







 Hadoop是Apache的分布式计算框架,包括HDFS和MapReduce。HDFS提供分布式存储,NameNode管理命名空间,DataNode存储数据并定期发送心跳信息。MapReduce则用于大规模数据处理,通过Map和Reduce实现任务分解和结果汇总。Hadoop的设计原则是移动计算而非移动数据,确保高效分布式计算。安装Hadoop涉及配置hadoop-site.xml、hadoop-env.sh等文件,并建立集群间SSH访问。
Hadoop是Apache的分布式计算框架,包括HDFS和MapReduce。HDFS提供分布式存储,NameNode管理命名空间,DataNode存储数据并定期发送心跳信息。MapReduce则用于大规模数据处理,通过Map和Reduce实现任务分解和结果汇总。Hadoop的设计原则是移动计算而非移动数据,确保高效分布式计算。安装Hadoop涉及配置hadoop-site.xml、hadoop-env.sh等文件,并建立集群间SSH访问。
Hadoop是Apache软件基金会所开发的并行计算框架与分布式文件系统。最核心的模块包括Hadoop Common、HDFS与MapReduce。
HDFS
HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。采用Java语言开发,可以部署在多种普通的廉价机器上,以集群处理数量积达到大型主机处理性能。
HDFS 架构原理
HDFS采用master/slave架构。一个HDFS集群包含一个单独的NameNode和多个DataNode。
NameNode作为master服务,它负责管理文件系统的命名空间和客户端对文件的访问。NameNode会保存文件系统的具体信息,包括文件信息、文件被分割成具体block块的信息、以及每一个block块归属的DataNode的信息。对于整个集群来说,HDFS通过NameNode对用户提供了一个单一的命名空间。
DataNode作为slave服务,在集群中可以存在多个。通常每一个DataNode都对应于一个物理节点。DataNode负责管理节点上它们拥有的存储,它将存储划分为多个block块,管理block块信息,同时周期性的将其所有的block块信息发送给NameNode。
下图为HDFS系统架构图,主要有三个角色,Client、NameNode、DataNode。
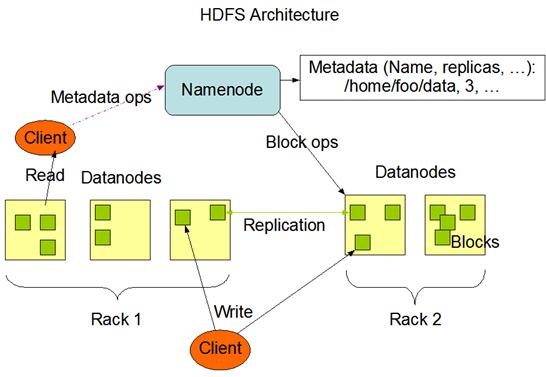
文件写入时:
Client向NameNode发起文件写入的请求。
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
Client将文件划分为多个block块,并根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
当文件读取:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









