







- 发表:2019 ICCV
- idea:对注意力机制的改进。传统的attention中,不管Q和K/V是否相关,都会为Q输出一组归一化的权重,即使二者并不相关,这会产生误导信息。因此作者提出了AoA(Attention on Attention)模块,用于关注Q和V之间的相关性,在传统的attention的基础上再增加另一个attention。
- 代码:AoANet
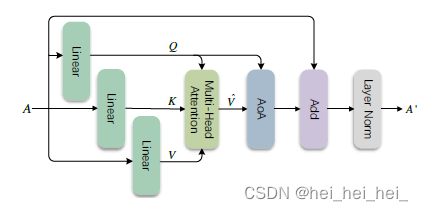
AoA block
用于关注Q和V之间的相关性,通过对Q和V进行线性变化生成information vector
i
i
i和attention gate
g
g
g

使用element-wise multiplication得到attended information
i
^
\widehat i
i
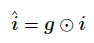
AoA整体计算流程如下:
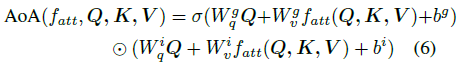

整体架构
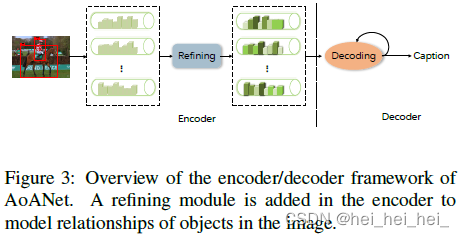
- Encoder
首先通过CNN或R-CNN提取一组初步的特征向量
A
=
a
i
i
=
1
k
A={{a_i}_{i=1}}^k
A=aii=1k,然后将其输入包含AoA模块的网络中,如上所示。这里的AOA模块(
A
o
A
E
{AoA}^E
AoAE)采用了多头注意力
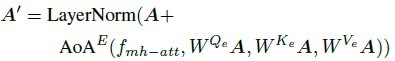
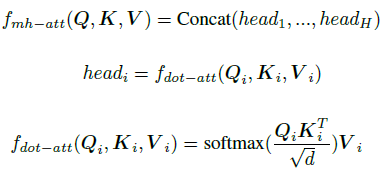
其中
f
m
h
−
a
t
t
f_{mh-att}
fmh−att是多头注意函数,沿通道纬度将Q,K,V分为
H
=
8
H=8
H=8个切片,对每个切片采用scaled dot-product函数
f
d
o
t
−
a
t
t
f_{dot-att}
fdot−att,最后将所有头concate在一起作为最终表达。
此模块可以寻找图像中不同区域的相互作用,并使用AoA进一步关注它们之间的关联程度,最后将
A
←
A
′
A \leftarrow A'
A←A′,该过程并不会改变A的储存,因此可以堆叠操作(论文中堆叠了6次)
- Decoder
使用LSTM进行解码
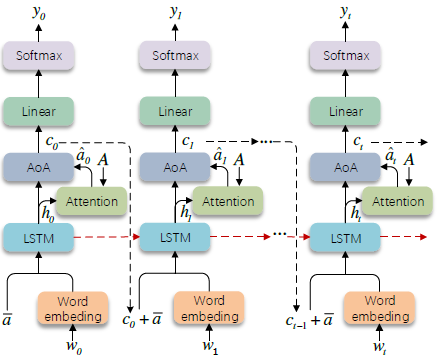
其中
a
‾
\overline{a}
a为A的平均池化;
c
t
−
1
c_{t-1}
ct−1表示context vector,保存了解码状态以及新获取的信息(
c
−
1
c_{-1}
c−1初始化为0向量)
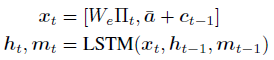
W e ∏ t W_e\prod_{t} We∏t表示输入单词的embedding
- decoder 整体计算公式(
A
o
A
D
{AoA}^D
AoAD)
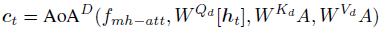















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









