







Controllable Video Captioning with POS Sequence Guidance Based on Gated Fusion Network
概述
- 发表:ICCV 2019
- 代码:Controllable_XGating
- idea:提出用POS信息指导caption生成;提出特征融合网络用于对多模态特征进行融合。
详细设计
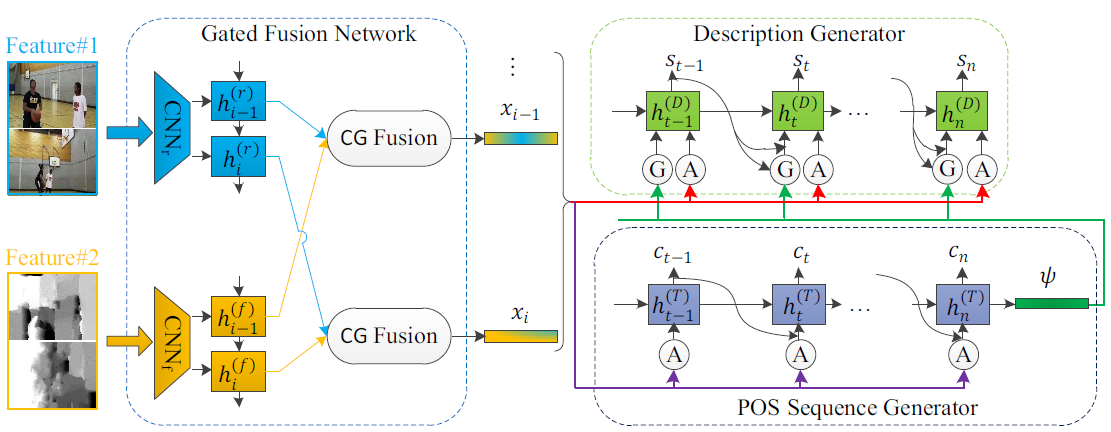
Ⓖ表示本文提出的cross gating mechanism,Ⓐ表示soft attention
- Gated Fusion Network:对两种特征使用CG模块进行融合得到融合后的特征x;
- POS sequence Generator:x输入LSTM+soft attention得到POS信息;
- Description Generator:最后将POS information和x一起输入两层的LSTM进行解码生成word
1. Gated Fusion Network
使用训练好的网络提取视频的content features和motion features,然后分别经过LSTM进行特征的聚合(时间纬度上),最后是通过一个CG模块完成特征的融合。
- LSTM编码提取好的特征
经过CNNs提取的context features R = { r 1 , r 2 , . . . , r m } R = \{r_1, r_2,...,r_m\} R={r1,r2,...,rm}, motion features F = { f 1 , f 2 , . . . , f m } F = \{f_1, f_2,...,f_m\} F={f1,f2,...,fm}
这一阶段结束后得到high-level content and motion features:(所有step的隐层)
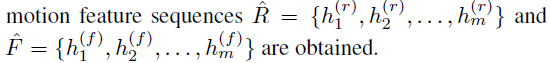
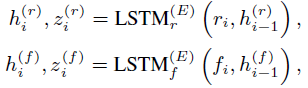
- Cross Gating
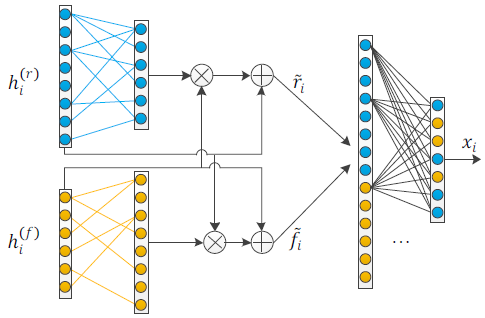
这里的 ⨁ 和 ⨂ \bigoplus 和 \bigotimes ⨁和⨂分别表示element-wise 的相加和相乘
公式解释:
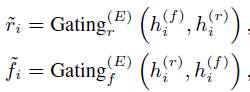
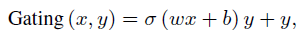
