







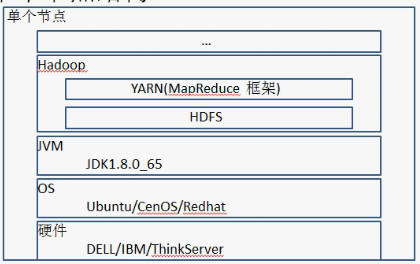
1.单节点体系
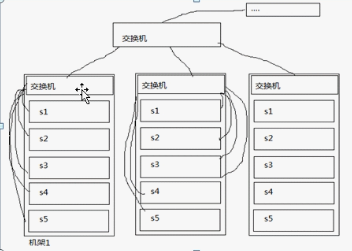
2.集群结构分析
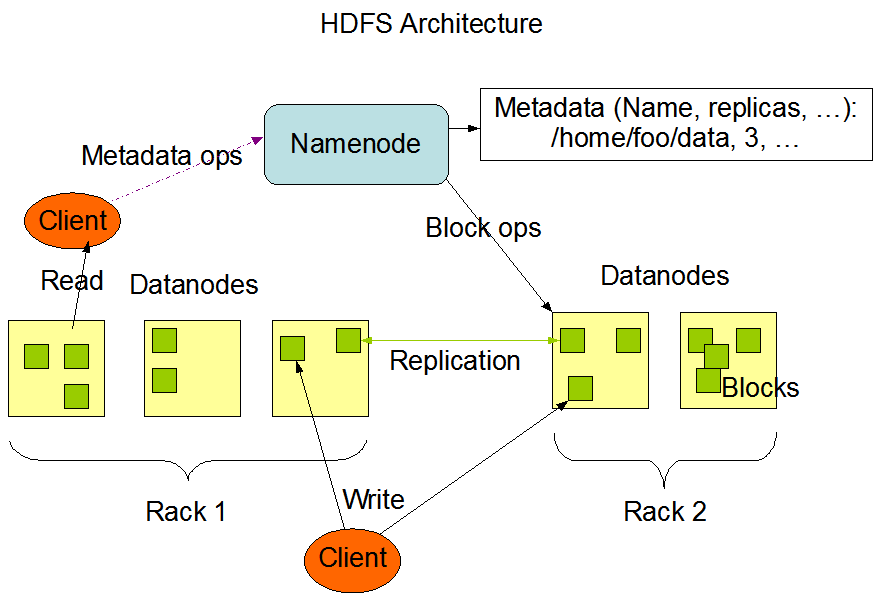
3.HDFS架构分析
Hadoop分布式文件系统;
按需定制MapReduce;》大数据量(纯文本)
目标在于多次的文件流读取;》优势在于一次写入,多次读取
写入成本很高;
高度数据冗余(副本,默认3);
每个节点不需要RAID-独立磁盘冗余阵列:redundant array of independent disks;
Blocksize较大(128m);
定制节点的位置感知;
4.NN和DN原生文档解读
NameNode
1.存储文件元数据,比如目录结构
2.运行NameNode的服务器至关重要,只有1个
3.只对元数据的增删做日志记录,不对block和文件流做记录
4.DataNode故障时,负责创建更多的副本block
HDFS架构
============================================================================================================
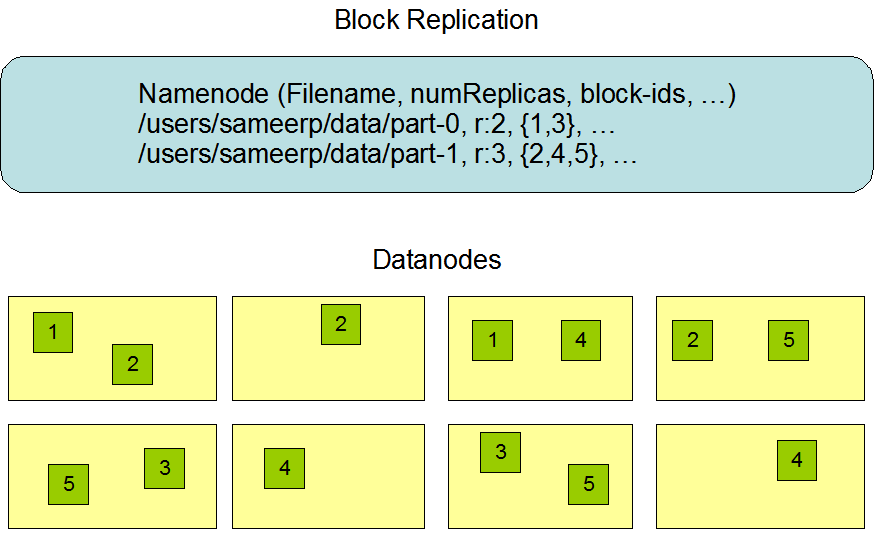
DataNode
1.存储真实数据
2.可运行在多种文件系统上(ext3/4,NTFS...)
3.通知NameNode自己有哪些block
4.NameNode在同一机架创建放置一个副本,另一机架放置2个副本
5.启动脚本分析
HDFS部分
yarn部分















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









