







pytorch 网络搭建小结
from pytorch教程
目录
- 帮助工具介绍
- 编辑器选择
- Dateset类
- Tensorboard的使用
- Transform的使用
- 数据集(Dataset和DataLoader
- 神经网络基本骨架nn.Module
- 卷积层
- 池化层
- 非线性层
- 全连接层
- Sequential
- 损失函数
- 优化器
- 现有模型的使用和修改
- 完整的训练
- GPU训练
- demo
- 注意事项
小技巧
-
快捷键:
ctrl+p:函数参数提示 -
其他
(1)读取图片

(2)将文件夹中的图片转换成一个list

(3)reshape()函数 -
用途1:使用reshape()函数使得张量尺寸满足输入参数的要求

(4)将整型tensor转换成浮点型

1. 帮助工具介绍
- dir():返回工具箱内容
- help():顾名思义
dir(torch)
dir(torch.cuda)
help(torch.cuda)
注意:参数没有括号
2. 编辑器选择
- python文件:类似dev c++,每次执行都是从头开始
- python控制台:类似matlab,右侧可以显示变量信息,逐行执行(也可以一段执行,不利于debug)
- jupyter notebook:分块执行
3. Dataset
Dataset类是一个描述数据集的抽象类
- 导入库:
from torch.utils.data import Dataset
class SequentialSampler(Sampler):
def __init__(self, data_source):
self.data_source = data_source
def __getitem__(self):
return iter(range(len(self.data_source)))
def __len__(self):
return len(self.data_source)
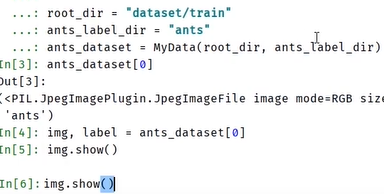
- init():初始化,初始化数据集中的图片路径和标签信息,通常存储在list中
- getitem():参数有一个index,返回list中相对应的元素的图片和标签
- len():返回长度信息
- demo

4. Tensorboard使用
- SummaryWriter类
- 导入库:
from torch.utils.tensorboard import SummaryWriter - 初始化
(1)没有参数情况,默认文件位置
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
(2)有位置参数
writer = SummaryWriter("logs")
# folder location: my_experiment
- writer.add_image():
def add_image(self, tag, img_tensor, global_step=None, walltime=None, dataformats='CHW'):
"""Add image data to summary.
Args:
tag (string): Data identifier 标题
img_tensor (torch.Tensor, numpy.array, or string/blobname): Image data
global_step (int): Global step value to record
walltime (float): Optional override default walltime (time.time())
seconds after epoch of event
实例
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer =SummaryWriter("logs")
image_path=".../16838648_415acd9e3f.jpg" #图片路径
img_PIL = Image.open(image_path)
img_array=np.array(img_PIL) #转化成numpy.array类型
writer.add_image("test",img_array,2,dataformats='HWC')
#需要指定shape中每一维表示的含义
- writer.add_scalar()
def add_scalar(self, tag, scalar_value, global_step=None, walltime=None):
"""Add scalar data to summary.
Args:
tag (string): Data identifier标题
scalar_value (float or string/blobname): Value to save 数值即y轴
global_step (int): Global step value to record 哪一步即x轴
walltime (float): Optional override default walltime (time.time())
with seconds after epoch of event
实例
for i in range(100)
writer.add_scalar("y=2x",2*i,i)
注意,tag参数是log的标识,添加数据之后会对所有数据进行拟合(自我感觉,并不确定)
5. Transform的使用
-
补充知识

关于__call()__

将固定格式的图片转化成需要的格式 -
导入库:
from torchvision import transforms
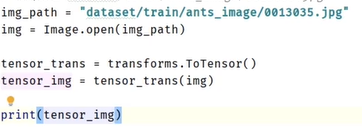
(1)ToTensor()
将图片转化成tensor数据类型

(2)Normalize()归一化 -
计算公式:

-
demo
参数分别是均值和方差(三个通道)

(3)Resize()
输入要是PIL Image

(3)Compose() -
Compose()的参数需要是一个列表,且数据为transforms类型(?什么意思)

(4)RandomCrop()

(5)ToPILImage()

(6)总结
查看官方文档
方法的关注输入输出
初始化__init__函数中的参数没有默认值的需要指定
如果不知道返回值类型可以使用print大法
print()``print(type())``设置断点
6. 数据集(Dataset和DataLoader)
(1)dataset