然后concate之后接上一个全连接层,得到最终融合后的特征 X = { x 1 , x 2 , . . . , x m } X = \{x_1, x_2,...,x_m\} X={x1,x2,...,xm},
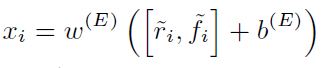
2. POS Sequence Generator
依旧是LSTM+soft attention生成 POS sequence
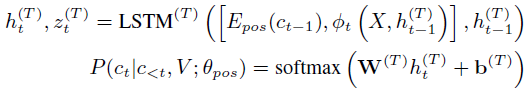
c
t
−
1
c_{t-1}
ct−1表示上一step预测的POS tag,
E
p
o
s
E_{pos}
Epos为 POS tag embedding matrix;
ϕ
t
\phi_t
ϕt表示soft attention
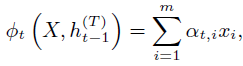
最后一个step的hidden state
ψ
=
h
n
(
T
)
\psi = h_n^{(T)}
ψ=hn(T)包含了全局的POS信息,会被用于指导句子生成
3. Description Generator
将POS tag与上一步生成的word embedding进行交叉融合
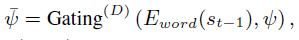
将
X
,
ψ
ˉ
X,\bar{\psi}
X,ψˉ输入两层的LSTM
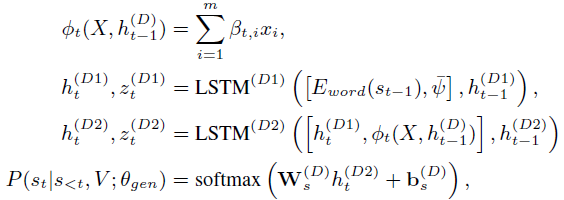
4. Training
首先训练POS sequence generator,这时将description generator的参数冻结
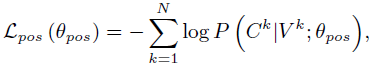
当POS sequence generator收敛之后再训练description generator
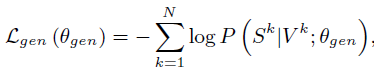
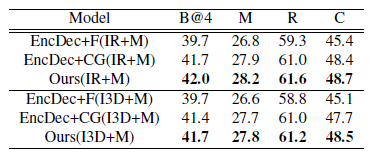
实验
-
Ablation Studies
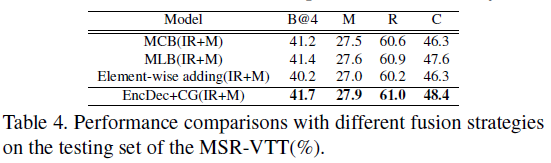
不同的fusion strategies
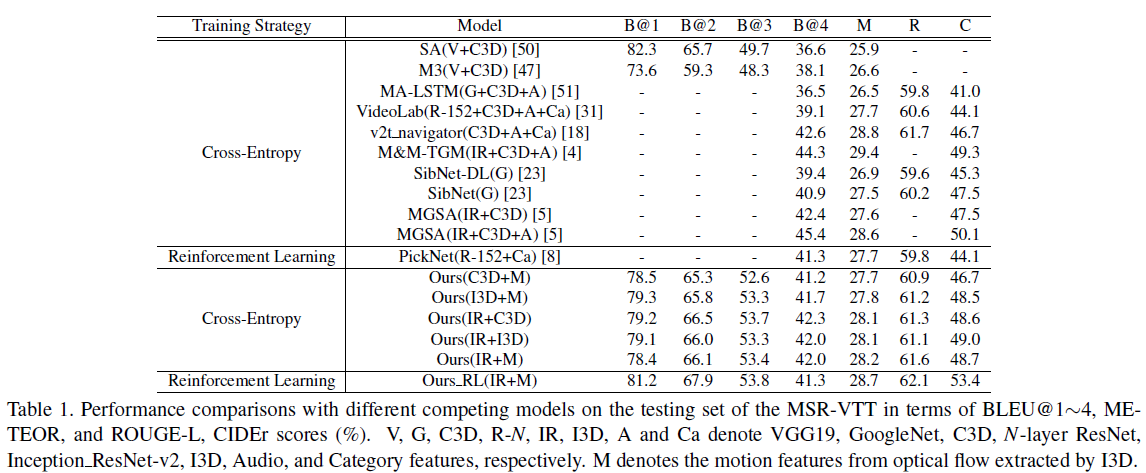
-
Comparison studies














 2796
2796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









