分组以及通过电子邮件、即时消息系统和聊天平台等方法发出通知。
- 设置告警和通知的主要步骤是:
- 设置和配置Alertmanager
- 配置Prometheus与Alertmanager对接
- 在普罗米修斯中创建告警规则
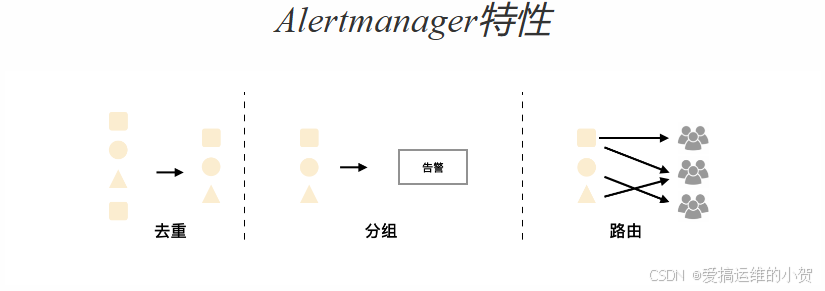
- Alertmanager处理客户端应用程序(如Prometheus服务器)发送的警报。它负责重复数据删除、分组,并将其路由到正确的接收方集成
- 分组:分组将性质相似的警报分类到单个通知中。这在较大的停机期间特别有用,此时许多系统同时发生故障,数百到数千个警报可能同时发出。
- 抑制:抑制是当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
- 静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置, Alertmanager则不会发送告警通知。静默设置需要在Alertmanager的Web页面上进行设置。
常用的监控指标
Prometheus 监控的指标类型非常广泛,以下是一些常用的指标类型:
- 系统指标:
- CPU 使用率:cpu_usage_seconds_total
- 内存使用率:memory_usage_bytes
- 磁盘 I/O 操作数:disk_io_time_seconds
- 网络带宽:
- network_receive_bytes_total
- network_transmit_bytes_total
- Kubernetes 指标:
- Pod 状态:kube_pod_container_status_running、kube_pod_info
- 节点状态:kube_node_status_condition
- 资源使用率:kube_pod_container_resource_requests_cpu、kube_pod_container_resource_requests_memory
- 应用程序指标:
- 请求数:http_requests_total
- 响应时间:http_response_duration_seconds
- 错误率:http_request_errors_total
监控内容&报警标准
Prometheus 可以监控各种系统和应用程序的性能和健康状态,包括但不限于以下内容:
- 系统资源使用情况:CPU、内存、磁盘 I/O、网络带宽等。
- 容器和虚拟机的资源使用情况:Kubernetes Pod、Docker 容器等。
- 应用程序的请求数、响应时间、错误率等指标。
- 数据库的连接数、查询时间、错误率等指标。
- 报警标准
Prometheus 的报警系统基于 Alertmanager 组件,可以根据预定义的报警规则触发报警。以下是一些常见的报警规则示例:
- 高 CPU 使用率:
- 规则:cpu_usage_seconds_total{mode="idle"} > 80
- 描述:当 CPU 空闲时间超过 80% 时,触发报警。
- 高内存使用率:
- 规则:memory_usage_bytes{job="node_exporter"} > 0.8 * node_memory_MemTotal_bytes
- 描述:当节点内存使用率超过 80% 时,触发报警。
- 磁盘空间不足:
- 规则:node_filesystem_avail_bytes{mountpoint="/"} < 10 * 1024 * 1024 * 1024
- 描述:当根文件系统的可用空间小于 10GB 时,触发报警。
- 高错误率:
- 规则:rate(http_request_errors_total[5m]) > 0.01
- 描述:当 5 分钟内的错误率超过 1% 时,触发报警。
- Pod 重启次数过多:
- 规则:kube_pod_container_status_restarts_total > 5
- 描述:当 Pod 容器重启次数超过 5 次时,触发报警。

















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