(1)从网上下载数据集
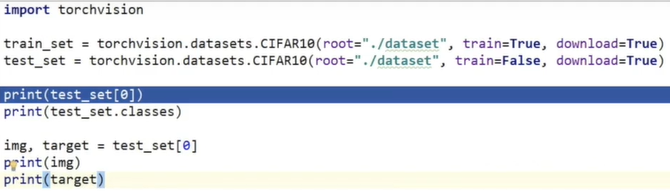

(2)转换成tensor数据类型

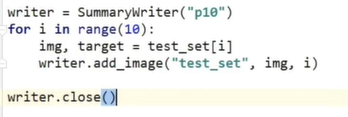
(2)DataLoader
每次从dataset中打包数据成一个个batch,详细参数见官方文档
- dataset中数据


- DataLoader数据


- 使用tensorboard展示

7. 神经网络基本骨架nn.Module
- demo
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
## Define the MLP architecture
class VanillaMLP(nn.Module):
def __init__(self):
super(VanillaMLP, self).__init__()
self.fc1 = nn.Linear(28*28, 256)
self.fc2 = nn.Linear(256,64)
self.fc3 = nn.Linear(64,10)
# implement your codes here
def forward(self, x):
# flatten image input
x = x.view(-1, 28 * 28)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# initialize the MLP
model_1 = VanillaMLP()
loss_fn = nn.CrossEntropyLoss()
optimizer1 = optim.SGD(model_1.parameters(),lr=0.01,momentum=0.9)
8. 卷积层
(1)网络架构


(2)输出shape

output_shape

(3)tensorboard展示

(4)输入输出计算公式

- 小技巧:如果stride=1,padding=(k-1)/2
9. 池化层
说明:
(1)参数cell_model取true时,保留最后一列和最后一行。默认是false
(2)池化层一般只需要设置kernel_size参数
(3)尺寸计算

# pool of square window of size=3, stride=2
m = torch.nn.MaxPool2d(3, stride=2)
output = m(rand_input)
print(output.shape)
# 输出:torch.Size([20, 16, 24, 49])
(4)综合展示demo


10. 非线性层
- 目的:为网络加入一些非线性的特性,使得模型能够拟合非线性的特征(使模型更强大)
- 参数:inplace=true表示是否替换原来的值(默认是false)
inplace=true,原值被替换

inplace=false,原值不变,只有返回值被替换

demo


实例:

11. 全连接层呢
- torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None):全连接层
m = nn.Linear(20, 30)
input = torch.randn(128, 20)
output = m(input)
print(output.size())
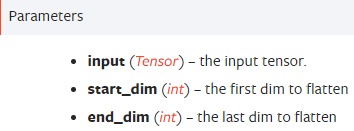
- torch.flatten(input, start_dim=0, end_dim=- 1) :展平,将高维张量展平为一维
t = torch.tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
torch.flatten(t)
torch.flatten(t, start_dim=1)
- demo



12. Sequential
- torch.nn.Sequential(*args):顺序执行sequential中的层/模块。必须确保前一个模块的输出大小和下一个模块的输入大小是一致的
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
- demo:cifar 10 图像分类

(1)不用sequential

- 小技巧:网络搭建好需要检查一下网络的正确性,输入数据检查输出数据的大小是否正确
- 可以用部分网络计算中间层的输出尺寸

(2)使用Sequential
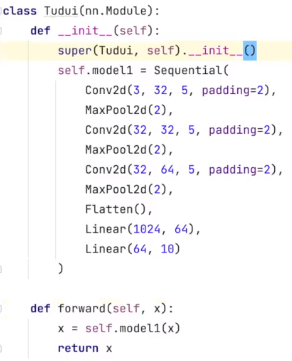
- 查看网络计算图


13. 损失函数
- torch.nn.MSELoss(size_average=None, reduce=None, reduction=‘mean’):平方差损失。取mean为均方差

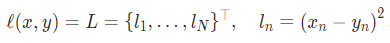
- torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction=‘mean’, label_smoothing=0.0):交叉熵损失。主要用于分类问题的损失计算。

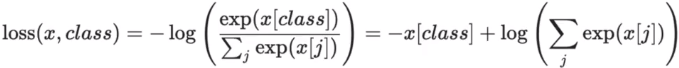
例子:分类问题[0.1,0.2,0.3] -> 1
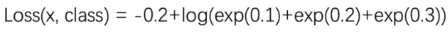
loss(实例).backword()执行之后,参数的梯度才会更新

14. 优化器
(1)构建优化器
- 一定要传需要优化的参数
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
(2)参数优化
for input, target in dataset:
optimizer.zero_grad() #将参数的梯度清零,防止上一次的梯度干扰!!!
output = model(input)
loss = loss_fn(output, target)
loss.backward() #计算/更新梯度
optimizer.step() #根据梯度更新参数
注意:调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加。这样逻辑的好处是,当我们的硬件限制不能使用更大的bachsize时,使用多次计算较小的bachsize的梯度平均值来代替,更方便,坏处当然是每次都要清零梯度。
- demo

15. 现有网络模型的使用和修改
torchvision.models

(1)使用现有模型
import torchvision.models as models
resnet18 = models.resnet18()
alexnet = models.alexnet()
vgg16 = models.vgg16()


…

(2)在模型最后添加一层
model.add_module(moduleName,module )
moduleName参数表示添加模块的名称,类型为string;module是添加的模块(例如可以是nn.Linear()等,也可以是nn.Sequencial()等)


(3)在模型中间某一模块后添加模块

16. 模型的保存与读取
(1)模型保存
- 方式1:
torch.save(model,path)#保存整个模型 - 方式2:
torch.sace(model.state_dict(),path)#保存模型参数

(2)模型读取

- 注意:方式一需要在读取模型的文件中引入模型定义的类
引入定义的文件或者将模型定义的类复制过来

17. 完整的训练
(1)加载数据

(2)模型构建
注意:一般是将模型单独写在一个Python文件中,然后在训练的文件中引入。在main函数中可以测试一下模型是否正确(点main左边的运行箭头)

(最好在同一文件夹下)
(3)实例化模型&损失函数&优化器

(4)网络训练参数

(5)训练和测试
- 为了观察训练的效果,可以在每一轮训练之后测试模型在测试集上的表现,但是要注意测试的代码要放在不更新梯度的环境下(模型训练不能接触到测试数据)
argmax(axis):返回tensor最大值的位置。参数为0表示按列看,为1表示按行看


(6)注意事项model.train():表示为训练状态下,梯度更新。但是只是对一些固定的模块起作用,Dropout, BatchNorm等model.eval():表示为验证状态下,梯度不更新。其他同上- 所以当网络中存在Dropout, BatchNorm层,需要调用上述方法;如果不存在,可以不调用,调用也没有问题
18. 用GPU训练
(1)第一种方式:将模型、数据、损失函数转移到cuda上
【网络模型、数据(输入、标注)、损失函数、.cuda】



(2)指定显卡




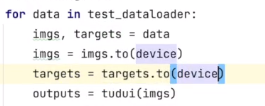
tudui.to(device)
loss_fn.to(device)
data.to(device)
注意:
- 模型和损失函数也可以不用重新复赋值,但是数据(输入和标签)需要。即可以写成:tudui.to(device) loss_fn.to(device)
- 对于单显卡,
torch.device('cuda')和torch.device(cuda:0没有区别 - 更常用的方式:
device = torch.device('cpu' if torch.cuda.is_available() else 'gpu'
19. demo
一般在train.py中训练模型,test.py中将模型应用在具体问题中
(1)读入图像(PIL类型)

(注意:如果是png图像需要将其转换成rgb三个通道(与网络输入一致)image = image.convert('RGB)`)
(2)加载模型


(3)测试

注意:
- 在gpu上训练的模型加载到CPU上测试时需要指定map_location
- 测试记得要将输入图像的size转换成模型输入指定size(batchSize别忘了,训练都是四维的)
- 不要忘了在测试的时候加上
model.eval()和torch.no_grad()
20.开源项目使用注意
- readme中有跟运行程序的相关准备
可以使用命令行运行程序

--dataroot表示参数dataroot,其后./dataset/maps表示参数的赋值,参数的有关信息查找方式如下
(1)训练参数设置
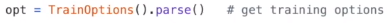
点击TrainOptions()查看参数设置

如果没有找到需要的参数,可以查看继承的父类(这里是BaseOptions)
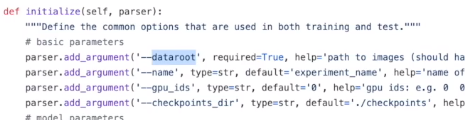
注意:required=True表示运行时需要指定参数值。在具体使用代码时可以将其设置成default=***,这样就不用在命令行中赋值了。
要保证数据集下载正确,路径的正确















 1911
1911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









